It can be very handy to store things you might do as meta programming in your GObjectClass‘s private data (See G_TYPE_CLASS_GET_PRIVATE()).
Doing so is perfectly fine, but you need to be aware of how GTypeInstance initialization works. Each of your parent classes instance init functions are called before your subclasses instance init (and in order of the type hierarchy). What might seem non-obvious though is that the GTypeInstance.g_class pointer is updated as each successive _init() function is called.
That means if you have my_widget_init() and your parent class is GtkWidget, the gtk_widget_init() does not know it’s instantiating a subclass. Further more, GTK_WIDGET_GET_CLASS() called from gtk_widget_init() will get you the base classes GtkWidgetClass, not the subclasses GtkWidgetClass.
There are ways around this if you don’t use G_DEFINE_TYPE(), but honestly, who wants to do that.
One technique around this, which I used in Bonsai’s DAO, is to use a single-linked list where the head is in each subclass, but the tail exists in each of the parent classes. That way you share all the parent structures, but the subclasses can access all of theirs. You’ll still want to defer most setup work until constructed() though so you can get the full class information of the subclass and hierarchy.
In the previous article of this series we covered Sysprof basics to help you use the tooling. Now I want to take a moment to show you how to use the command line tooling to profile systems like GNOME Shell.
Record an existing session
The easiest way to get started is to record your existing GNOME Shell session. With sysprof-cli, you can use the --gnome-shell option and it will attempt to connect to your active GNOME Shell instance over D-Bus to stream COGL pipeline information over a private file-descriptor.
This information can be combined with callgraphs to see what is happening during the duration of a COGL mark.
The details page can also provide some quick overview information about the marks and their duration. You will find this helpful when comparing patches to see if they really improved things over time.
The details button in the top right will show you information about marks and their min/max/avg duration.
Basic Shell Recording
Running something like a desktop session is complex. You have a D-Bus daemon, a compositor, series of background daemons, settings infrastructure, and programs saving to your home directory. For this reason you cannot really run two of them for the same user at the same time, or even nested.
Because of this, it is handy to log out of your desktop session and switch to a VT to profile GNOME Shell. Sysprof provides a sysprof-cli binary you can use to profile in complicated setups like this.
Start by switching to another VT like Control+Shift+3. I recommend stopping the current display server just so that it doesn’t get in the way of profiling, but usually it’s okay to not. Then we can enter our JHBuild environment with a new D-Bus session before we start Sysprof and GNOME Shell.
At this point, we can spawn GNOME Shell with Sysprof to start recording.
You can use -- to specify the command you want sysprof-cli to execute while it records. When that application exits, sysprof-cli will extract all the known symbols and finish it’s recording.
I want to mention briefly that the --gnome-shell option only works with an existing GNOME session. I hope to fix that in the near future though.
At this point, GNOME Shell will have spawned and you can exercise it to exhibit the behavior you’d like to improve. When done, open a terminal window to kill GNOME shell so that the profiler can clean up.
kill -9 $(pidof gnome-shell) seems to work well for me
Now you’ll have a capture.syscap file in your current directory. Open that up with Sysprof to view the contents of your profiling session. Often I just spawn gnome-shell directly to open the syscap file and explore.
Recording JavaScript stacks
Sometimes you want to profile JavaScript instead of the C code from Shell, Mutter, and friends. To do this, use the --gjs command line option. Currently, this can give mixed results if you also sample callstacks with the Linux perf support, as the timings are not guaranteed to be equivalent. My recommendation is to disable perf when sampling JavaScript using the --no-perf option.
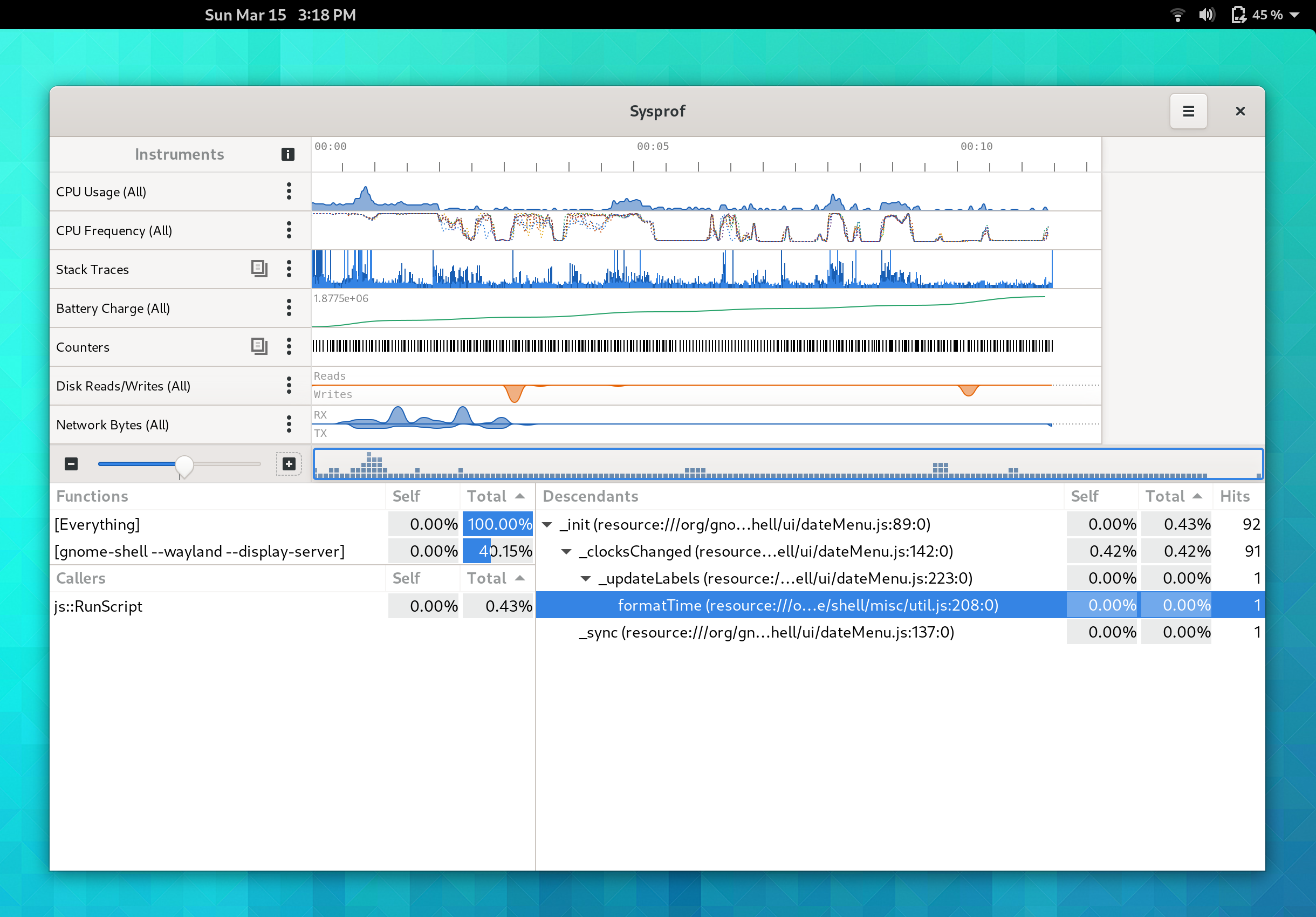
Now when you open the callgraph in Sysprof, you’ll see JavaScript samples.
