Visualizers are almost ready to land. This week I got smooth scrolling, zoom, and selections working. The handy part about selections is that it allows you to update the callgraph to limit stack samples to those falling within a given time range.
Category: Sysprof
Sysprof Plans for 3.24
The 3.24 cycle is just getting started, and I have a few plans for Sysprof to give us a more polished profiling experience in Builder. The details can be found on the mailing list.
In particular, I’d love to land support for visualizers. I expect this to happen soon, since there is just a little bit more to work through to make that viable. This will enable us to get a more holistic view of performance and allow us to drill into callgraphs during a certain problematic period of the profile.
Once we have visualizer support, we can start doing really cool things like extracting GPU counters, gdk/clutter frame-clock timing, dbus/cpu/network monitors and whatever else you come up with.
Additionally we have some work to do around getting access to symbols when we are running in binary stripped environments. This means we can upload a stripped binary to your IoT/low-power device to profile, but have the instruction-pointer-to-symbol resolver happen on the developers workstation.
As I just alluded to, I’d love to see remote profiling happen too. There is some plumbing that needs to occur here, but in general it shouldn’t be terribly complicated.
Builder Nightly Flatpak
First off, I’ll be in Portland at the first ever LAS giving demos and starting on Builder features for 3.24.
For a while now, you’ve been able to get Builder from the gnome-apps-nightly Flatpak repository. Until now, it had a few things that made it difficult to use. We care a whole lot about making our tooling available via Flatpak because it is going to allow us to get new code into users hands quicker, safer, and more stable.
So over the last couple of weeks I’ve dug in and really started polishing things up. A few patches in Flatpak, a few patches in Builder, and a few patches in Sysprof start getting us towards something refreshing.
Python Jedi should be working now. So you can autocomplete in Python (including GObject Introspection) to your hearts delight.
Jhbuild from within the Flatpak works quite well now. So if you have a jhbuild environment on your host, you can use the Flatpak nightly and still target your jhbuild setup.
One of the tricks to being a module maintainer is getting other people to do your work. Thankfully the magnificent Patrick Griffis came to the rescue and got polkit building inside of Flatpak. Combined with some additional Sysprof patches, we have a profiler that can run from Flatpak.
Another pain point was that the terminal was inside of a pid/mount/network namespace different than that of the host. This meant that /usr/lib was actually from the Flatpak runtime, not your system /usr/lib. This has been fixed using one of the new developer features in Flatpak.
Flatpak now supports executing programs on the host (a sandbox breakout) for applications that are marked as developer tools. For those of you building your own Flatpaks, this requires --allow=devel when running the flatpak build-finish command. Of course, one could expect UI/UX flows to make this known to the user so that it doesn’t get abused for nefarious purposes.
Now that we have access to execute a command on the host using the HostCommand method of the org.freedesktop.Flatpak.Development interface, we can piggy back to execute our shell.
The typical pty dance, performed in our program.
[code lang=”c”]
/* error handling excluded */
int master_fd = vte_pty_get_fd (pty);
grantpt (master_fd);
unlockpt (master_fd);
char *name = ptsname (master_fd);
int pty_fd = open (name, O_RDWR, 0);
[/code]
Then when executing the HostCommand method we simply pass pty_fd as a mapping to stdin (0), stdout (1), and stderr (2).
On the Flatpak side, it will check if any of these file-descriptors are a tty (with the convenient isatty() function. If so, it performs the necessary ioctl() to make our spawned process the controller of the pty. Lovely!
So now we have a terminal, whose process is running on the host, using a pty from inside our Flatpak.
Sysprof + Builder
After the GNOME 3.20 cycle completed I started revamping Sysprof. More here, here, and here. The development went so smoothly that I did a 3.20 release a couple of weeks later.
A primary motivation of that work was rebuilding Sysprof into a set of libraries for building new tools. In particular, I wanted to integrate Sysprof with Builder as our profiler of choice.
On my flight back from GUADEC I laid the groundwork to integrate these two projects. As of Builder 3.21.90 (released yesterday) you can now profile your project quite easily. There are more corner cases we need to handle but I consider those incremental bugs now.
Some of our upcoming work will be to integrate the Sysprof data collectors with Python and Gjs. The Gjs implementation is written, it just needs polish and integration with upstream. I think it will be fantastic once we have a compelling profiling story weather you are writing C, C++, Vala, Python, or Gjs.
We’ve also expanded the architectures supported by Sysprof. So I expect by time 3.22 is released, Sysprof will support POWER8, ARM, ARM64, mips, and various others as long as you have an up to date Linux kernel. That is an important part of our future plans to support remote profiling (possibly over USB or TCP). If you’re interested in working on this, contact me! The plumbing is there, we just need someone with time and ambition to lead the charge.
How to Sysprof
So now that a new Sysprof release is shipped, lets pick on an unsuspecting library to see what it is like to improve performance in a real-world scenario. Today we’ll pick on GtkSourceView. They shouldn’t feel bad though, GtkSourceView is an absolutely wonderful library and like any piece of software, it can be improved.
GtkSourceView has a lovely helper program to test things out in the tests/ directory. If you are an app or library developer, please do this! It makes things much easier.
So lets run ./test-widget in our jhbuild environment, and start-up Sysprof. Often times, you’ll want to see how your program affects the whole system. But for this test, I want to focus on test-widget, so we will limit our capture to samples in that process. Do this by turning off the Profile my entire system switch and then selecting your target process from the list.
