With my new phone, I needed to migrate all the WiFi settings. For some reason, it seems to be hard to export WiFi configuration from Android and import it in another. The same holds true for GNOME, I guess.
The only way of getting WiFi configuration into your Android phone (when not being able to write the wpa_supplicant file) seems to be barcodes! When using the barcode reader application, you can scan a code in a certain format and the application would then create a wifi configuration for you.
I quickly cooked up something that allows me to “export” my laptop’s NetworkManager WiFis via a QR code. You can run create_barcode_from_wifi.py and it creates a barcode of your currently active configuration, if any. You will also see a list of known configurations which you can then select via the index. The excellent examples in the NetworkManager’s git repository helped me to get my things done quickly. There’s really good stuff in there.
I found out that I needed to explicitely render the QR code black on white, otherwise the scanning app wouldn’t work nicely. Also, I needed to make the terminal’s font smaller or go into fullscreen with F11 in order for the barcode to be printed fully on my screen. If you have a smaller screen than, say, 1360×768, I guess you will have a problem using that. In that case, you can simply let PyQRCode render a PNG, EPS, or SVG. Funnily enough, I found it extremely hard to print either of those formats on an A4 sheet. The generated EPS looks empty:
Printing that anyway through Evince makes either CUPS or my printer die. Converting with ImageMagick, using convert /tmp/barcode.eps -resize 1240x1753 -extent 1240x1753 -gravity center -units PixelsPerInch -density 150x150 /tmp/barcode.eps.pdf makes everything very blurry.
Using the PNG version with Eye of GNOME does not allow to scale the image up to my desired size, although I do want to print the code as big as possible on my A4 sheet:
Now you could argue that, well, just render your PNG bigger. But I can’t. It seems to be a limitation of the PyQRCode library. But there is the SVG, right? Turns out, that eog still doesn’t allow me to print the image any bigger. Needless to say that I didn’t have inkscape installed to make it work… So I went ahead and used LaTeX instead…
Anyway, you can get the code on github and gitlab. I guess it might make sense to push it down to NetworkManager, but as I am more productive in writing Python, I went ahead with it without thinking much about proper integration.
After being able to produce Android compatible WiFi QR codes, I also wanted to be able to scan those with my GNOME Laptop to not having to enter passwords manually. The ingredients for a solution to this problem is parsing the string encoded as a barcode and creating a connection via the excellent NetworkManager API. Creating the connection is comparatively easy, given that an example already exists. Parsing the string, however, is a bit more complex than I initially thought. The grammar of that WiFi encoding language is a bit insane in the sense that it allows multiple encodings for the same thing and that it is not clear to encode (or decode) certain networks. For example, imagine your password is 12345678. The encoding format now wants to know whether that is ASCII characters or the hex encoded passphrase (i.e. the hex encoded bytes 0x12,0x34,0x56,0x78). In the former case, the encoded passphrase must be quoted with double quotes, e.g. P:"12345678";. Fair enough. Now, let’s imagine the password is "12345678" (yes, with the quotes). Then you need to hex encode that ASCII string to P:22313233343536373822. But, as it turns out, that’s not what people have done, so I have seen quite a few weird QR codes for Wifis out there 🙁
Long story short, the scan_wifi_code.py program should also scan your barcode and create a new WiFi connection for you.
Do you have any other ideas how to migrate wifi settings from one device to another?
On 2015-10-04 it was announced that the governing body of the GNOME Foundation, the Board, has a vacant seat. That body was elected about 15 weeks earlier. The elections are very democratic, they use an STV system to make as many votes as possible count. So far, no replacement has been officially announced. The question of what strategy to use in order to find the replacement has been left unanswered. Let me summarise the facts and comment on the strategy I wish the GNOME project to follow.