JavaScrpt callgraph example
Recording Energy Consumption
On Linux, we have support for tracking energy usage as “Rolling Average Power Limit” or RAPL for short. Sysprof can include this information for you in your capture if you have the turbostat utility available. It provides power information per “package” such as the GPU and CPU.
Keeping power consumption low is an important part of a modern desktop that aims to be useful on laptops and smaller form factors. It’s useful to check in now and again to ensure that we’re keeping things tip top.
You might want to disable sampling while testing power consumption because that could have a larger effect in terms of wattage than the thing you’re profiling.
Don’t forget to check the counter and energy menus for additional graphs.
Reducing Memory Allocations
Plugging memory leaks is a great thing to do. But sometimes it’s better to never allocate things to begin with. The --memprof option can help you find extraneous allocations in your program. For example, I tested the --memprof option on GNOME Shell when writing it and immediately found a way to reduce temporary allocations by hundreds of MiB per minute of use.
This one requires you to build Sysprof until our next release, but you can use the --speedtrack option to find things running on your main loop that may not be a good idea. It will also insert marks for how long the main loop iterations run to find periods of time that you aren’t staying interactive.
First off, before using Sysprof to improve the performance of a particular piece of software, make sure you’re compiling with flags that allow us to have enough information to unwind stack frames. Sysprof will use libunwind in some cases, but a majority of our stack unwinding is done by the Linux kernel which can currently only follow eh_frame (exception handling) information.
I generally disable the G_SLICE allocator because it isn’t really all that helpful on modern Linux systems using glibc and can also make it more difficult to track down leaks. Furthermore, it can get in the way of releasing memory back to the system in the form of malloc_trim() should we start doing that in the future. (Hint, I’d like to).
Finding code run often on the system
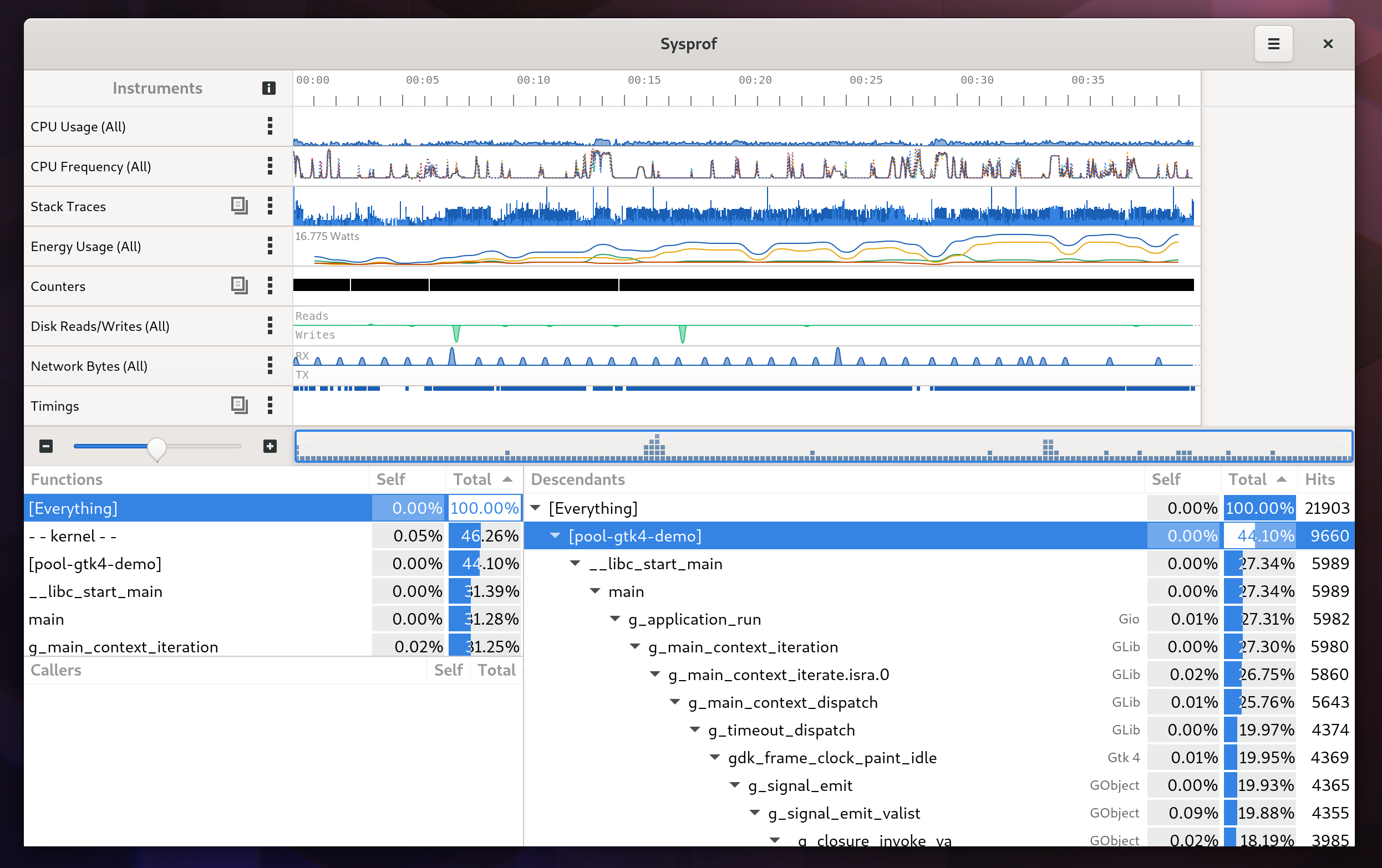
Sysprof, at it’s core, is a “whole system” profiler. That means it is not designed to profile just your single program, but instead all the processes on the system. This is very useful in a desktop scenario where we have lots of interconnected components.
