My creative work is more aligned to GNOME cycles than years. Now that GNOME 46 is is out it’s a good time to look back at some of the larger things I did during those cycles.
Fedora and Frame Pointers
2023 kicked off with quite a kerfuffle around frame pointers.
Many people appear to have opinions on the topic though very few are aware of the trade-offs involved or the surface area of the problem domain. I spent quite some time writing articles to both educate and ultimately convince the Fedora council that enabling them is the single best thing they could do to help us make the operating system significantly faster release-to-release.
Much to my surprise both Ubuntu and Arch are choosing to follow.
Early this year I published an article in Fedora Magazine on the topic.
Futures, Fibers and Await for C
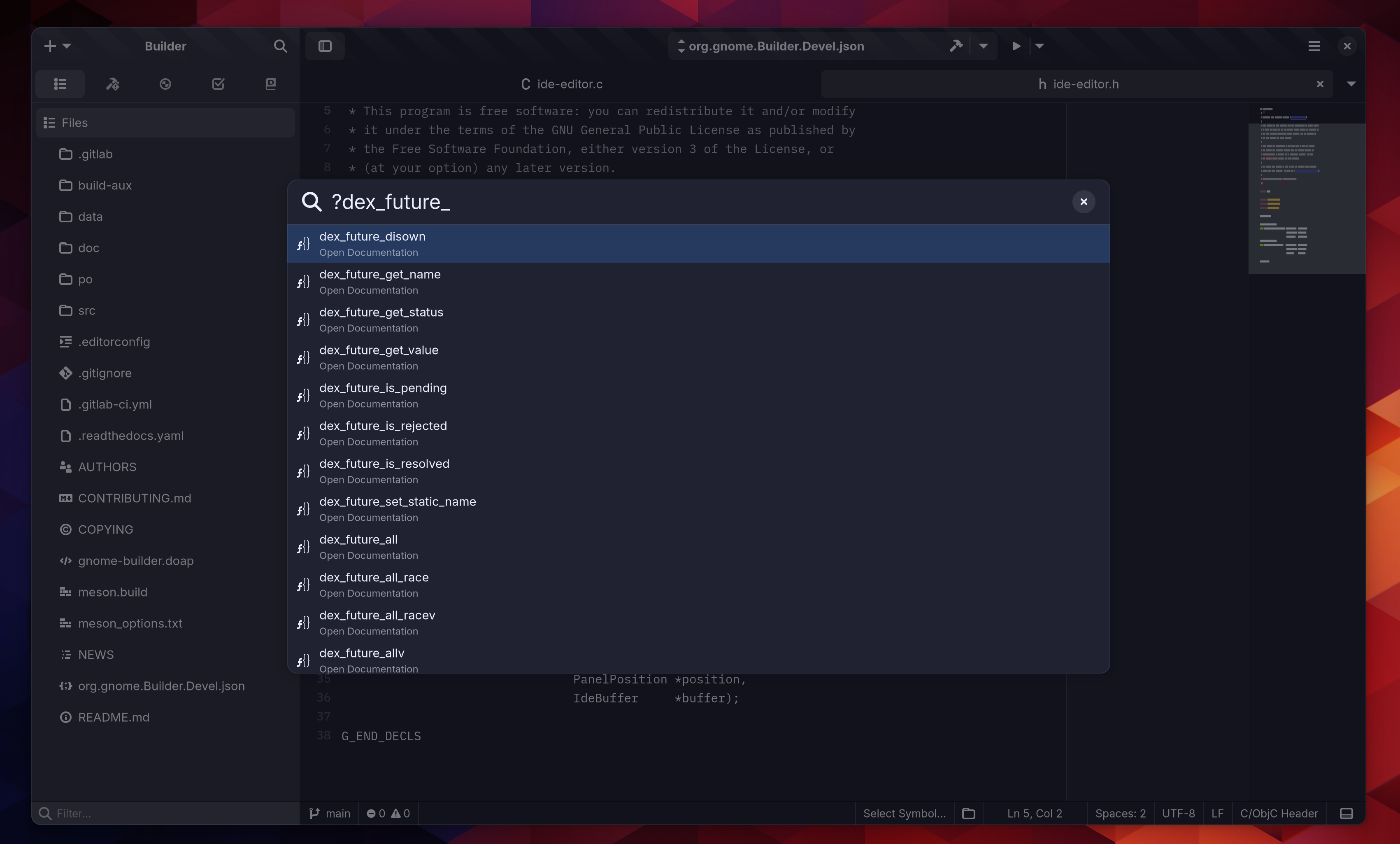
I still write a lot of C and have to integrate with a lot of C in my day to day work. Though I really miss asynchronous programming from other languages like when I was working on Mono all those years. Doing that sort of programming in C with the GObject stack was always painful due to the whole async/finish flow.
For decades we had other ways in C but none of them integrated well with GObject and come with their own sort of foot-guns.
So I put together libdex which could do futures/promises, fibers (including on threads), lock-free work-stealing among thread-pools, io_uring integration, asynchronous semaphores, channels, and more.