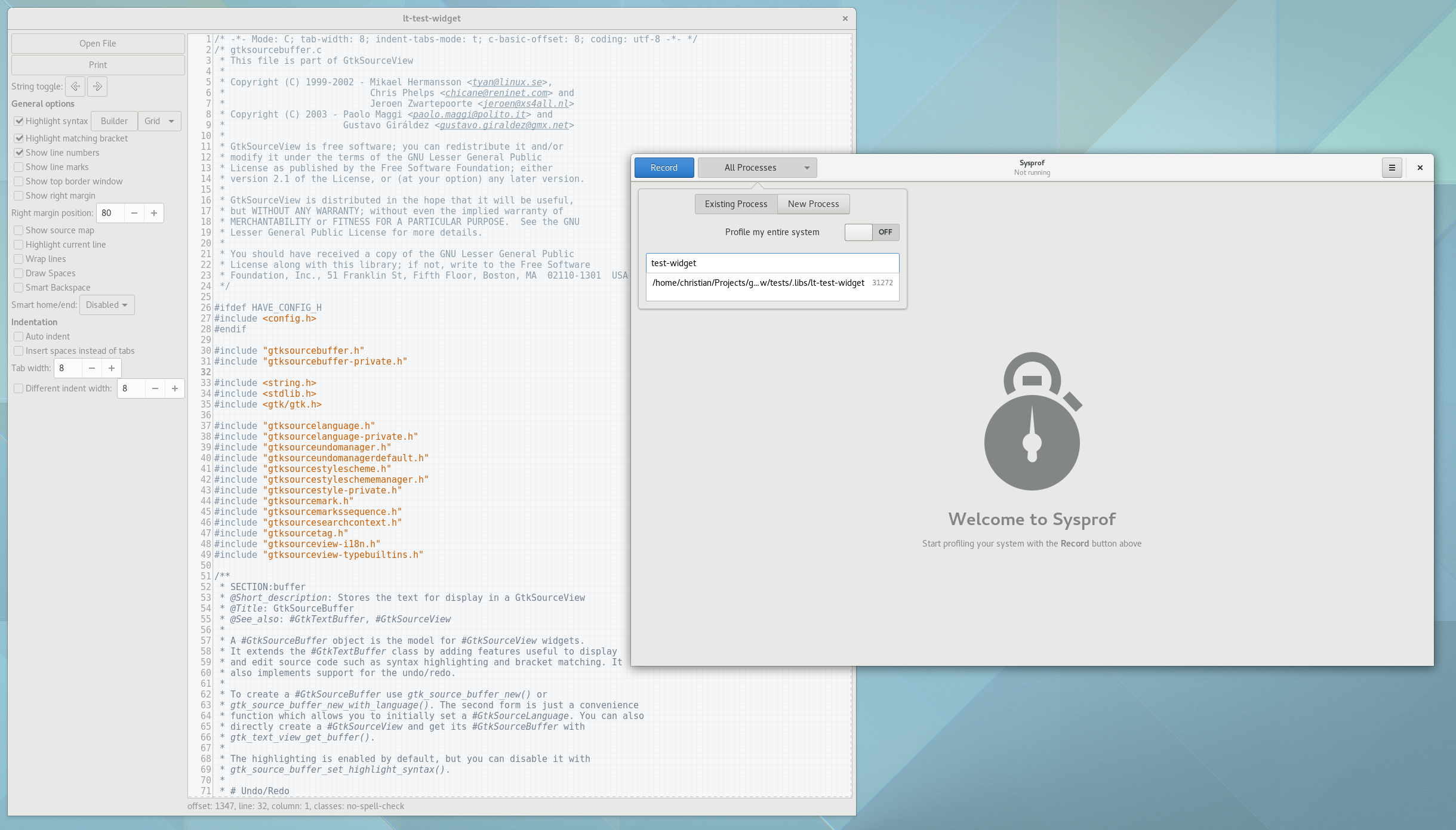
Next, click record. You might be prompted to authorize your user to access performance counters based on your system configuration and user permissions.
After your profiling session has started, switch back to the test application and exercise the crap out of it. In this case, I turned on some features in the test widget like line numbers (something I always have enabled in Gedit and Builder) and started scrolling like crazy. I did this until I had about 30,000 samples recorded. Sysprof will tell you how many callchains have been recorded in the upper right corner of the window.
Then press the Stop button. Depending on the size of your capture, it might take a couple seconds, but the callgraph will then be generated. It has to crack open all of the linked libraries and extract symbol information from them, so it can take a second or two.