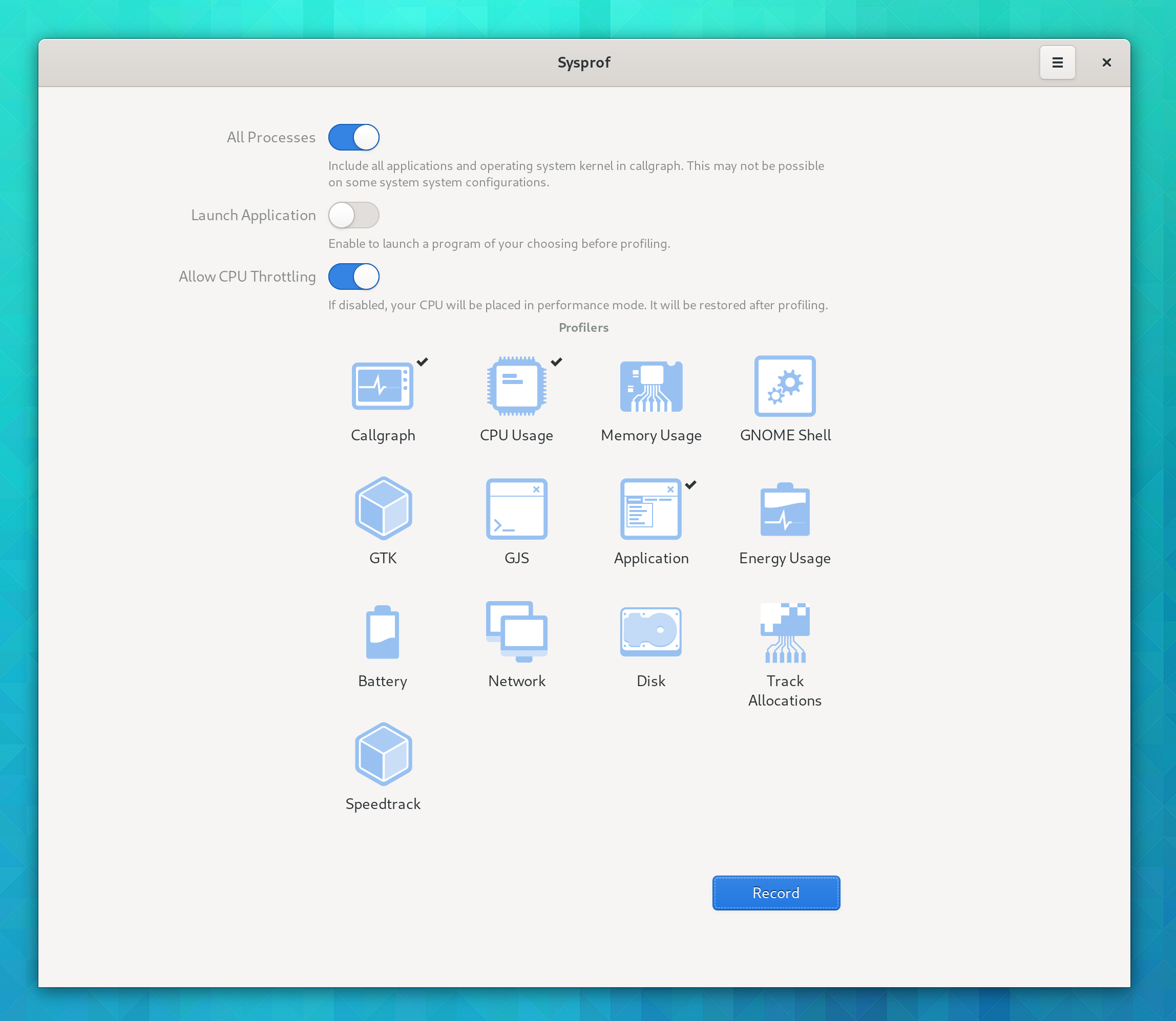
Ensure the “Callgraph” aid is selected and click “Record”.
At this point, excercise your system to try to bring out the behavior you want to optimize. Then click “Stop” to stop recording and view the results.
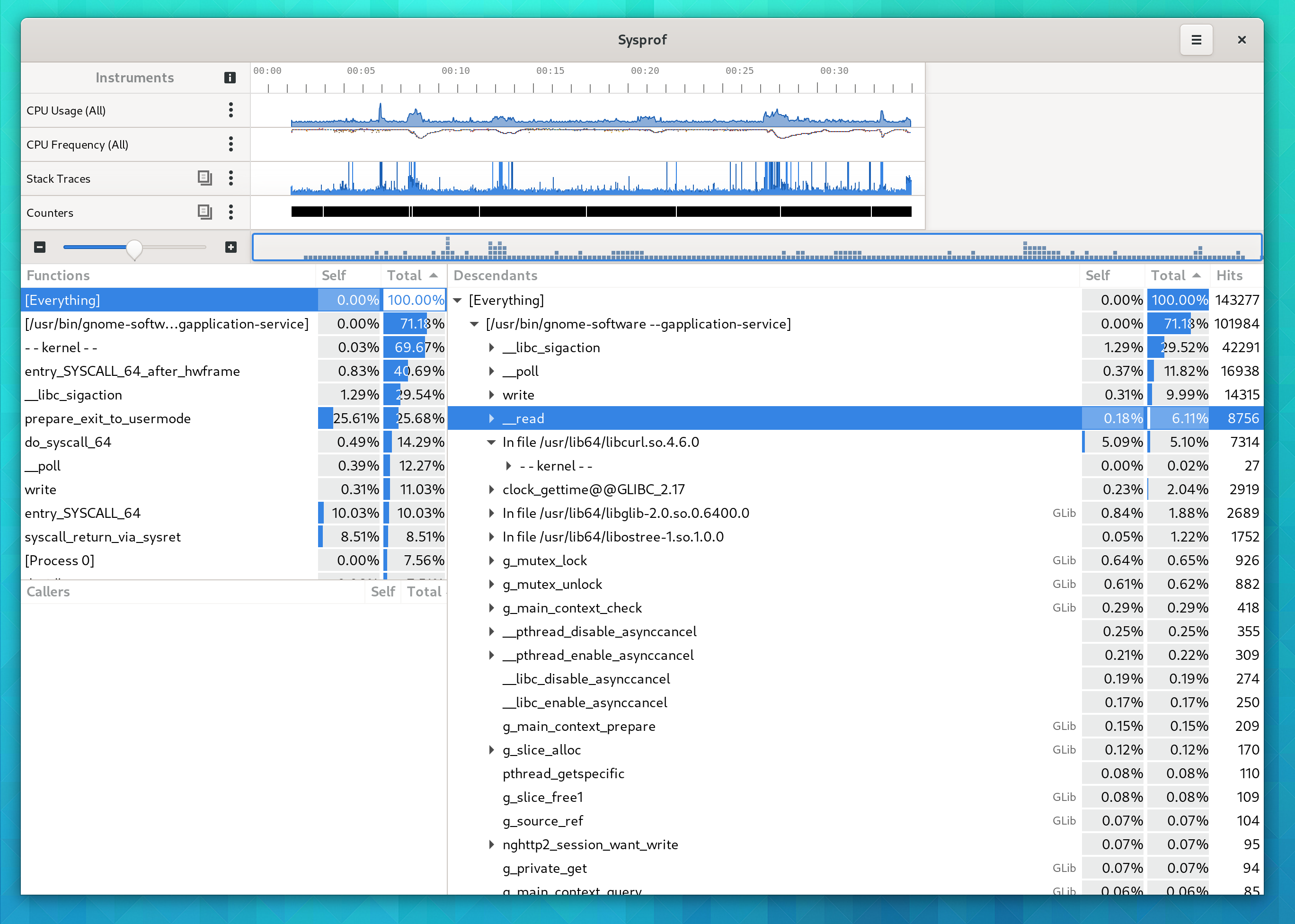
You’ll be presented with a callgraph like the following after it has completed recording and loaded the information.