It’s really changed how I write C now especially with asychronous workflows. Being able to await on any number of futures which suspend your fiber is so handy. It reminds me a lot of the CCR library out of the Microsoft Robotic Labs way back when. I especially love that I can set up complex “if-these-or-that” style futures and await on them.
I think the part I’m most proud of is the global work queue for the thread-pool. Combining eventfd with EFD_SEMAPHRE and using io_uring worked extremely well and doesn’t suffer the thundering herd problem that you’d get if you did that with poll() or even epoll(). Being able to have work-stealing and a single worker wake up as something enters the global queue was not something I could do 20 years ago on Linux.
Where this advanced even further is that it was combined with a GMainContext on the worker threads. That too was not something that worked well in the past meaning that if you used threads you had to often forgo any sort of scheduled/repeated work.
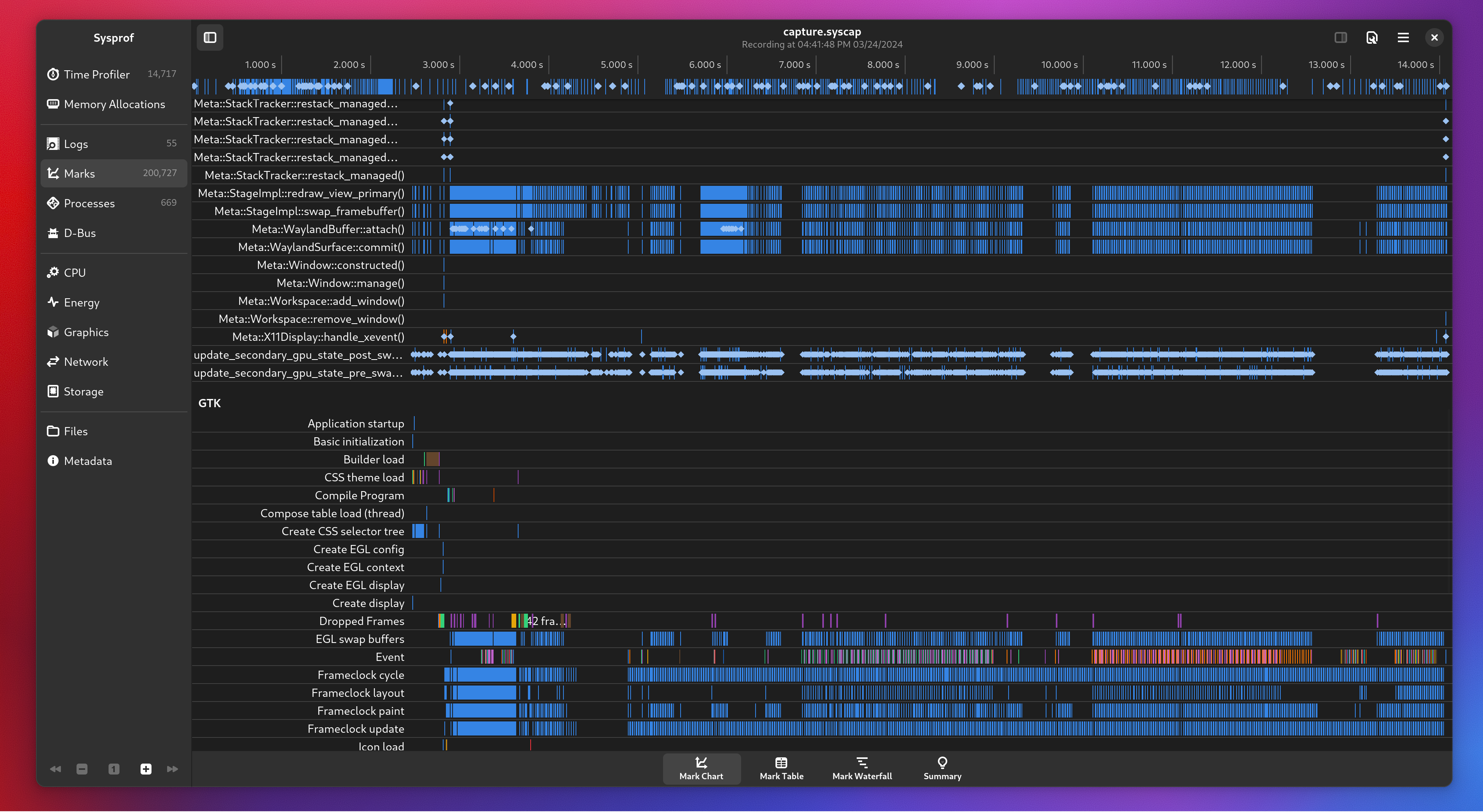
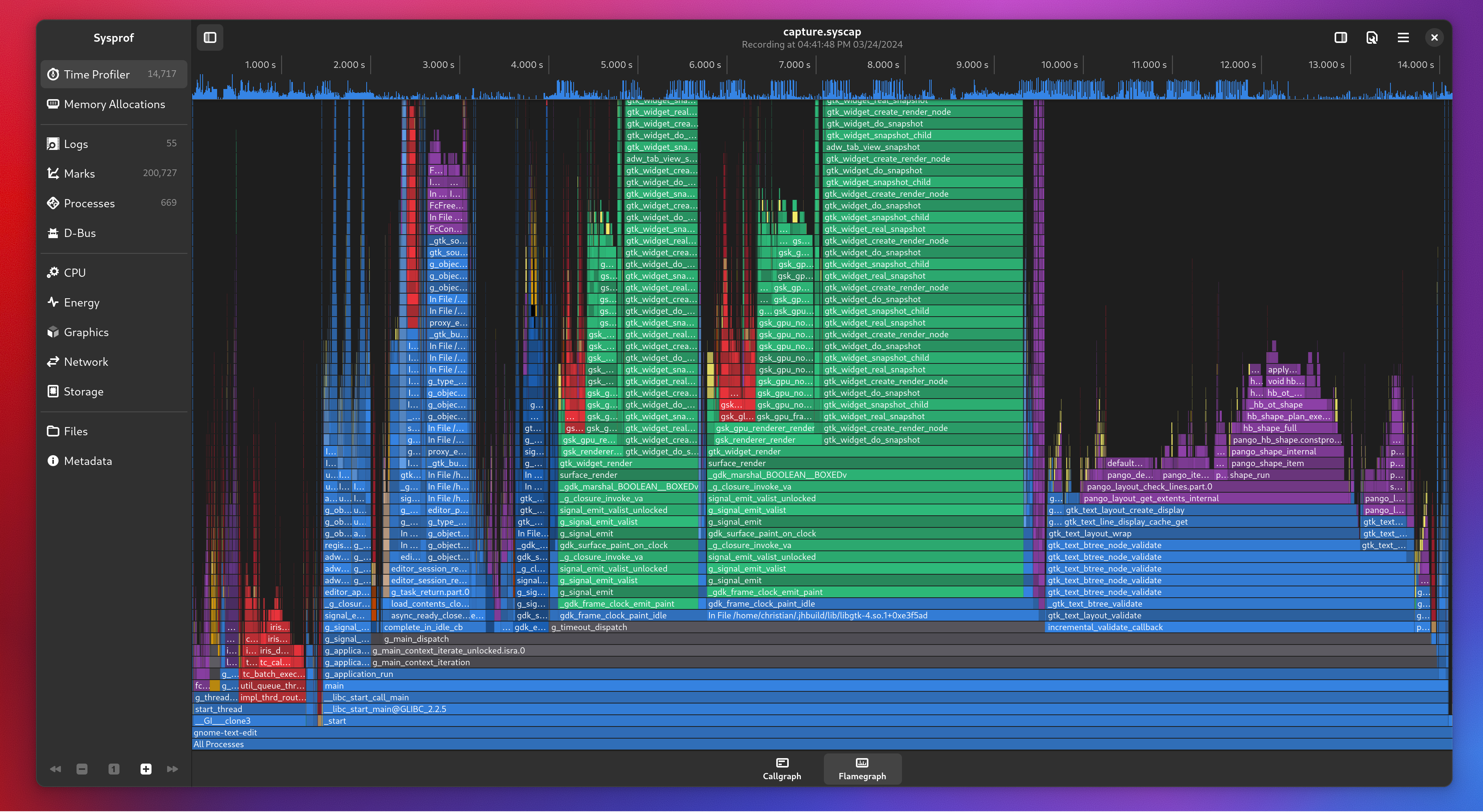
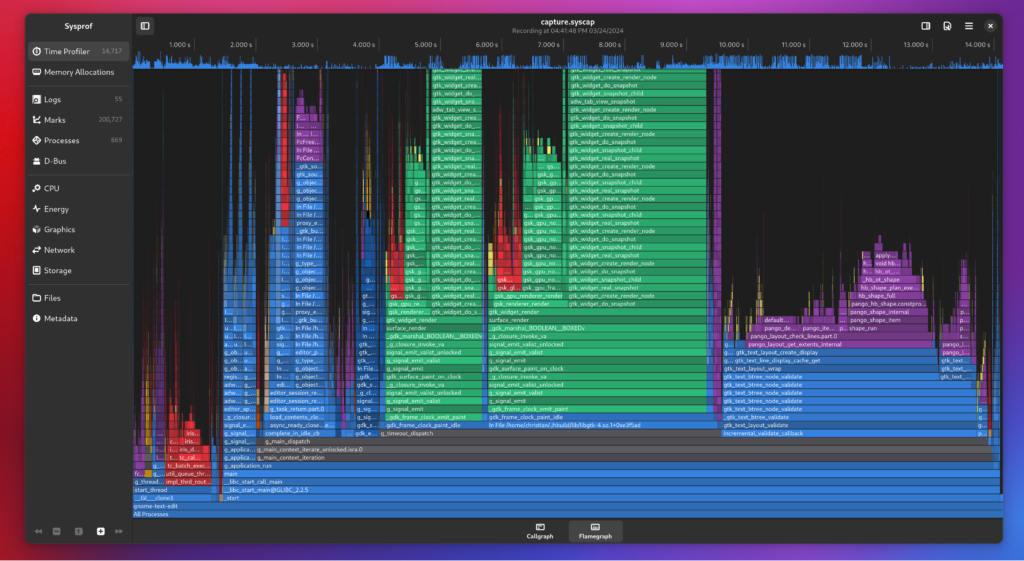
Sysprof
Now that I was armed with actually functioning stack traces coming from the Linux perf subsystem it was time to beef up Sysprof.