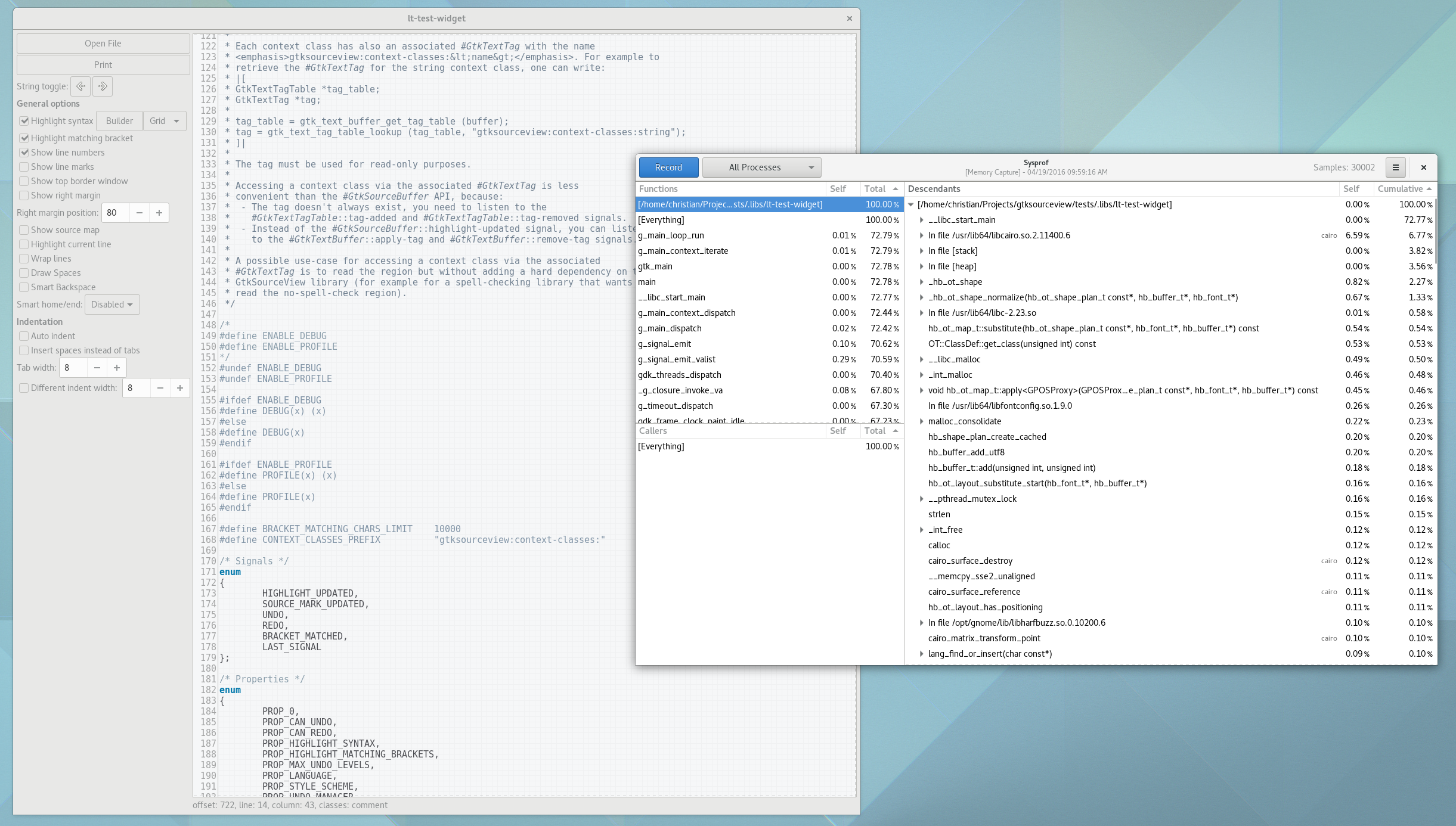
Now the mysterious part. Start diving into the descendants tree following the most expensive cumulative times. We want to find something that looks “out of place”. Getting good at that takes practice. If your callchain gets too deep, just hit enter on the row and it will focus in on that item.
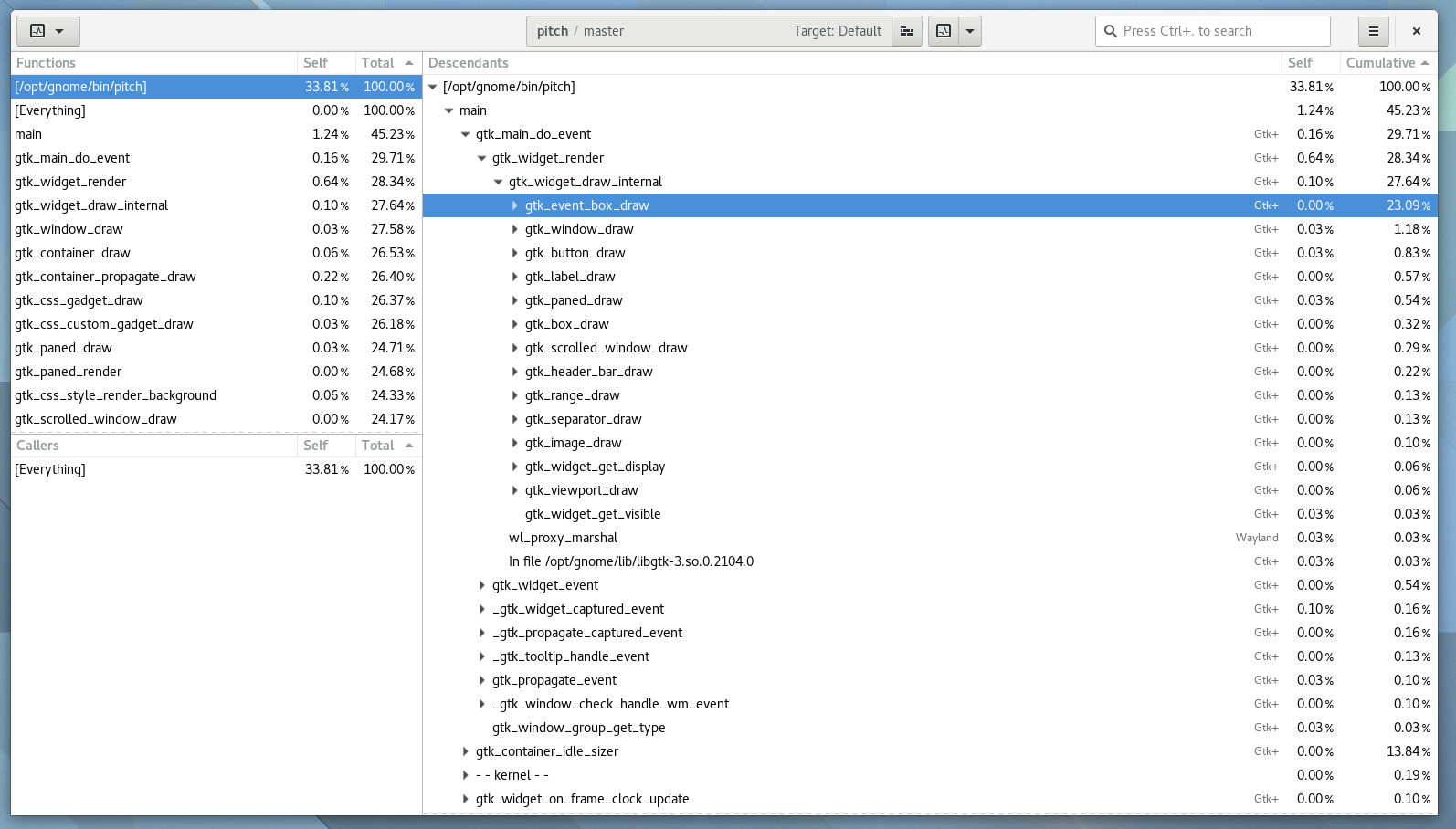
In the image below, you’ll see I jumped past main, various main loop junk until i got to gtk_main_do_event(). This is the crux of event dispatch in GTK+. If we keep diving down by the most expensive callchain, we get to a peculiar function, center_on(). It seems to be calling into gtk_text_view_get_iter_location() a bunch, I wonder why.