You’ll notice a lot of time in gnome-software there. It turns out I’m on a F32 alpha install and there was a behavior change in libcurl that has screwed up a number of previously valid use cases. But if I didn’t know that already, this would point me where to start looking. You’ll notice that I hadn’t compiled libcurl or gnome-software from source, so the stack traces are not as detailed as they would be otherwise.
On the right side is a callgraph starting from “[Everything]”. It is split out by process and then by the callstack you see in that program. On the top-left side, is a list of all functions that were collected (and decoded). On the bottom-left side is a list of callers for the selected function above it. This is useful when you want to backtrack to all the places a function was called. (Note that this is a sampling-based profiler, so there is no guarantee all functions were intercepted).
Use this information to find the relevant code within a particular project. Tweak some things, try again, test…
Tracking down extraneous allocations
One of the things that can slow down your application is doing memory allocations in the hot paths. Allocating memory is still pretty expensive compared to all of the other things your application could be doing.
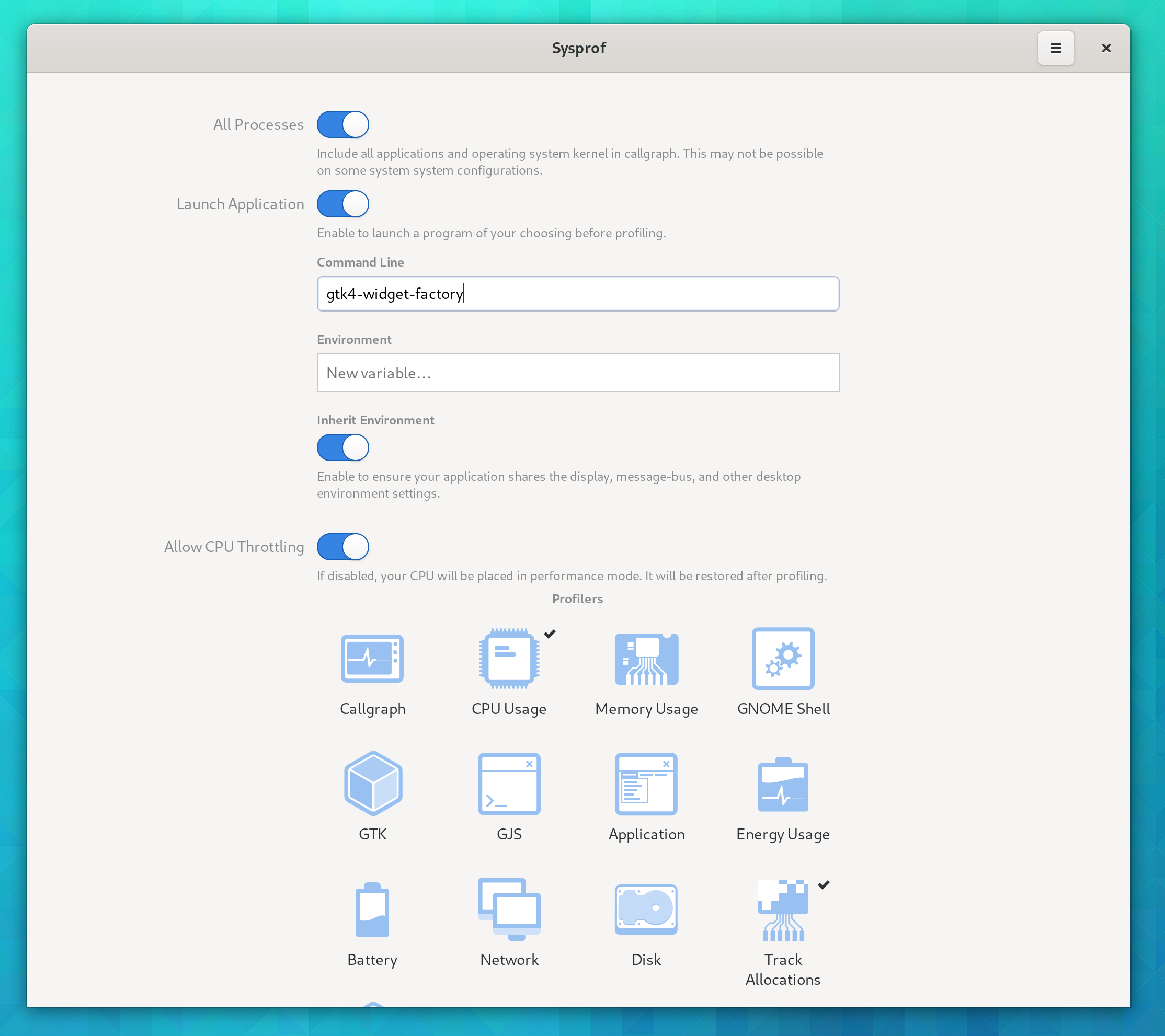
In 3.36, Sysprof gained support for tracking memory allocations with a LD_PRELOAD. However, it must spawn the application directly.
