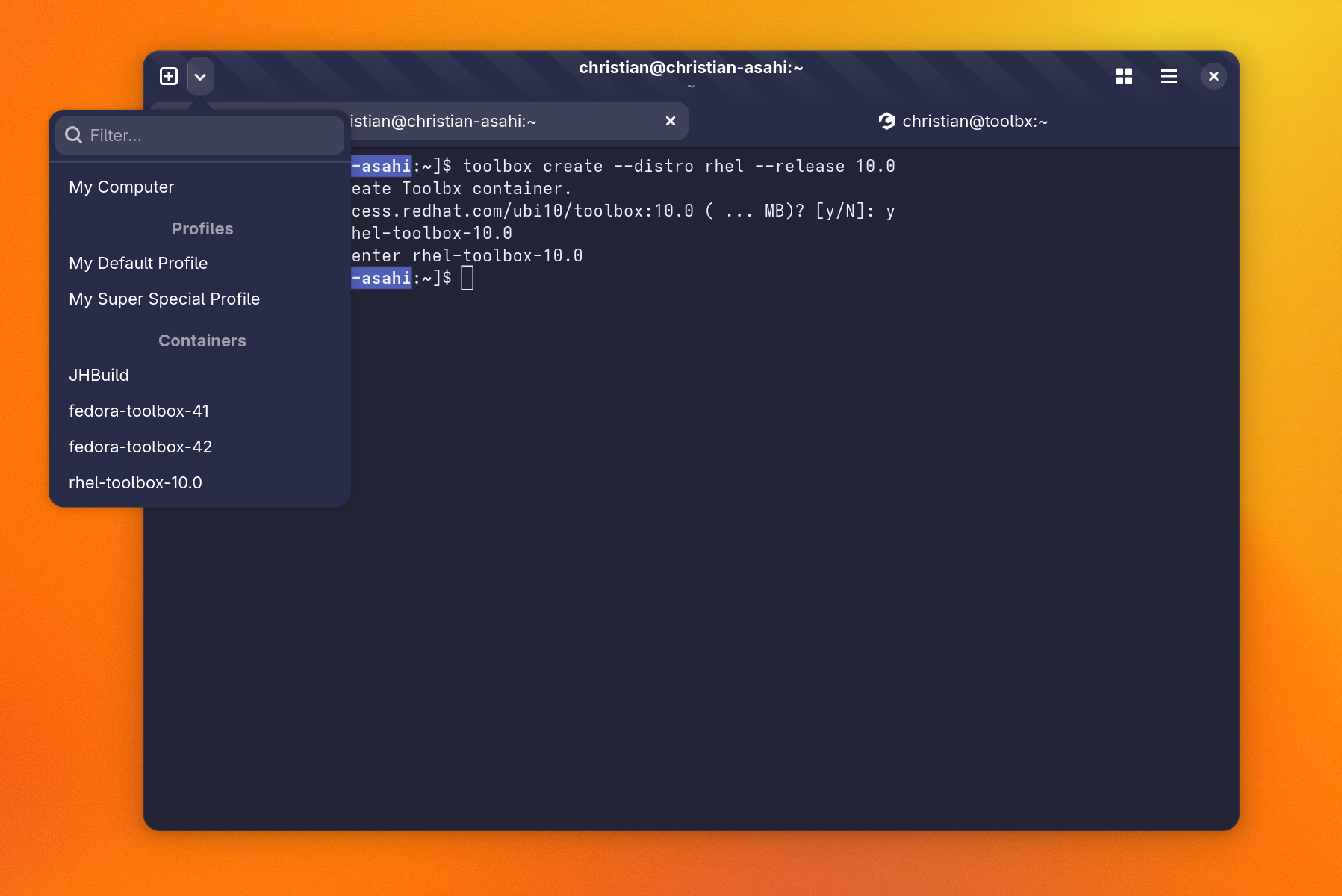
I know that I will never convince everyone to use Builder for development. Even I have a hard time getting myself out of the terminal at times.