So lets go find the code. It is clearly called by GtkSourceGutterRendererText, so that is where we will start.
In the code below, it looks like the text gutter renderer (what draws line numbers next to your code) needs to either place the text in the middle of the row, the top of the row (in the case of line wrapping), or the bottom of the row (also in case of line wrapping).
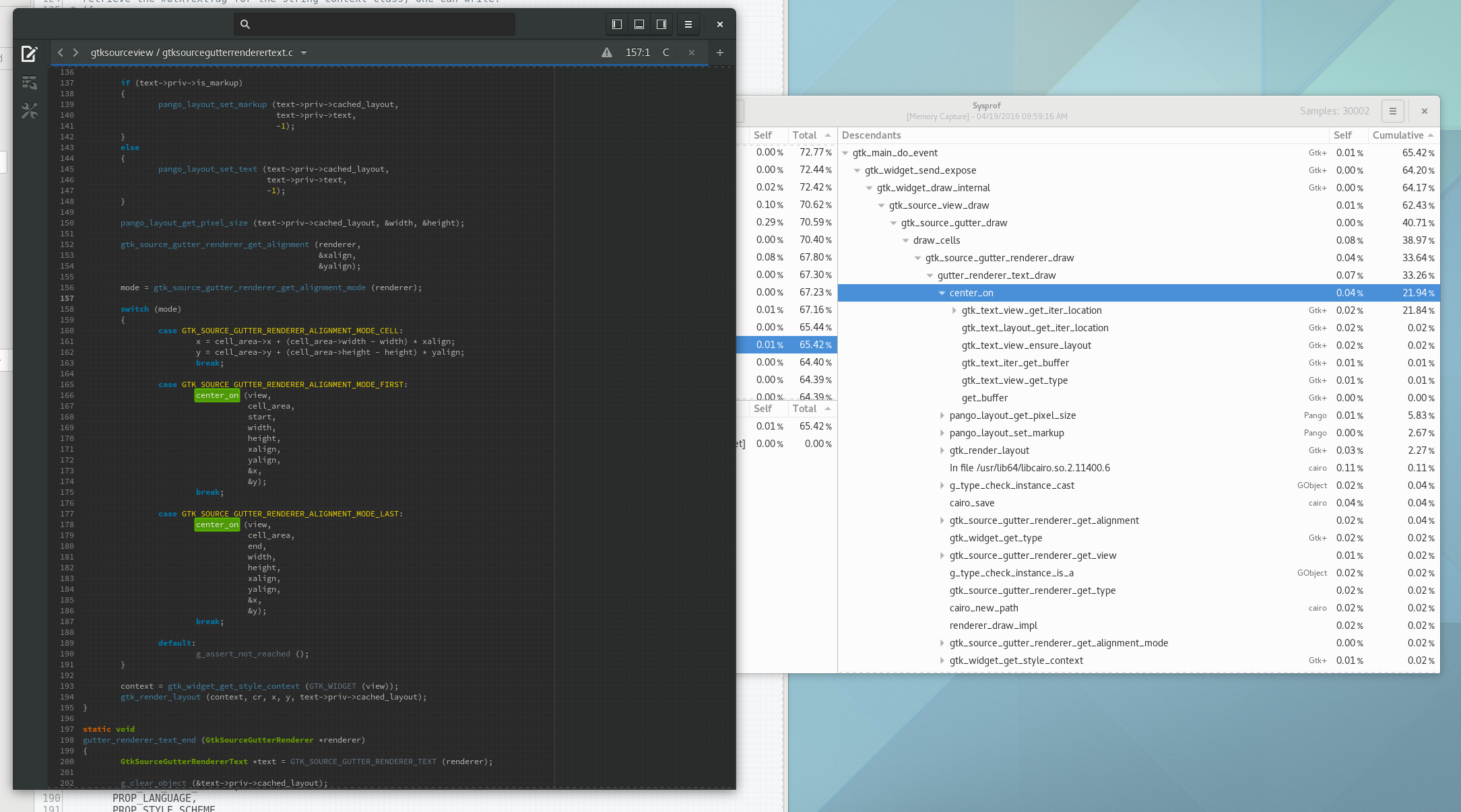
In Builder, shamefully, we don’t even allow line wrapping today. So clearly a shortcut can be taken. If wrapping is disabled, we know that we will always be centering our text to the entire height of the cell. So lets cook up a quick patch to avoid the center_on() calls altogether.
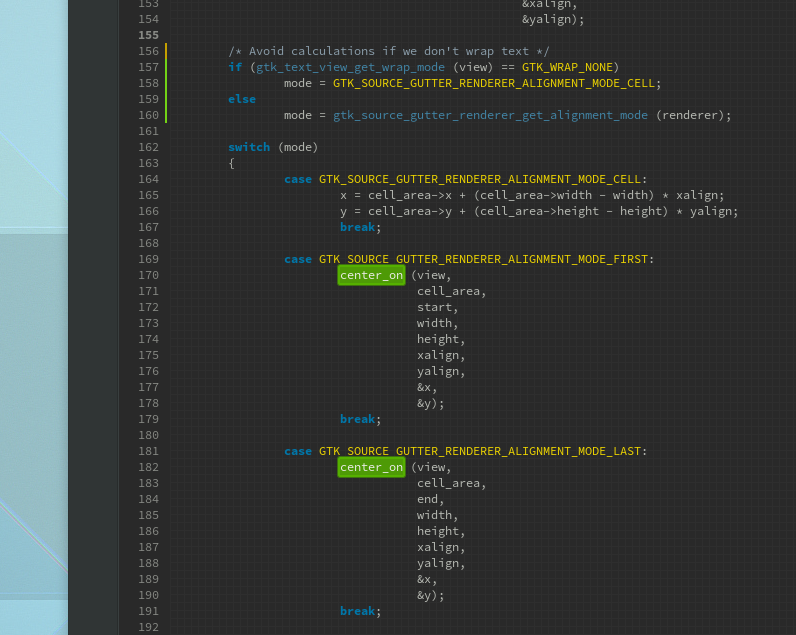
Now we build, and repeat our profiling session to compare the results. Originally the gutter_renderer_text_draw() was in about 33% of our collected callchains. Now, if you look below we are down to less than 20% of our collected callchains, and center_on() is nowhere to be seen!