Start by toggling “Launch Application” and set arguments for the application you want to profile. Select “Track Allocations”.
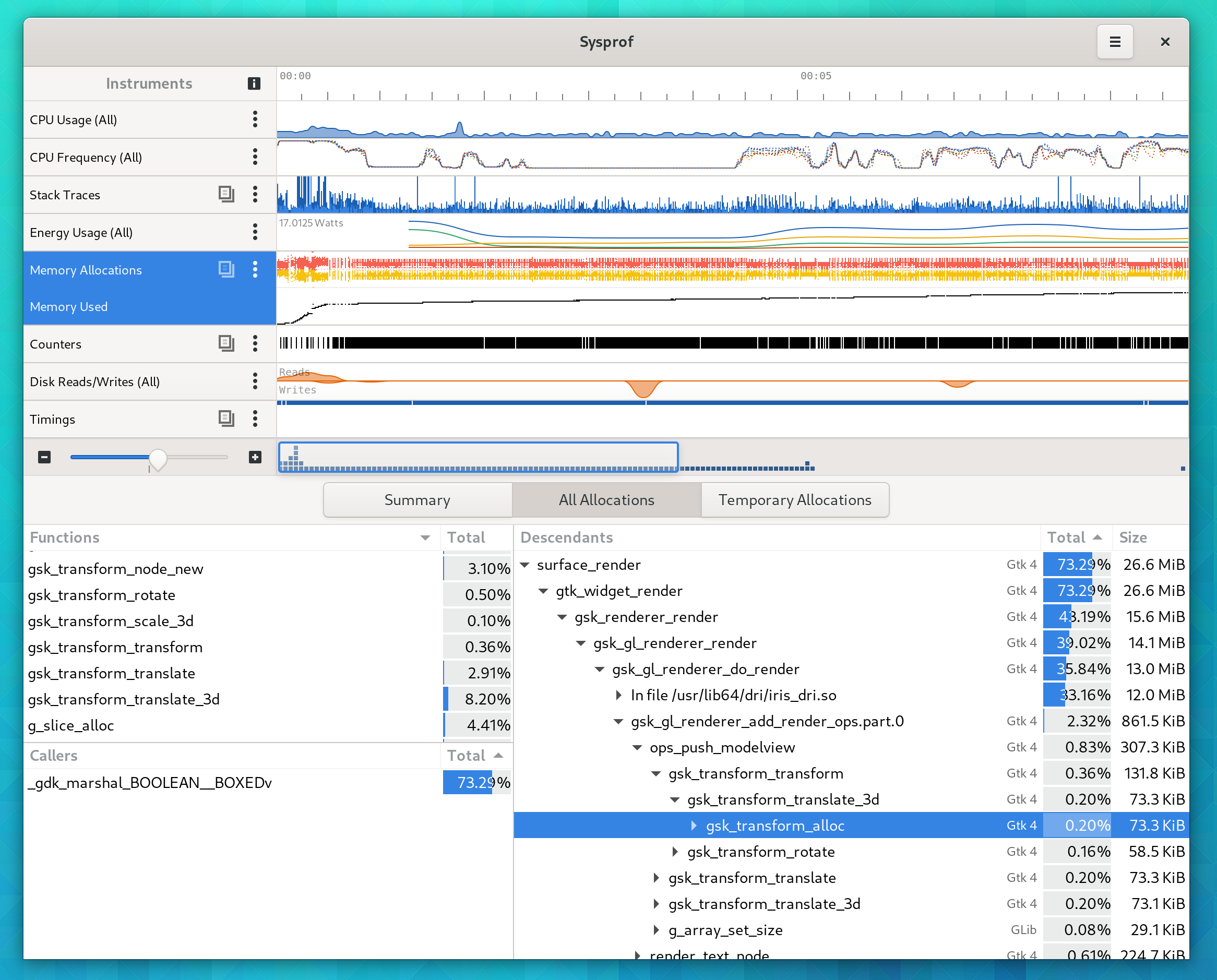
At this point run your application to exercise the targeted behavior. Then press “Stop” and you’ll be presented with the recording. Usually the normal callgraph is selected by default. Select the “Memory Allocations” row and you’ll see the memory callgraph.
This time you’ll see memory allocation size next to the function. Explore a bit, and look for things that seem out of place. In the following image, I notice a lot of transforms being allocated. After a quick discussion with Benjamin, he landed a small patch to make those go away. So sometimes you don’t even have to write code yourself!
A variant of this patch went into Mutter’s copy of Clutter for a healthy memory improvement too.
Finding main loop slow downs
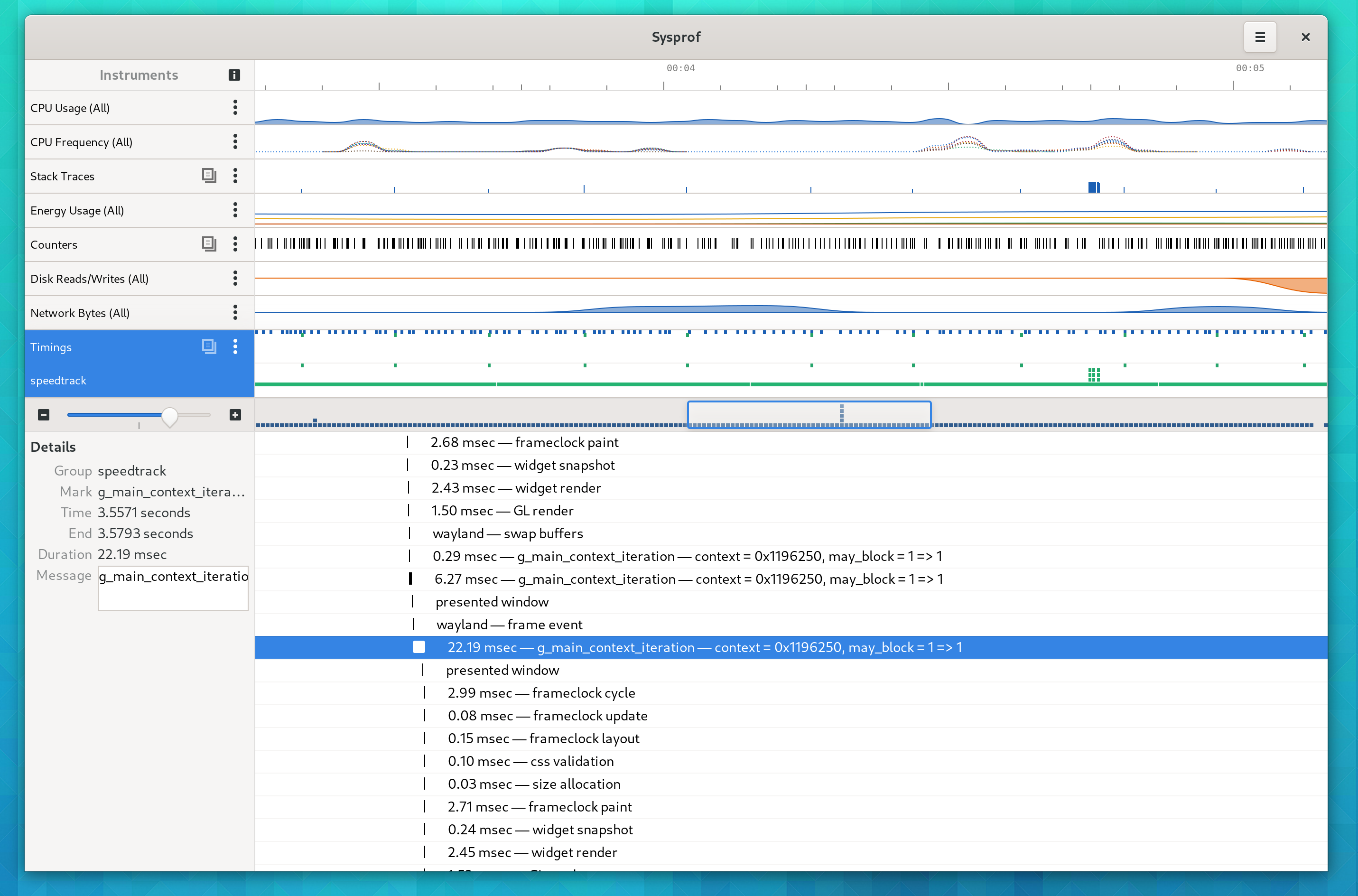
In Sysprof master, we have a “Speedtrack” aid that can help you find various long running operations such as fsync(). I used this late in the 3.36 cycle to fix a bunch of I/O happening on GNOME Shell’s compositor thread. Select the “Speedtrack” aid, and disable the “Callgraph” as that will clash with speedtrack currently. This also uses an LD_PRELOAD so you’ll have to spawn the application just like for memory tracking.
The aid will give you callgraphs of various things that happened in your main thread that you might want to avoid doing. Stuff like fsync(), read() and more. It also creates marks for the duration of these calls so you can track down how long they ran for.