Pretty much everything but the capture format was rewritten. Primarily because the way containers are constructed on Linux broke every assumption that profilers written 10 years ago had. Plus this was an opportunity to put libdex through its paces and it turned out great.
Correlating marks across GTK, GLib, and Mutter was extremely valuable.
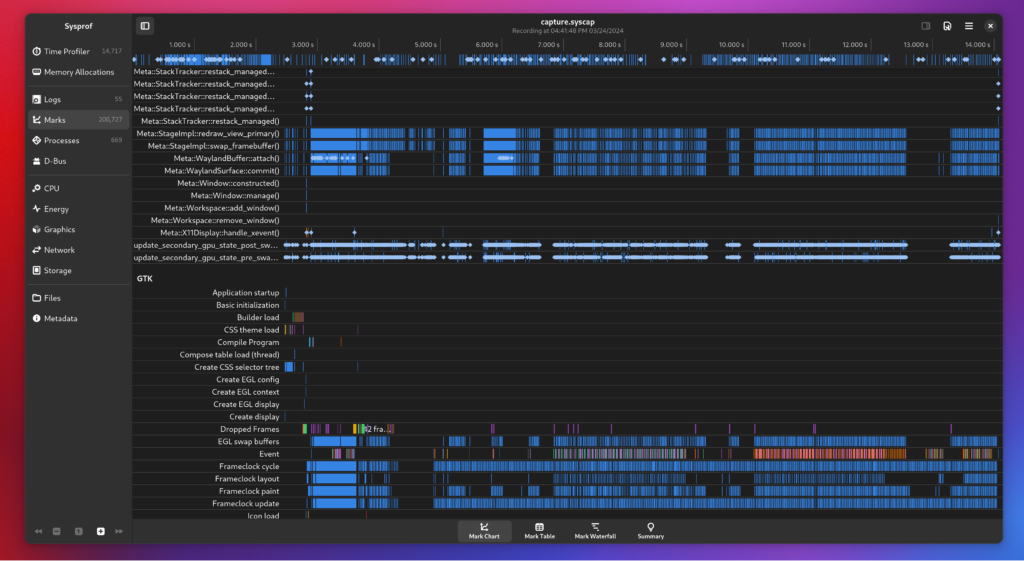
Though the most valuable part is probably the addition of flamegraphs.
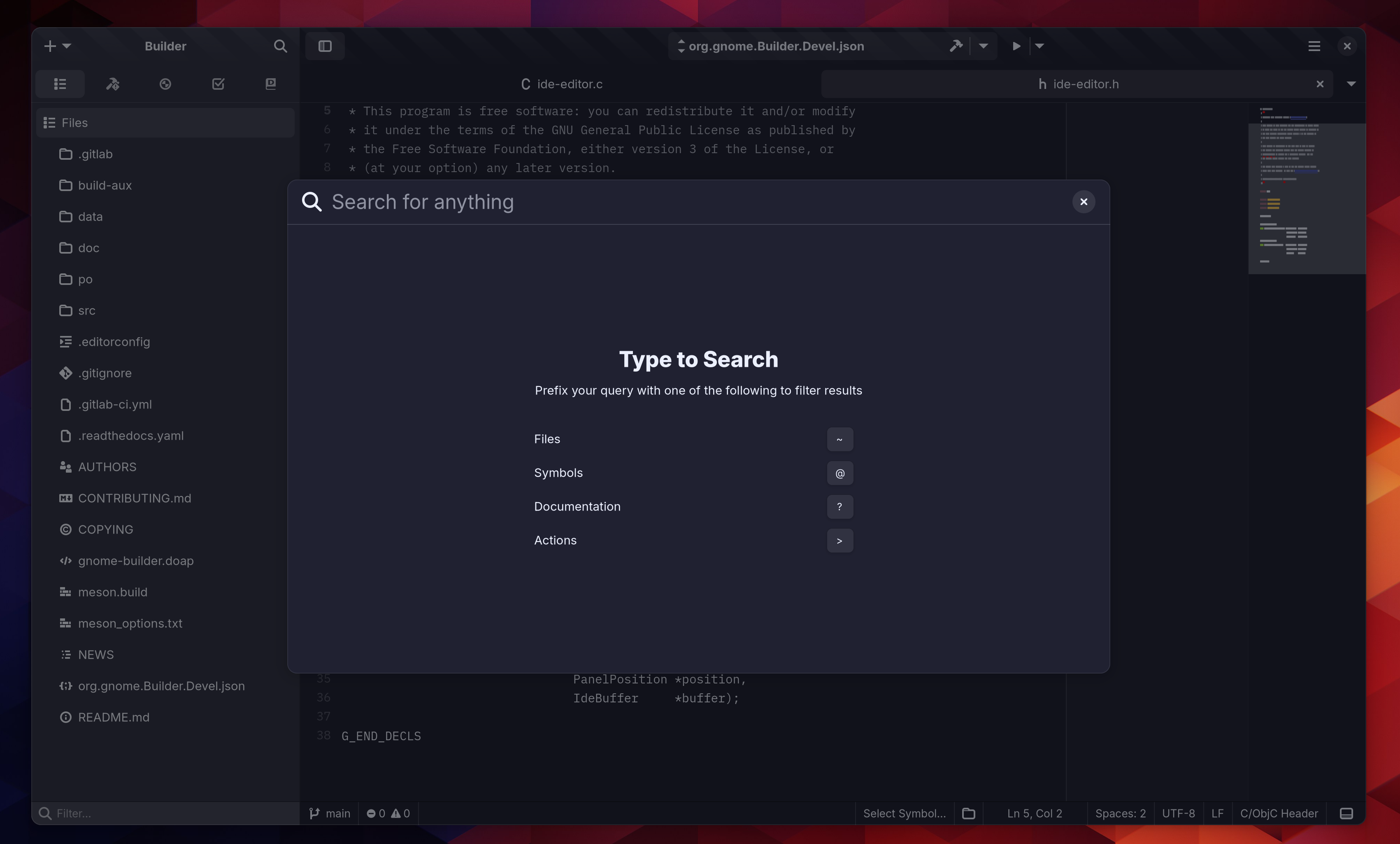
Search Providers
To test out the Sysprof rewrite I took a couple weeks to find and fix performance issues before the GNOME release. That uncovered a lot of unexpected performance issues in search providers. Fixes got in, CPU cycles were salvaged. Projects like Photos, Calculator, Characters, Nautilus, and libgweather are all performing well now it seems. I no longer find myself disabling search providers on new GNOME installations.
This work also caught JXL wallpapers adding double-digit seconds to our login time. That got pushed back a release while upstream improved GdkPixbuf loader performance.
GNOME Settings Daemon
Another little hidden memory stealer was gnome-settings-daemon because of all the isolated sub-daemons it starts. Each of these were parsing the default theme at startup which is fallout from the Meson build system handover. I had fixed this many years ago and now it works again to both save a small amount (maybe 1-3mb each) of memory for each process and reduced start-up time.
libmks
At one point I wanted to see what it would take to get Boxes on GTK 4. It seemed like one of the major impediments was a GTK 4 library to display as well as handle input (mouse, keyboard). That was something I worked on considerably in the past during my tenure at a large virtualization company so the problem domain is one I felt like I could contribute to.