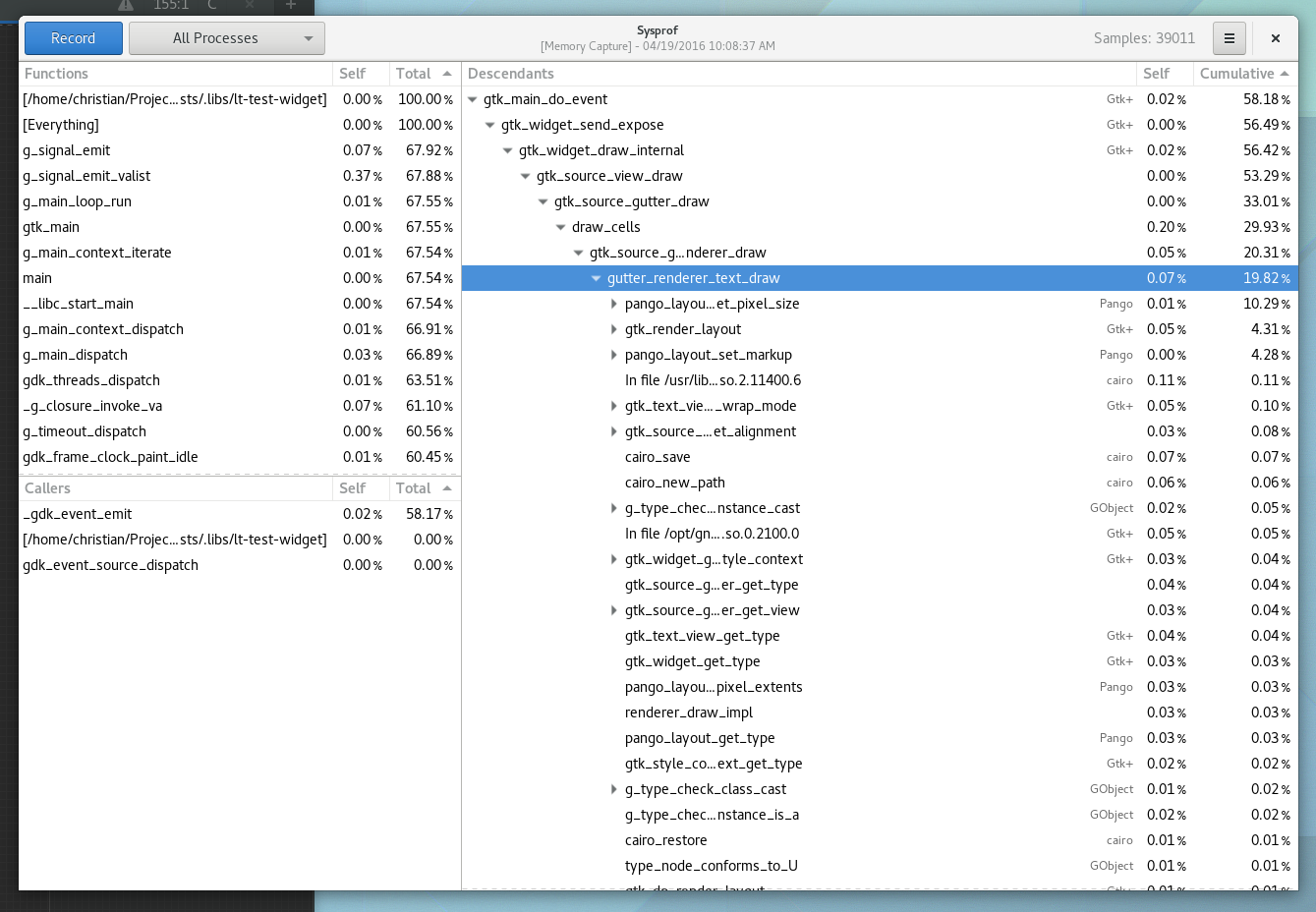
So the moral of the story is that in about half an hour, you can profile, learn something about a code-base, and make measurable improvements. So go ye forth and make the F in Free Software stand for Fast.
Designing APIs for multiple languages
Designing software that is both fast and available to higher level languages generally means you end up writing C. There are guiding principles you should follow when doing so to ensure that you give your software the best chance for success.
Design Failures
Lets start with a look into my past. When I was employed at MongoDB a few years back, I was tasked with writing the modern, fast, C client library. The secondary goal was to speed up the other drivers that used bits of C “for performance reasons”. However, the performance gain from the C components was a meager 1-2x faster than just implementing it in the higher-level language. This is what happens when we fail to see the big picture, which is the first step in understanding.
The cost of a thunk in and out of the language runtime is reasonably fast these days. But when you do lots of them they quickly add up. (A thunk is simply a wrapper around calling another function that possibly has setup/teardown and possibly marshaling to perform).
In the example above, the reason for the meager gains in performance from C was simple. It was encoding/decoding each individual BSON document by calling into C (and then back up into python, ruby, etc) rather than as a set. Imagine if you get a result from the server containing 1000 documents. In this case you’d cross the language barrier at least 1000 times. Now what if while decoding those documents you have to create structures that are owned by the language runtime (calling back into the runtime to allocate). Now your 1000 could have just turned into 3000 at best, and more likely, many times worse.