Deep in Pango, various files are being loaded on demand which can mean expensive read() during the main loop operations.
You can also see how long some operations have taken. Here we see g_main_context_iteration() took 22 milliseconds. On a 60hz system, that can’t be good because we either missed a frame or took too long to do something to be able to submit our frame in time. You can select the time range by activating this row. In the future we want this to play better with callgraphs so you can see what was sampled during that timespan.
Anyway, I hope that gives you some insight into how to use things!
Over the past few weeks I’ve been finishing up various projects for 3.36. None of this is surprising for those that follow me on twitter, but sadly I find it hard to blog as often as I should.
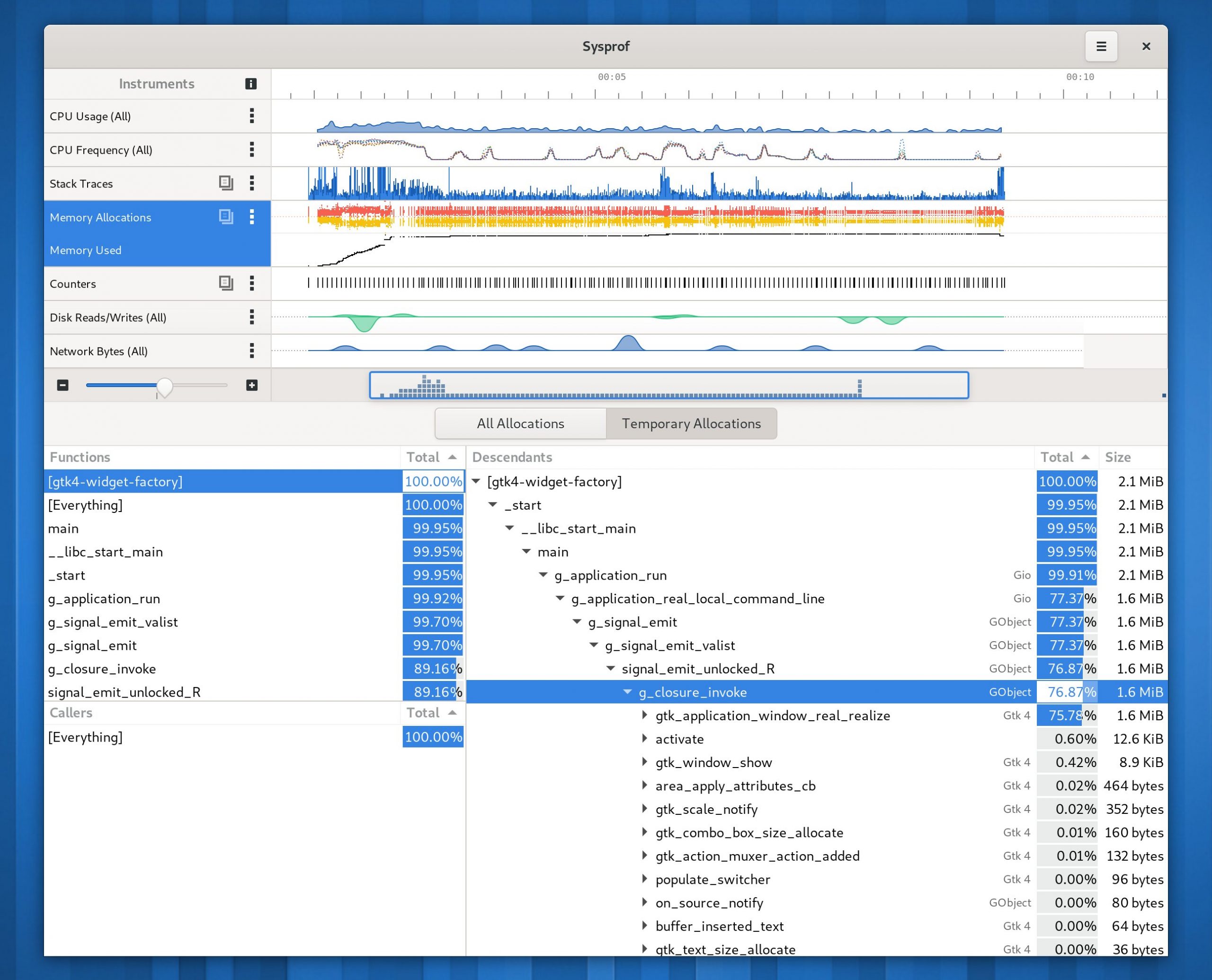
One of the projects I completed before the end of the cycle is a memory allocation tracker for Sysprof. It’s basically a modern port of the Memprof code from 20 years ago, but tied into Sysprof and using fancier techniques to move data quickly between processes. It uses an LD_PRELOAD to override many of the weak memory symbols in glibc such as malloc() and free(). When those functions are reached, a stack trace is captured directly into a mmap()‘d ring buffer shared by Sysprof. We create a new one of these per-thread so that no locking is necessary between threads. Sysprof will mux all the data together for us.