I put together a prototype which led me to some interesting findings along the way.
Notably, both Qemu and the Linux kernel virtio_gpu drivers were not passing damage regions which prevented GTK from doing damage efficiently. I pointed out the offending code to both projects and now those are fixed. Now you can use the drm backend in a Qemu VM with VirGL and virtio_gpu and have minimal damage all the way through the host.
That work then got picked up by Bilal and Benjamin which has resulted in new APIs inside of GTK and consumed from libmks to further optimize damage regions.
Qemu however may still need to break it’s D-Bus API to properly pass DMA-BUF modifiers.
GtkExpression Robustness
While working on Sysprof I ran into a number of issues with GtkExpression and GObject weak-ref safety. When you do as much threading as Sysprof does you’re bound to break things. Thankfully I had to deal with similar issues in Builder years ago so I took that knowledge to fix GtkExpression.
By combining both a GWeakRef and a GWeakNotify you can more safely track tertiary object disposal without races.
GObject Type-System Performance
Also out of the Sysprof work came a lot flamegraphs showing various GType checking overhead. I spent some time diving in and caching the appropriate flags so that we save non-trivial percentage of CPU there.
My nearly decade desire to get rid of GSlice finally happened for most platforms. If you want really a really fast allocator that can do arenas well, I suggest looking into things like tcmalloc.
systemd-oomd
Also out of the Sysprof work came a discovery of systemd-oomd waking up to often and keeping my laptops from deeper sleep. That got fixed upstream in systemd.