However, if you simply dive into C once to decode the whole stream, you cut a large number of thunks out of the equation. If instead you move the whole database client, socket handling, encryption, etc into C, you can avoid even more thunks. This is why wrapping the libmongoc C library in python was closer to 10-15x faster than the native python version compared to the meager 1-2x faster with per-document decoding.
By maximizing the time you are in C, you give yourself the largest potential for performance improvement. Where you draw your language boundary is equally important to the data-structures you choose.
GObject
We use GObject across the board in GNOME. And for a living piece of software that is nearly old enough to drink, that is a good thing. Like all type systems designed in the 1990s, it has some warts. But generally, it gets the job done and provides the inter-language features we want with very little effort.
But you need to be careful when designing APIs if you intend for them to be accessible from multiple languages. For example, if your API relies on gsignal (what other languages often call “events”), you should at least think about the costs.
For example, imagine that the callback connected to your signal is in python. Your C code knows nothing of python and therefore likely does not hold the GIL (global interpreter lock). That means that when your signal fires, and it tries to thunk to the python callback, it must first marshal parameters (possibly copying), and then acquire the python GIL (generally fine). Now imagine you do this many times per second because your design emits signal everywhere (GtkWidget, for example). Now all of a sudden you are entering/exiting the language barrier many times in rapid succession. The thunks add up.
A very similar but equally important thing is the use of main loop timeouts. In GLib-based code, we generally use some form of g_idle_add_full() that registers a new GSource. First off, for every one of these we have to wake up the main loop, mutate data structures, detect level-triggered poll events, and possibly destroy it at the end of the main loop cycle (for one-shot sources). And that doesn’t even include the callback into your language runtime. Now imagine you do this on every frame of an animation. Now imagine that for every frame of the animation you update multiple actors in your scene graph. All of a sudden your thunk costs went through the roof, and you haven’t done any actual work yet.
Designing for success
So, how do we design APIs that don’t suffer from these issues? Well first off, really consider whether the use of gsignal is beneficial.
- Avoid gsignal when simply a single callback function will suffice. gsignal synchronizes all emissions via the global lock used to locate signal information. Obviously we can optimize this, but I’m not sure it changes anything.
- Design APIs that can be setup from dynamic languages, but execute purely from C. For example, create your animation structure from JavaScript or Python, but the tweener itself should not involve thunks back into dynamic languages. See EggAnimation as an example.
- If you find yourself calling into C functions in a tight loop, stop and think about what you are doing.
Sysprof 3.20.0
Previously, previously, previously, and previously.
The past couple of weeks went by so fast working on Sysprof that I think we can actually release it as a (late) 3.20 application. We don’t have many translations, but on the other hand, we didn’t have any before.
There is so much we could do with Sysprof going forward, but I’ve got an IDE to write. If some of you are interested in working on the application, I can push you in the right direction. I have some visualization prototypes and ideas for more data collectors. I’d love to hand that off to newcomer(s) who are proficient in C and as nuts as I am about performance.
GNOME Shell Profiling
Now that we have a Gjs profiler we can start looking at doing some fun things with it.
Today I wrote a couple line patch to GNOME Shell to toggle on and off the profiler using SIGUSR2. So if you build Gjs and gnome-shell with the appropriate patches, you can do something like:
[code lang=”shell”]
gnome-shell –wayland
# .. inside shell
kill -SIGUSR2 <pid>
# .. exercise shell a bit
kill -SIGUSR2 <pid>
# .. now look at /tmp/gjs-profile-$pid
[/code]
If you open that file up with my Sysprof improvements, you can browse around the profile information containing JavaScript stacks.
It looks something like this.

Happy bug hunting!
A profiler of our own
So now that you are all aware that I’ve been working to modernize Sysprof, you might not be surprised to read that I decided to push things in a bit more interesting of a direction.
I have a very opinionated stance on languages. Which is, in general, they’re all terrible. Only to be made more terrible by their implementations. Which is to say, we’re all screwed and how do these computers work anyway?
But alas, succumbing to the numbness of existence is not how I want to spend my life, so time to pull up my figurative bootstraps and improve what we’ve got.
So what’s in my cross-hairs this week? Well, quite frankly, those JavaScripts. I’ve worked on a handful of language runtimes, but modern JavaScript engines really take the cake for turning a Von Neumann machine into something completely foreign and utterly non-debuggable, non-profile-able, generally unpleasant for anyone to come in and improve things other than the original author. (Same could be said about C. But wait, I said I *wasn’t* succumbing to the numbness).
Well, that isn’t completely true, given that you only write JavaScript within the context of a browser. The tooling in browsers these days is rapidly approaching something useful. Which is saying a lot when you have a language that is almost exclusively using nameless functions attached to prototype fields.
So here we go, off into the land of mystery. libmozjs24 is our path, with only headers and a few sources to guide us.
So how do profilers work anyway?
Lets simplify this to a static C-like language for the moment.
Say your program is happily running along, maybe processing things from a main loop. Along comes a signal from the kernel. The kernel decides it will deliver the signal to your main thread (see man pthread_sigmask for information on how signals are delivered and how to block them). What happens next is that on top of your current executing stack, your registered signal handler (see man sigaction) is executed.
At this point, you can do a couple of things. Generally, you might use something like libunwind to unwind the stack (past your signal handler) and record each of the instruction pointers for each frame. Using that, you can later look at what library was mapped into the region containing the instruction pointer, and resolve the function name by reading the library ELF (and possibly demangling if it is a C++ function).
If you remember your UNIX handbook, the way to spawn a process (simplified) is to fork(), followed by an exec() of the new process. So how do we get our signal handler into that process?
POSIX timers
In the 2008 version of POSIX, timers were introduced (See man timer_create for more information). They allow you to deliver a signal on an registered interval. Even better, POSIX timers follow through exec but not fork. Exactly what we want. We can fork(), setup the timer, and then exec() our target.
