GWeather
Last time I wrote we talked about a new search index for libgweather. In the end I decided to take another route so that we can improve application performance without any changes. Instead, I added a kdtree to do nearest neighbor search when deserializing GWeatherLocation. That code path was looking for the nearest city from a latitude/longitude in degrees.
The merge request indexes some 10,000 lat/lon points in radians at startup into a kd-tree. When deserializing it can find nearest city without the need for a linear scan. Maybe this is enough to allow significantly more data into the database someday so my small hometown can be represented.
Nautilus
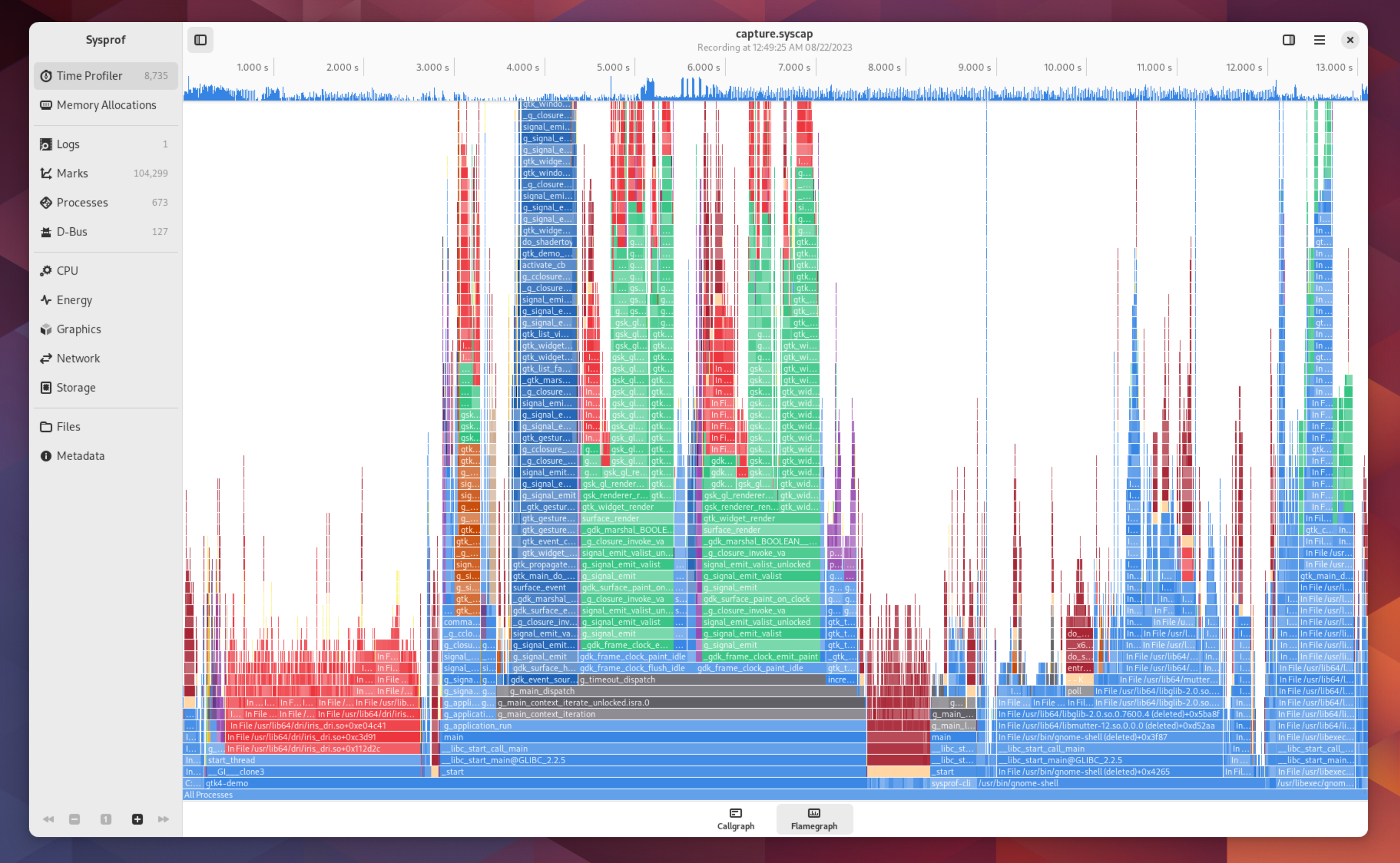
I found a peculiarity in that I was seeing a lot of gtk_init() calls while profiling search. That means processes are being spawned. Since I have D-Bus session capture in Sysprof now, I was able to find this being caused by Nautilus sending an org.freedesktop.DBus.Peer.Ping() RPC to kgx and gnome-disks.
Seems like a reasonable way to find out if a program exists, but it does result in those applications being spawned. gtk_init() can take about 2% CPU alone and combined this is now 4-5% that is unnecessary. Nautilus itself needing to initialize GTK on startup plus these two as a casualty puts us combined over 6%.
D-Bus has an org.freedesktop.DBus.ListActivatableNames() RPC which will tell you what names are activatable. Same outcome, less work.
Corey, like a great maintainer, has already jumped into action.
Photos
I was hesitant to look at gnome-photos because I think it’s falling out of core this next cycle. But since it’s on my system now, I want to take a look.