Manuals
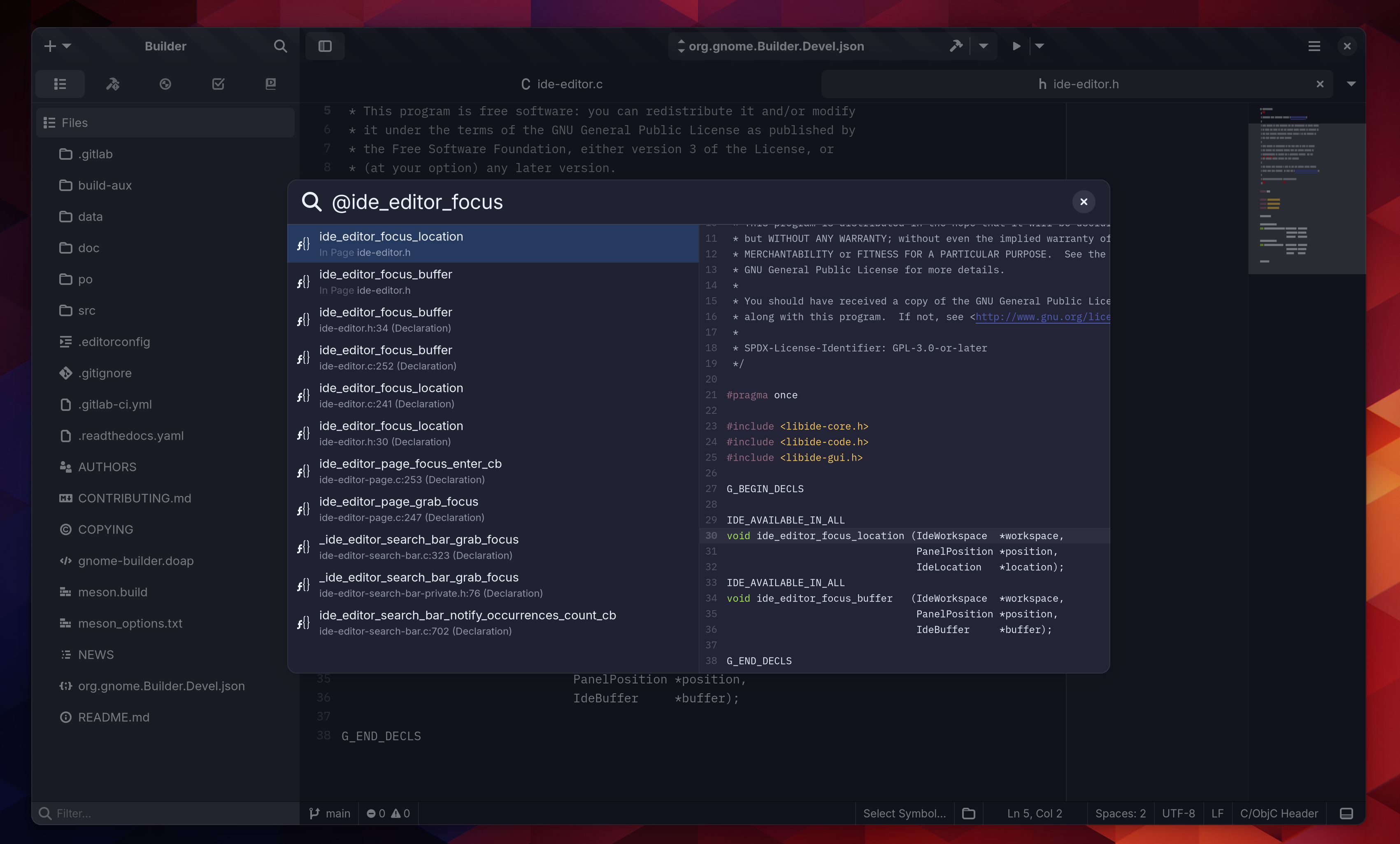
One prototype I created was around documentation viewers and I’m using it daily now.
I want to search/browse documentation a bit differently than how devhelp and other documentation sites seem to work. It indexes everything into SQLite and manages that in terms of SDKs. Therefore things like cross-referencing between releases is trivial. Currently it can index your host, jhbuild, and any org.gnome.Sdk.Docs Flatpak SDK you’ve installed.
This too is built on libdex and Gom which allows for asynchronous SQLite using GObjects which are transparently inflated from the database.
Another fun bit of integration work was wrapping libflatpak in a Future-based API. Doing so made writing the miners and indexers much cleaner as they were written with fibers.
Gom
A decade or more ago I made a library for automatically binding SQLite records to GObjects. I revamped it a bit so that it would play well with lazy loading of objects from a result set.
More recently it also saw significant performance improvements around how it utilizes the type system (a theme here I guess).
libpanel
Writing an application like GNOME Builder is a huge amount of work. Some of that work is just scaffolding for what I lovingly consider Big Fucking Applications. Things like shortcut engines, menuing systems, action management, window groups and workspaces, panels, document grids, and more.
A bunch of that got extracted from Builder and put into libpanel.
Additionally I made it so that applications which use libpanel can still have modern GNOME sidebar styling. Builder uses this for its workspace windows in GNOME 46 and contributes to it’s modern look-and-feel.
libspelling
One missing stair that was holding people back from porting their applications to GTK 4 was spellcheck. I already had a custom spellchecker for GNOME Text Editor and GNOME Builder which uses an augmented B+Tree I wrote years ago for range tracking.