It looks something like this:
[code lang=”c”]
struct sigevent sev = { 0 };
sev.sigev_signo = SIGPROF; /* Send us SIGPROF */
sev.sigev_notify = SIGEV_THREAD_ID; /* Linux extension! */
sev._sigev_un._tid = syscall (__NR_gettid); /* See man gettid */
timer_create (CLOCK_MONOTONIC, &sev, &timer);
[/code]
The above code creates a timer that we can enable/disable to deliver SIGPROF on a given interval. Note that the above code uses a Linux extension that allows you to specify the thread to receive the signal. Without something like that, you would need to either create a thread to use pthread_kill() to send SIGPROF, or mask SIGPROF from all other threads, lest they receive the signal handler instead of your target thread.
So why is the thread that the profiler runs on important? We’ll get to that later when we start looking at JITd languages.
To activate the timer, we setup our interval (frequency) to sample.
[code lang=”c”]
struct itimerspec its = { 0 };
its.it_interval.tv_sec = 0;
its.it_interval.tv_nsec = NSEC_PER_SEC / SAMPLES_PER_SEC;
its.it_value.tv_sec = 0;
its.it_value.tv_nsec = NSEC_PER_SEC / SAMPLES_PER_SEC;
timer_settime (self->timer, 0, &its, &old_its);
[/code]
Extracting Samples
Now say we used sigaction(2) to setup a signal handler for SIGPROF. And now it is being called via signal delivery of SIGPROF. Our stack might look something like:
[code lang=”c”]
our_sigprof_handler()
< signal handler invoked >
some_worker()
main_loop_dispatch()
main_loop_iterate()
main()
[/code]
We can unwind to get to the root of the stack, stash each of those addresses somewhere, and then return from our signal handler (allowing the program to continue executing).
However, the devils in the details there. We are in a signal handler, which basically means, you can’t do much, safely. Why? Well avoiding deadlocks mostly.
Say that SIGPROF got delivered while you were in malloc()? It might look something like:
[code lang=”c”]
our_sigprof_handler()
< signal handler invoked >
do_alloc()
_int_lock()
malloc()
some_worker()
main_loop_dispatch()
main_loop_iterate()
main()
[/code]
Now, if you try to call malloc(), you’ll deadlock on _int_lock(). Basically, the only thing you can do is write to some memory you have pre-allocated. Buffer space, if you will.
Thankfully, you can do one more thing, which is write() to a file-descriptor. That is handy in case our buffer gets too full.
But you need to be very careful here. Even things like g_assert() could potentially cause a printf() or similar which might internally malloc. So you might need to -DG_DISABLE_ASSERT for production (which you should be doing anyway).
The complexities of a JIT
JITs truly are the magic of our times. They are the meta of the computer to improve itself faster than we can. That said, like your smart friends, they can be super annoying.
Discussing what a JIT is, the added complexity of tracing JITs, and their almost always pairing with garbage collection is out of scope for this. However, there are some excellent implementations you can go read (See mono as one such example of quality engineering).
In this case, the meaning of an address (the function in question, to say) could be the same between two samples, but be part of two completely different functions. Suppose that the JIT regenerated and reused the existing memory.
If you simply went by the address and did not account for the change, then you’d get wildly inaccurate results.
How SPSProfiler comes to the rescue
Thankfully, this work was building on top of SPSProfiler from libmozjs. While we have to provide our own sampler (which we’ve described the basics of above), it provides the necessary JIT integration in a moderately fast manner.
js::ProfileEntry
What mozjs gives us is a way to ask the runtime to deliver the current JS stack into a static buffer that we can read from. Each time JS dives into or out of a function, that “shadow stack” is updated.
However, since libmozjs has a garbage collector, if we were to access this stack information from any other thread, we’d be racing the GCing of strings pointed to by that shadow stack. So we need to ensure we interrupt the executing stack (hence SIGPROF, timers, etc).
Racing with a GC doesn’t matter in a C like language because, well there is no GC, and we can resolve symbol names after the fact because of ELF and DWARF debug information.
[code lang=”c”]
volatile uint32_t stack_depth = 0;
js::ProfileEntry stack[1024];
js::SetRuntimeProfilingStack (js_runtime,
stack,
&stack_depth,
G_N_ELEMENTS (stack));
js::EnableRuntimeProfilingStack (self->runtime, true);
[/code]
Deduplicating Functions
To get the function name for JavaScript functions, we can simply read the string pointed to by the js::ProfileEntry. Something like:
[code lang=”c”]
if (entry->js()) {
const gchar *name = entry->label() ?: "– javascript –"
}
[/code]
Now, if we had to copy that string for every instruction pointer in the stack, on every sample, we’d have pretty significant overhead in our profiler. So we do a bit of a deduplication hack. We have something that looks like a chunked allocator (GStringChunk) except it can’t be an allocator, because oh wait, in a signal handler.
So instead, we just have a fixed buffer size to store a single instance of the string, and a closed hashtable (no allocations required) to help with our deduplication.
While we fill the deduplicated function buffer, we hand out monotonic address identifiers for each new string. We steal some high bits in the address to indicate that this is a JITd function. (0xE << __wordsize-8). Normally this would colide with kernel addresses, but not in practice.
So now we can just replace our JITd addresses with these and store them like we would normally for C-like stacks.
What’s missing?
While SPSProfiler will put JS information (including native code) for functions before the current JavaScript frame, it doesn’t seem to give info after the current JS frame. So if your JS code calls into C code, which doesn’t result in a callback back into JavaScript code, getting reliable stack addresses is non-trivial. Maybe I’m missing something here though.
I need to go read some more code, because I’m likely to believe there is a way to deal with this, but might require newer libmozjs. Anyway, future blog post and all.
Capture formats
My new sysprof implementation uses a new binary capture format I’ve put together. Basically something really simple that lets me get data into the buffer quickly without too much fuss, alignment safe (allowing dereference of integers from the buffer with out use of memcpy()) and without the super annoying reality of Linux’s perf event stream which has dynamic trailing data based on what options were enabled when sampling. Seriously, don’t do that.