Below is a quick example running gtk4-widget-factory. We show similar callgraphs as we do when doing CPU profiling, but ordered by the amount of memory allocated. This simple tool and less than 20 minutes of effort found many allocations we could completely avoid across both GTK and Clutter.
I just want to mention how refreshing it is to have memory allocation tracking while still starting the application in what feels like instantly. It was quite a bit of tweaking to get that level of performance and I’m thrilled with the result.
Additionally, I spent some time looking at what sort of things cause temporary lockups in GNOME Shell during active use. With a fio script in hand, I had the necessary things to cause the buffer cache to be exhausted and force many applications working set out of memory. That usually does the trick to cause short lockups.
But what is going on when things stall? Does the GPU driver get bogged down? Does the Shell get blocked on GC? Is there some sort of blocking API involved?
To answer this I put together a scrappy little LD_PRELOAD tool called “iobt” which will write out a Sysprof capture file when some blocking operations are called. This found a very peculiar bug where GNOME Shell could end up blocking on the compositor thread when it thought it was doing all async I/O operations.
Furthermore, I found a number of other I/O operations happening on the main thread which will easily lock things up under heavy writeback scenarios. Patches for all of these are upstream, half of them are merged at this point, and some even backported to 3.28 for various distros.
There are still some things to do going forward, like use cgroupsv2 to help enforce CPU and Memory availability and other priorities. I’m also looking for pointers from GPU people on how to debug what is going on during long blocking eglSwapBuffers() calls as I’ve seen under memory pressure.
I’m always inspired by what the Shell developers build and I’m honored to get to help polish it even more.
I’ve branched GtkSourceView for 4.6 (gtksourceview-4-6) which you should be using instead of master for your application’s Nightly Flatpak builds. I will land the GTK 4 port on master early next week. A message to gnome-announce-list has been sent and will hopefully make it into distribution packagers inbox shortly.
Long story short is that the 4.6 series will be our long-term (and last) series for GTK 3 applications. I expect this to be maintained for many years. Master will become the beginning of our transition to GTK 4 and the place we land lots of upstream features for Next.0.
I’m trying to blog about every week now this year, so here we go again.
The past week I’ve been pushing hard on finishing up the snippets work for the GTK 4 port. It’s always quite a bit more work to push something upstream because you have to be so much more complete while being generic at the same time.
I think at this point though I can move on to other features and projects as the branch seems to be in good shape. I’ve fixed a number of bugs in the GTK 4 port along the way and made tests, documentation, robustness fixes, style-scheme integration, a completion provider, file-format and parser, and support for layering snippet files the same way style-schemes and language-specs work.
As part of the GTK 4 work I’ve spent a great deal time modernizing the code-base. Now that we can depend on the same things that GTK 4 will depend on, we can use some more modern compiler features. Additionally, GObject has matured so much since most of the library was written and we can use that to our advantage.
We’re currently finishing up the cycle towards GNOME 3.36, which means it’s almost time to start branching and thinking about what we want to land early in the 3.37 development cycle. My goal is to branch gtksourceview-4-6 which will be our long-term stable branch for gtksourceview-4.x (similar to how the gnome-3-24 branch is our long-term stable for the gtksourceview-3.x series. After that, master will move to GTK 4 as we start to close in on GTK 4 development. The miss-alignment in version numbers is an unfortunate reality, but a reality I inherited so we’ll keep on keepin’ on.
That means if you are not setting a branch in your flatpak manifests, you will want to start doing that when we branch (probably in the next couple of weeks) or your builds will start to fail. Presumably, this only will affect your Nightly builds, because who targets upstream master in production builds, not you surely!
Snippets
I’ve started moving some features from Builder into GtkSourceView. However, I’m limiting those to the GTK 4 port because I don’t particularly want to add new ABI right before putting a branch into long-term stability mode. The first to be uplifted into GtkSourceView is Builder’s snippet engine. It also went through quite a bit of rewrite and simplification as part of this process to make it more robust. Furthermore, having moved undo/redo into GtkTextBuffer directly has done wonders from a correctness standpoint. The snippet engine used to easily be confused by the undo/redo engine.
The most difficult part of the snippet engine is dealing with GtkTextMark that are adjacent. In particular if you have each snippet focus-position wrapped in marks. Adjacent, empty mark ranges can end up overlapping each other and you have to be particularly diligent to prevent that. But the code in the branch has a pretty good handle on that, much better than what I had done in the past inside of Builder.
The bits I still need to do to finish up the snippet engine:
Land the GTK 4 port on master.
Add various style tags to bundled style schemes.
Documentation of course.
A new snippet manager, file format, and parser. We’ll probably switch to XML for this so it matches language-spec and style-scheme instead of our adhoc format from Builder.
Future work
Completion
After the GTK 4 port and snippet engine has landed, I’ll probably turn my work towards updating the completion APIs to take advantage of various GLib/GIO advancements from recent years (similar to what we did in Builder). We can also do a bit of style refreshing there based on what Builder did too.
Indenters
If we can find a nice API for it, I’d like to land a basic indenter API as well. The one we have in Builder has worked, but it’s not exactly simple to write new indenters. Then we can start having contributions upstream which can be tied to a specific language-spec. Doing language specific stuff is always nice.
Movements Engine
How you move through a GtkTextView is rather simplistic. There are a number of keyboard accelerators for common movements but they are far more restrictive than what you’d expect from a code editor. In Builder we’ve had custom signals to do more robust movements which the VIM, Emacs, and Sublime emulation builds off.
We can make this more robust in the future using GTK 4’s widget actions. I plan to move a lot of the custom movements from Builder into GtkSourceView so that we can eventually have keyboard shortcut emulation upstream.