That all was extracted into libspelling.
Text Editor
One of the harder parts to keep working in a Text Editor, strangely enough, is task cancellation. I took some time to get the details right so that even when closing tabs with documents loading we get those operations cancelled. The trickier bit is GtkTextView doing forward line validation and sizing.
But that all appears to work well now.
I also tweaked the overview map considerably to make things faster. You need to be extremely careful with widgets that produce so many render nodes which overlap complex clipping. Doubly so when you add fractional scaling and the border of a window can cross two pixels of the underlying display.
GNOME Builder got similar performance treatments.
Frame Jitters
While tracking down GTK renderer performance for GTK 4.14 I spent a lot of timing analyzing frame timings in Sysprof.
First, I noticed how Mutter was almost never dispatching events on time and mostly around 1 millisecond late. That got fixed with a timerfd patch to Mutter which tightens that up. At 120hz and higher that extra millisecond becomes extremely useful!
After fixing Mutter I went to the source and made patches taking two different strategies to see which was better. One used timerfd and the other using ppoll(). Ultimately, the ppoll() strategy was better and is now merged in GLib. That will tighten up every GLib-based application including the GdkFrameClock.
I also added support for the Wayland presentation-time protocol in GTK’s Wayland back-end so that predicted frame times are much more accurate.
GLib
In addition to the ppoll() work above in GLib I also did some work on speeding up how fast GMainContext can do an iteration of the main loop. We were doing extraneous read() on our eventfd each pass resulting in extra syscalls. I also optimized some GList traversals while I was there.
I separated the GWeakRef and GWeakNotify lists inside of GObject’s weak ref system so that we could rely on all pointers being cleared before user callback functions are executed. This predictability is essential for building safety at higher levels around weak references.
GtkSourceView
There were a few more cases in GtkSourceView that needed optimization. Some of them were simpler like premixing colors to avoid alpha blends on the GPU. In the end, applications like Text Editor should feel a lot snappier in GNOME 46 when combined with GTK 4.14.1 or newer.
GTK
I spent some time at the end of the 46 cycle aiding in the performance work on NGL/Vulkan. I tried to lend a hand based on the things I remember helping/hurting/doing nothing while working on the previous GL renderer. In all, I really like where the new NGL/Vulkan renderers are going.
While doing some of that work I realized that finalizing our expired cache entries of lines for the textview was reducing our chance at getting our frames submitted before their deadline. So a small patch later to defer that work until the end of the frame cycle helps considerably.
Another oddity that got fixed was that we were snapshotting textview child widgets (rarely used) twice in the GtkTextView thanks to an observant bug reporter. This improved the gutter rendering times for things like GtkSourceView.
I also tried to help define some of the GtkAccessibleText API so we can potentially be lazy from widget implementations. The goal here is to have zero overhead if you’re not using accessibility technology and still be fast if you are.
I also added a fast path for the old GL renderer for masked textures. But that never saw a release as the default renderer now that NGL is in place, so not such a big deal. It helped for Ptyxis/VTE while it lasted though.
GSK also saw a bunch of little fixes to avoid hitting the type system so hard.
libpeas 2.0
Libpeas got a major ABI bump which came with a lot of cleaning up of the ABI contracts. But even better, it got a GJS (SpiderMonkey) plugin loader for writing plugins in JavaScript.
GNOME Builder uses this for plugins now instead of PyGObject.
VTE Performance
As my monitor resolution got higher my terminal interactivity in Builder was lessened. Especially while on Wayland. It got to the point that latency was causing me to miss-type frequently.
Thankfully, I had just finished work on Sysprof so I could take a look.
Builder is GTK 4 of course, and it turned out VTE was drawing with Cairo and therefore spending significant time on the CPU drawing and significant memory bandwidth uploading the full texture to the GPU each frame.
Something I did find funny was how up in arms people got about a prototype I wrote to find the theoretical upper bounds of PTY performance for a terminal emulator. How dare I do actual research before tackling a new problem domain for me.
In the end I finally figured out how to properly use GskTextNode directly with PangoGlyphString to avoid PangoLayout. A trick I’d use again in GtkSourceView to speed up line number drawing.
Along with modernizing the drawing stack in VTE I took the chance to optimize some of the cross-module performance issues. VTE performance is in pretty good shape today and will certainly get even better in it’s capable maintainers hands. They were extremely friendly and helpful to a newcomer showing up to their project with grand ideas of how to do things.
GNOME Terminal
To validate all the VTE performance work I also ported the venerable GNOME Terminal to GTK 4. It wasn’t quite ready to ship in concert with GNOME 46 but I’m feeling good about it’s ability to ship during GNOME 47.
Ptyxis
For years I had this prototype sitting around for a container-based terminal built on top of the Builder internals. I managed to extract that as part of my VTE performance work.
It’s a thing now, and it’s pretty good. I can’t imagine not using it day-to-day now.