I still have some things to add, but this is the first step towards making more interesting captures (like in-app performance counters, VBlank information, compositor FPS, GTK+ frame timings, etc).
So what does that even mean?
Well, I guess you can see for yourself. Here is a simple capture I did to pick on GNOME documents (no reason really, just the first JavaScript/C hybrid app that came to mind) showing Sysprof reading our JavaScript profiler output.
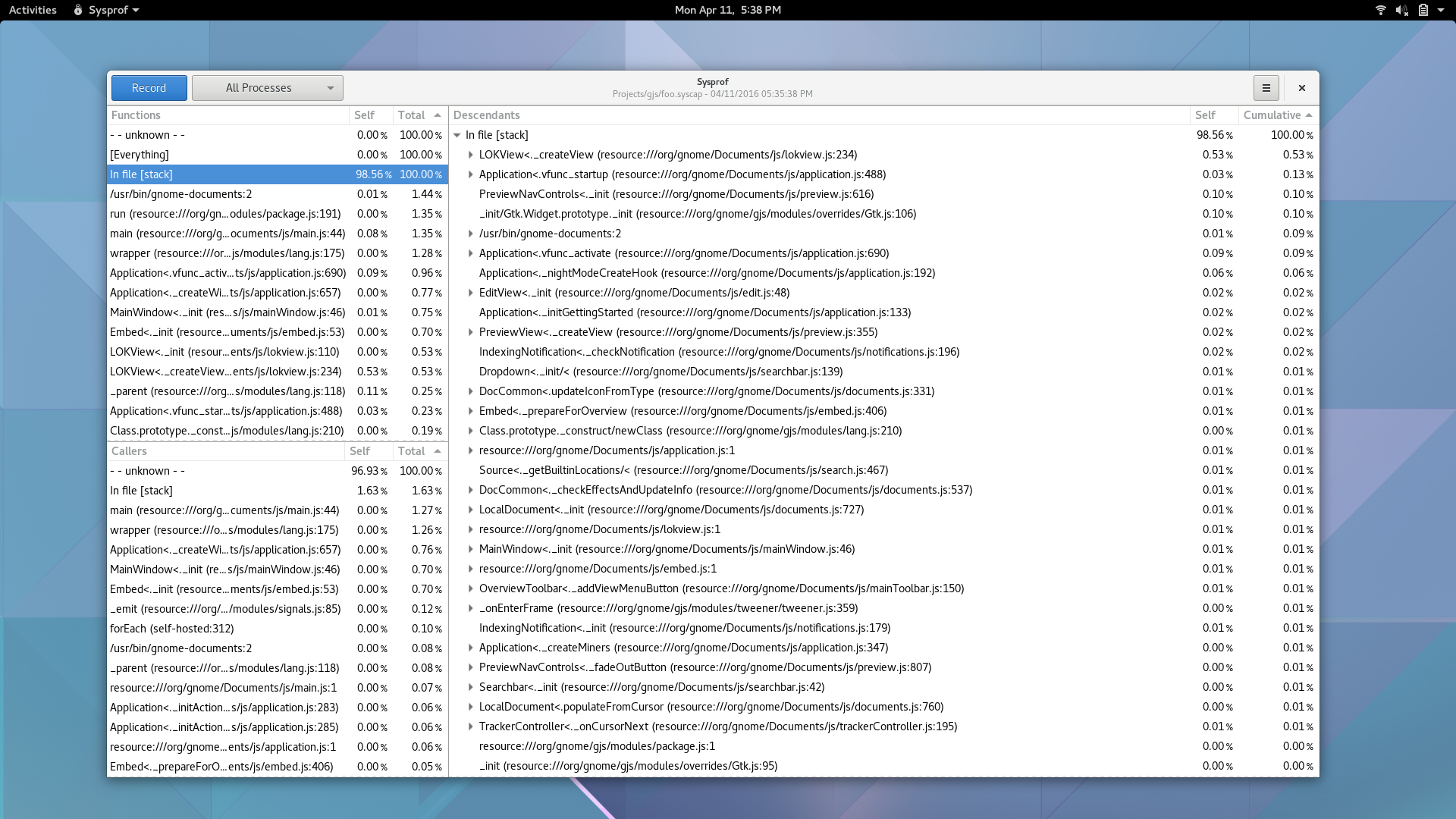
There is still some work to be done. I need to get the Gjs patches in a format suitable for inclusion. That means fixing up some boring signal handler code to be more safe. Ray Strode has already provided some good feedback here.
Additionally, I need to get my sysprof2 repository grafted into upstream Sysprof. This week I swear. We also need to get patches into some programs that use libgjs directly without the use of gjs-console so that they too can be profiled. gnome-shell is the obvious culprit here.
Come hack on Sysprof with me? Please?
If any of this interests you, I’d love to have some people come help work on modernizing Sysprof into something we all love. It’s still missing one thing I loved while working on PerfKit years ago. Pretty graphs and charts of runtime information. We can start sampling cpu, memory, network, kms/drm information, and more. With that data available, we can build some pretty compelling tooling for GNOME and GNU/Linux in general. (BSDs obviously too, but today Sysprof is Linux only due to the Linux kernel integration).
No doubt, there are gaps and missing information in this blog post. It’s hard to capture all the details after you do the work. For the nitty-gritty details, best to go look at the code.
- https://github.com/chergert/sysprof2
- https://github.com/chergert/gjs
- Build/install the code above.
- gjs-console --profile-output=foo.syscap /usr/bin/gnome-documents
- You might need to let it exit gracefully, I don’t have periodic sample flushes implemented yet.
- sysprof foo.capture
- Explore!
Thanks to Red Hat for letting me dive head first into this. They really are the best employer I’ve ever had.
JavaScript (Gjs) Profiling
So this happened…

Everything is still sort of a work-in-progress, but soon I expect to have patches for all the right people in all the right places. There is a lot of slight-of-hand going on here, so it’s worth taking some time to get the details documented.