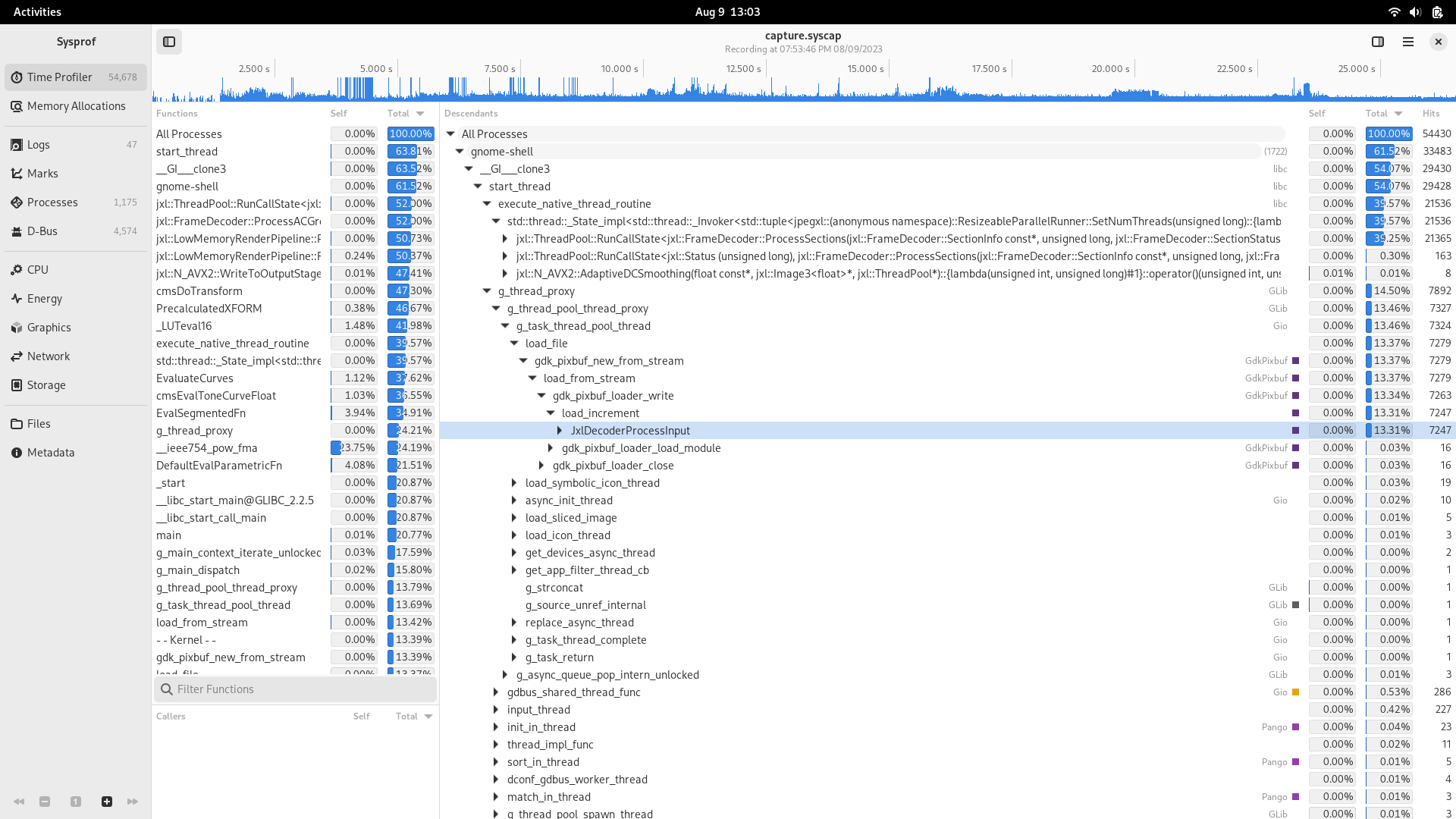
First off, I was seeing about 10 instances of gnome-photos in a single Sysprof capture. That means that the process was spawned 10 times in response to search queries. In other words, it either must have crashed or exited after each search request I typed into GNOME Shell. Thankfully, it was the later. But since we know gtk_init() alone is about 2%, and combined this looks like it’s in the 30-40% range there must be more to it.
So, easy fix. Call g_application_set_inactivity_timeout() with something reasonable. The search provider was already doing the right thing in calling g_application_hold() and g_application_release() to extend the process lifetime. But without inactivity-timeout set, it doesn’t help much.
After that, we’re down to just one instance. Cool.
Next capture we see we’re still at a few percent, which means something beyond just gtk_init() is getting called. Looks like it’s spending a bunch of time in gegl_init(). Surely we don’t need GEGL to provide search results (which come from tracker anyway), so make a quick patch to defer that until the first window is created. That generally won’t happen when just doing Shell queries, so it disappears from profiles now.
Calculator
Rarely do I have gnome-calculator actually running when performing a Shell search despite using it a lot. That means it too needs to be spawned to perform the search.
It’s already doing the right thing in having a dedicated gnome-calculator-search-provider binary that is separate from the application (so you can reduce start-up time and memory usage) so why is it showing up on profiles? Looks like it’s initializing GTK even though that isn’t used at all in providing search results. Probably a vestige of yesteryear.
Easy fix by just removing gtk_init(). Save time connecting to the display server, setting up seats, icon themes, and most importantly, parsing unused CSS.
Another couple percent saved.
Measure, Measure, Measure
Anyway, in conclusion, I might leave you with this tidbit. Nobody gets code right on the first try, especially me. If you don’t take a look and observe it, my guess is that it looks a lot different at run-time than it does in your head.
Sysprof is my attempt to make that a painless process.