VTE Accessibility
Now that I have a GTK 4 terminal application to maintain the only responsible thing for me to do is to make sure that everyone can use it. So I wrote a new accessibility layer bridging VteTerminal to GtkAccessibleText in GTK.
Podman and PTY
While working on Ptyxis I realized that Podman was injecting an extra PTY into the mix. That makes foreground process tracking extremely difficult so I advocated the ability to remove it from Podman. That has now happened so in future versions of Ptyxis I plan to prod Podman into doing the right thing.
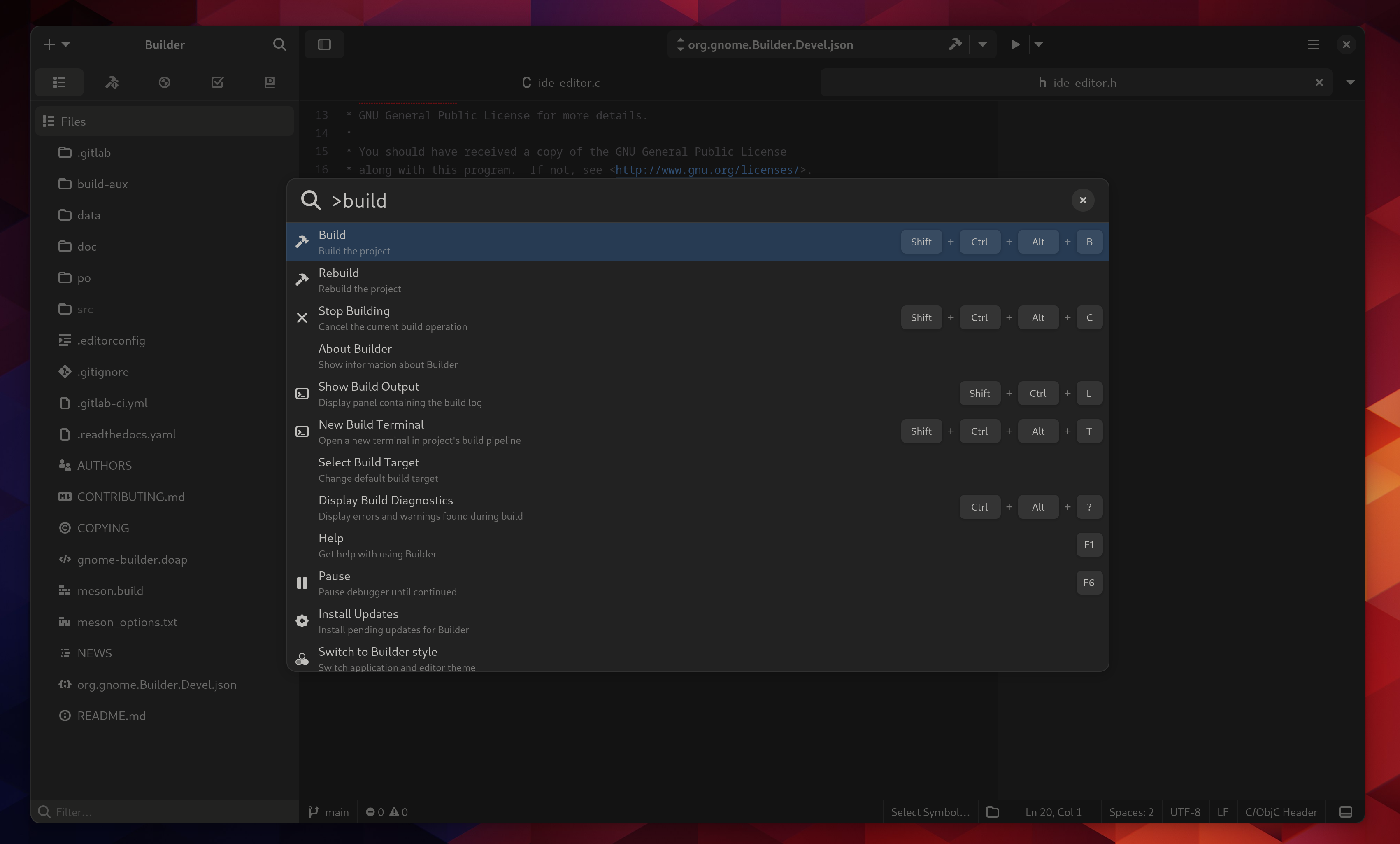
GNOME Builder
All sorts of nice little quality of life improvements happened in Builder. More control over the build pipeline and application runtime environment make it easier to integrate with odd systems and configurations.
The terminal work in Ptyxis came back into Builder so we got many paper cuts triaged. You’ll also notice many new color palettes that ship with Builder which were generated from palettes bundled with Ptyxis.
Memory usage has also been reduced even further.
Biased Ref Counting
I wrote an implementation of Biased Ref Counting to see how it would perform with GObject/GTK. Long story short the integration complexities probably out-weigh most of the gains.
Removing Twitter, Mastodon, and Matrix
I removed my social media accounts this year and it’s lovely. Cannot recommend it enough.