Foundry comes in two forms, an executable and a library. The executable is just a bunch of commands and libfoundry is meant for building your own IDE (like Builder) or specialized tooling.
# initialize .foundry directory if never done before
cd my-project/
foundry init
If you go into most GNOME applications, they likely have a Flatpak manifest. Builder uses this to auto-discover a lot about a project. Foundry is no different.
# Build the project, just like Builder would do
foundry build
You can run this from any directory in your project as it will scan upwards to locate the .foundry/ directory that contains project state. It will also do incremental building just like Builder does.
# Run the project, just like Builder would do
foundry run
# Run a specific command in place of the default program.
# Useful to test something with "runtime" instead of
# build environment.
foundry run -- gtk4-demo
Running the project will setup the necessary incremental flatpak pipelines and auxiliary tooling like an a11y bus, font integration, and what not. Your application will be run in the Flatpak build container based on the finish-args.
This does require building the application to ensure the runtime environment is setup correctly.
# Pull updated project dependencies.
foundry dependencies update
Updating your deps is pretty painless. This is not done automatically unless the dependency is missing so that we don’t have to constantly hammer remote servers on every build request.
# Run a shell in the build pipeline, launches in builddir
foundry devenv
# Run a specific command in build pipeline
foundry devenv -- ps aux
You can get a terminal shell in the build pipeline (much like ctrl+alt+shift+t in Builder.
# Lots of commands to inspect the build pipeline
foundry pipeline info
# Alias to foundry build
foundry pipeline build
# Invalidate all pipeline stages
foundry pipeline invalidate
# Purge (remove build files/artifacts/etc) to force
# a clean build
foundry pipeline purge
# clean, configure, export, rebuild, which, install
# all provide additional pipeline operations
You can interact with the active build pipeline using the above commands.
Sometimes you might want to know what compiler flags will get used with tooling on a specific file. That is made available via the pipeline as well.
foundry pipeline flags path/to/file.c
Maybe you need a language server for integrating with another editor. That is pretty easy to do for the supported languages by using the lsp command.
$ foundry lsp list
Name Languages
zls 'zig'
vhdl-language-server 'vhdl'
vala-language-server 'vala' 'genie'
ts-language-server 'js' 'jsx' 'typescript' 'typescript-jsx'
sourcekit-lsp 'swift'
serve-d 'd'
rust-analyzer 'rust'
ruff 'python3' 'python'
pylsp 'python3' 'python'
mesonlsp 'meson'
lua-language-server 'lua'
jedi-language-server 'python'
jdtls 'java'
intelephense 'php'
gopls 'go'
glsl-language-server 'glsl'
elixir-ls 'elixir'
clangd 'c' 'cpp' 'chdr' 'cpphdr' 'objc'
blueprint 'blueprint'
bash-language-server 'sh'
# use stdin/stdout to communicate with an LSP for python3
$ foundry lsp run python3
If you have multiple project configurations, you can look through them and select the active one. Just switch configs and run, Foundry will do the rest.
foundry config list
...
foundry config switch flatpak:app.devsuite.Manuals.Devel.json
foundry run
Want to get a .flatpak you can copy to another system to test?
foundry export
...
Artifacts:
file:///.../apps.devsuite.Manuals.Devel.flatpak
You can switch devices in case you have deviced running somewhere like a phone or tablet. Then running should deploy to that system and run it there.
foundry device list
...