Event Controllers
One of the trickiest (and dirtiest) bits of code in Builder is our VIM keybindings emulation for the editor. It always was meant to be a hack to get us to GTK 4, and it did that fine. But we should let it end with that as the constraints from a gtkrc-based (GTK 2.x) system ported to CSS (GTK 3.x) is simply too much pain to bare.
In GTK 4 we have event controllers, especially those for handling keyboard input. I think it is possible for us to move much of a VIM emulation layer (for input) into an event controller (or GtkGesture even). Given that this would use C code instead of CSS, I’d have a much easier time dealing with all the hundreds of corner cases where VIM is internally inconsistent, but expected behavior.
Hover Providers
The Language Server Protocol has had success at abstracting a number of things, including the concept of “Hover Providers”. These are essentially interactive tooltips. Builder has support for them built upon transient GtkPopover. This seems like a possible candidate to move up to GtkSourceView too.
Other Possibilities
Some other possibilities, given enough interest, could be our OmniGutterRenderer from Builder (with integrated debug breakpoint and diagnostic integration), line-change gutter renderers (which can be connected to Git, SVN, etc), reformatting, semantic highlighting, and multiple cursors. However that last one is incredibly difficult to do from a completeness standpoint as it might need some level of plumbing down in GtkTextView for robustness sake.
I spent some time this cycle porting GtkSourceView to GTK 4. It was a good opportunity to help me catch up on how GTK 4’s internals have changed into something modern. It gave me a chance to fix a few pot-holes along the way too.
One of the pot-holes was one I left in GtkTextView years ago. When I plumbed the pixelcache into GTK 3’s TextView I had only cached the primary text content. It seemed fine at the time because the gutters (used for line numbers) is just not that many pixels. So if we have to re-generate that every frame, so be it.
However, in a HiDPI world and 4k monitors on our laps things start to get… warm. So while changing the drawing model in GtkTextView we decided to make the GtkTextView gutters real widgets. Doing so means that GtkSourceGutterRenderer will be real GtkWidget‘s going forward and can do all sorts of neat stuff widgets can do.
But to address the speed of rendering we needed a better way to avoid walking the text btree linearly so many times while rendering the gutter. I’ve added a new class GtkSourceGutterLines to allow collecting information about the text buffer in one-pass. The renderers can then use that information when creating render nodes to avoid further tree scans.
I have some other plans for what I’d like to see before a 5.0 of GtkSourceView. I’ve already written a more memory-compact undo/redo engine for GTK’s GtkTextView, GtkEntry, GtkText, and friends which allowed me to delete that code from the GtkSourceView port. Better yet, you get undo/redo in all the places you would, well, expect it.
In particular I would like to see the async+GListModel based API for completion from Builder land upstream. Builder also has a robust snippet engine which could be reusable from GtkSourceView as that is a fairly useful thing across editors. Perhaps we could extract Builder’s indenter APIs and movements engine too. These are used by Builder’s Vim emulation quite heavily, for example.
If you like following development of stuff I’m doing you can always get that fix here on Twitter given my blogging infrequency.
TL;DR: Pair your Linux devices, developer APIs to share files, create object graphs with partial sync between devices, transactions, secondary indexes, rebasing, and more built upon GVariant and LMDB. Tooling to build cloudless multi-device services.
I’ve been spending a great deal of time thinking about what types of products I’d like to see in GNOME and what is missing to make that happen.
One observation is that I want access to my files and application data on all my computing devices but I don’t want to store that data on other peoples computers. I have computers, they have internet access, I shouldn’t have to use a multi-tenancy cloud if I’m running as much Free Software as I do. But if that is going to be competitive it needs to be easier than the alternatives.
But to build this I need a few fundamental layers to build applications atop. I’ll need access to files using all the GIO file APIs we love (GFile, GFileEnumerator, GIOStream, etc). I’ll also need the ability to read and write application data in a way that can be shared between devices which may not always be connected to my home Wi-Fi. In particular, we need to give developers great tools to make applications that natively support device synchronization.
What I’ve built to experiment with this all is Bonsai. It is very much an experiment at this phase but it is getting interesting enough to collaborate with others who would like to join me.
Bonsai consists of a daemon that you run on your “mostly connected” computer. Although that could easily be a raspberry pi quality computer in your home. That computer hosts the “upstream” storage space for files and application content.
Other devices like laptops, phones, or IoT can be paired with that primary device. They communicate using TLS connections using pinned self-signed certificates with point-to-point D-Bus serialization on top. The D-Bus serialization makes it convenient to use gdbus-codegen to generate proxies and services.
One service available to devices is the storage service. It can be consumed from libbonsai-storage to allow applications to browse, create, move, modify and stream file content.
Applications are much better when they can communicate between devices. So a Data-Access-Object library, aptly named libbonsai-dao, provides serializable object storage built upon GVariant and LMDB. It supports primary and secondary indexes, queries, cursors, transactions, and incremental sync between devices. It has the ability to rebase local changes atop changes pulled from the primary Bonsai device.
That last bit is neat because it means if an application is running on two devices which create new content they don’t clobber each others history.
The primary issue here is dealing with merge conflicts but libbonsai-dao provides some design for data objects to do the right thing.
Bonsai could also could serve as a base to build interesting services like backup, VPN, media sharing and casting, news, notes, calendars, contacts, and more. But honestly, it can only do that if people are actually interested in something like this. If so, let me know and see if you can lend your time or ideas for what you’d want this to become.
I just uploaded the sysprof-3.33.4 tarball as we progress towards 3.34. This alpha release has some interesting new features that some of you may find interesting as you continue your quests to improve the performance of your system by improving the software running upon it.
For a while, I’ve been wondering about various ways to move GtkTextView forward in GTK 4. It’s of particular interest to me because I spent some time in the GTK 3 days making it faster for smooth scrolling. However, the designs that were employed there work better on the traditional Xorg setup than they do on GTK 3’s Wayland backend. Now that GTK 4 can have a proper GL pipeline, there is a lot of room for improvement.
Thanks to the West Coast Hackfest, I had a chance to sit down with Matthias and work through that design. GtkLabel was already using some accelerated text rendering so we started by making that work for GtkTextView. Then we extended the GSK PangoRenderer to handle the rest of the needs of GtkTextView and Matthias re-implemented some features to avoid cairo fallbacks.
After the hackfest I also found time to implement layout caching of PangoLayout. It helps reduce some of the CPU overhead in calculating line layouts.
As we start using the GPU more it becomes increasingly important to keep the CPU usage low. If we don’t it’s very likely to raise overall energy usage. To help keep us honest, I’ve added some RAPL energy statistics to Sysprof.