foundry device switch some_device
foundry run
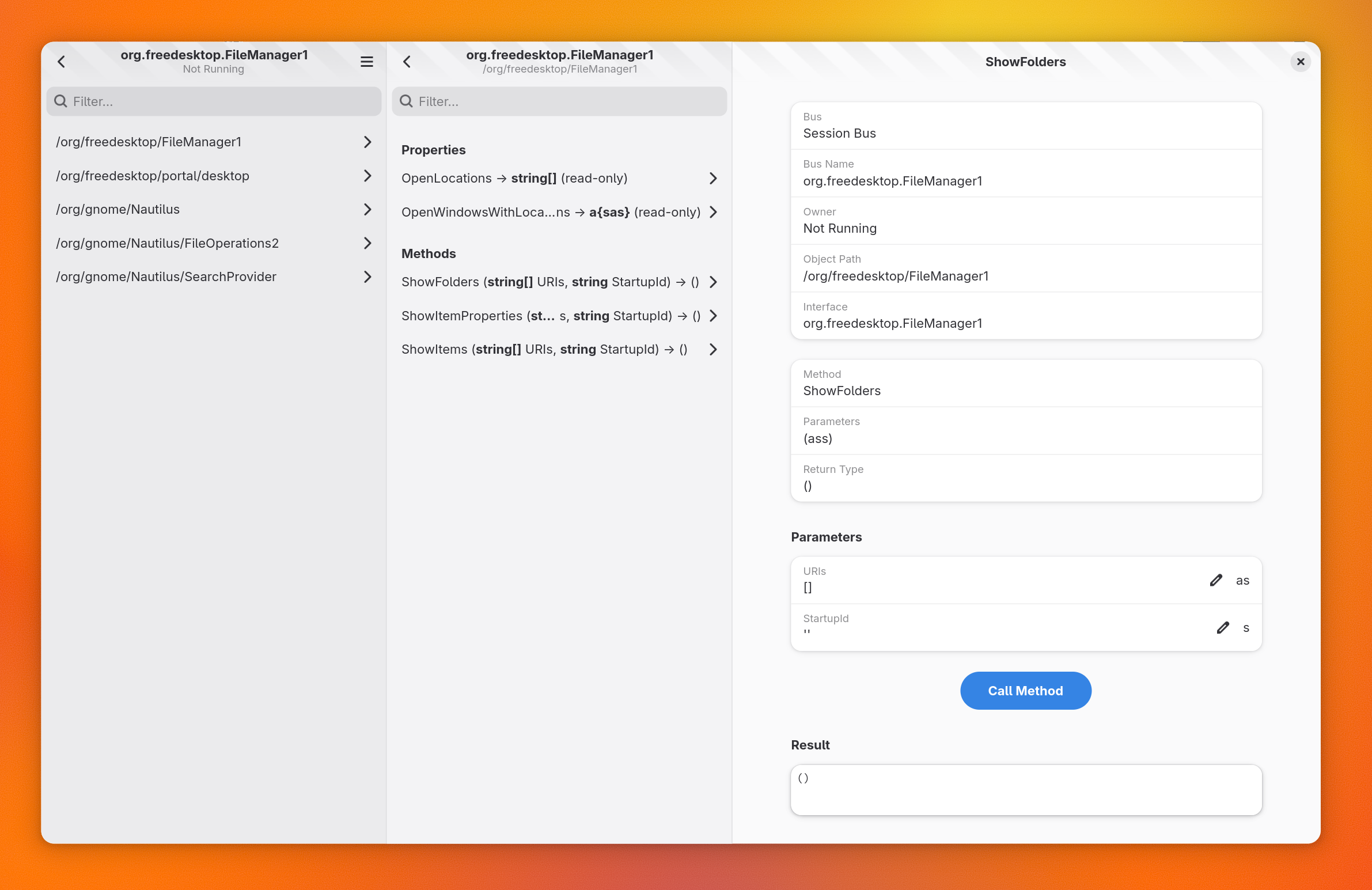
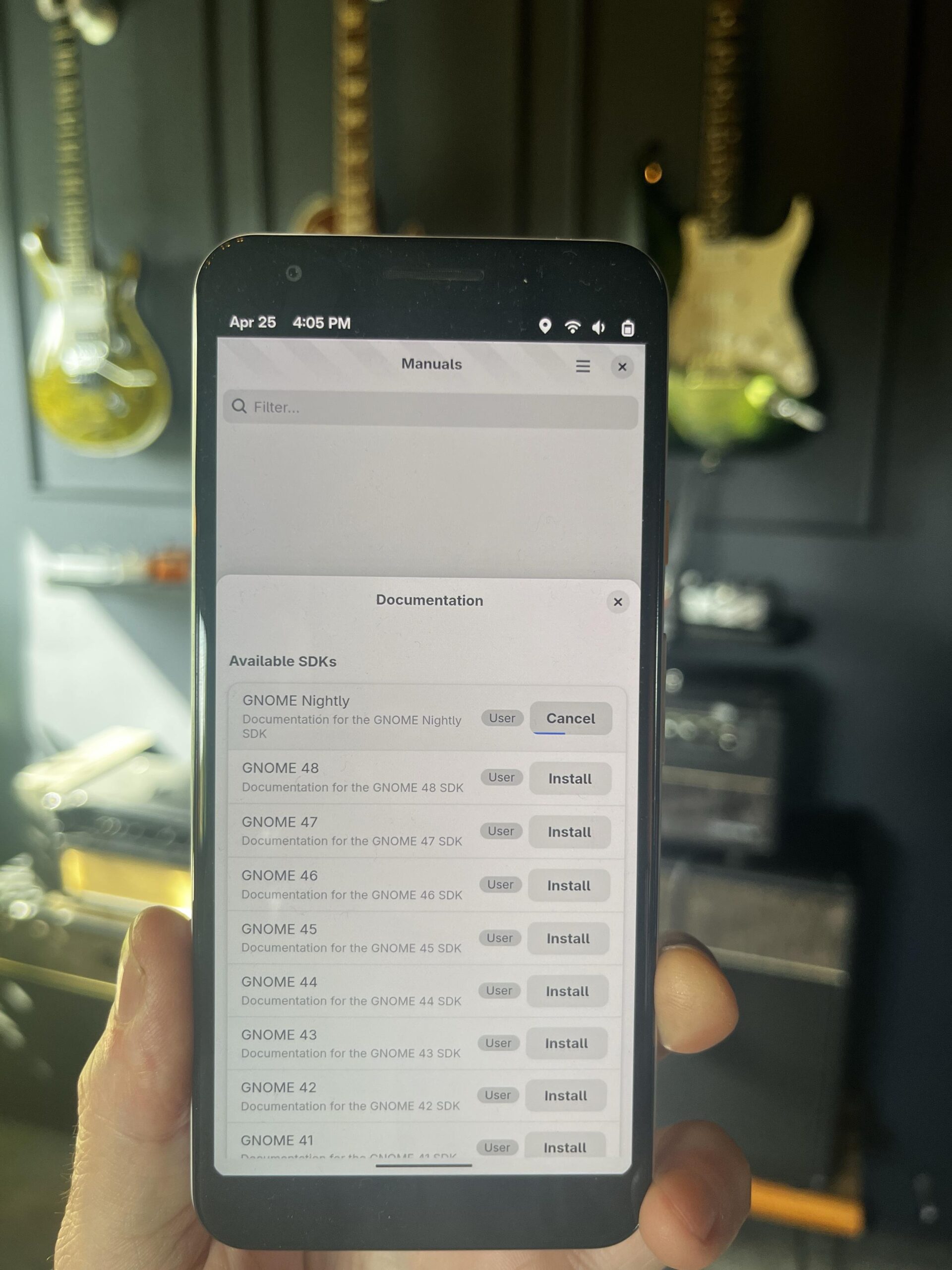
You can get the URI to documentation which could allow you to integrate with other editors. Like many commands, you can use --format=json to get the output in an easy-to-parse format for editor plugins.
# list available doc bundles to install
foundry doc bundle list
...
# install docs for GNOME 48
foundry doc bundle install flatpak/org.gnome.Sdk.Docs/48/user
# Find GtkWidget documentation
foundry doc query --format=json GtkWidget
Many settings can be tweaked using foundry settings set .... Just tab-complete around to explore.
Anyway, hopefully that serves as a quick intro into some of the things you can do with Foundry already as it progresses towards being a fully-fledged replacement for Builder’s internals.