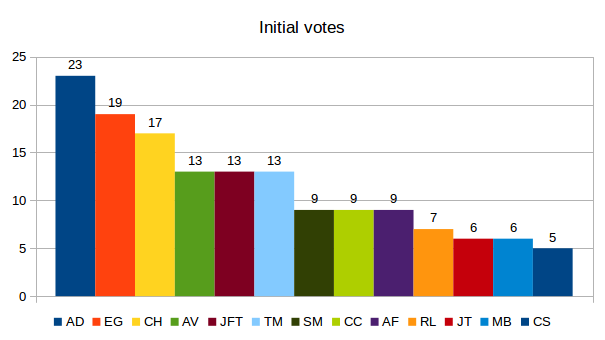
The STV system used can be a bit hard to comprehend, at first, so let me show you the effects of an STV system based on the last GNOME elections. With STV systems, the electorate can vote for more than one candidate. An algorithm then determines how to split up the votes, if necessary. Let’s have a look at the last election’s first votes:
We see the initial votes, that is, the number of ballots in which a candidate was chosen first. If a candidate gets eliminated, either because the number of votes is sufficient to get elected or because the candidate has the least votes and cannot be elected anymore, the vote of the ballot is being transferred onto the next candidate.
In the chart we see that the electorate chose to place 19 or more votes onto two candidates who got directly elected. Overall, six candidates have received 13 or more votes. Other candidates have at least 30% less votes than that. If we had a “simple” voting mechanism, the result would be the seven candidates with the most votes. I would have been one of them.
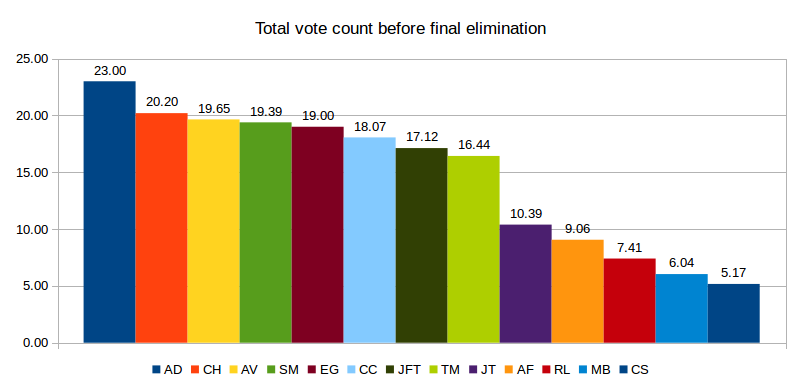
But that’s not how our voting system works, because, as we can see below, the picture of accumulated votes looks differently just before eliminating the last candidate (i.e. me):
If you compare the top seven now, you observe that one candidate received votes from other candidates who got eliminated and managed to get in.
We can also see from the result that the final seat was given to 17.12 votes and that the first runner-up had 16.44 votes. So this is quite close. The second runner-up received 10.39 votes, or 63% of the votes of the first runner-up (so the first runner-up received 158% of the votes of the second runner-up).
We can also visually identify this effect by observing a group of eight which accumulated the lion’s share of the votes. It is followed by a group of five.
Now one out of the seven elected candidates needed to drop out, creating a vacancy. The Foundation has a set of rules, the bylaws, which regulate vacancies. They are pretty much geared towards maintaining an operational state even with a few directors left and do not mandate any particular behaviour, especially not to follow the latest election results.
But.
Of course this is not about what is legally possible, because that’s the baseline, the bare minimum we expect to see. The GNOME Foundation’s Board is one of the few democratically elected bodies. It is a well respected entity in industry as well as other Free Software communities. I want it to stay that way. Most things in Free Software are not very democratic; and that’s perfectly fine. But we chose to have a very democratic system around the governing body and I think that it would leave a bad taste if the GNOME Foundation chooses to not follow these rather young election results. I believe that its reputation can be damaged if the impression of forming a cabal, of not listening to its own membership, prevails. I interpret the results as a strong statement of its membership for those eight candidates. GNOME already has to struggle with accusations of it not listening to its users. I’d rather want to get rid of it, not fueling it by extending it to its electorate. We’re in the process of acquiring sponsors for our events and I don’t think it’s received well if the body ignores its own processes. I’d also rather value the membership more rather than producing arguments for those members who chose to not vote at all and try to increase the number of members who actually vote.
The second day was opened by Leigh Honeywell and she was talking about how to secure an Open Future. An interesting case study, she said, was Heartbleed. Researchers found that vulnerability and went through the appropriate vulnerability disclosure channels, but the information leaked although there was an embargo in place. In fact, the bug proofed to be exploited for a couple of months already. Microsoft, her former employer, had about ten years of a head start in developing a secure development life-cycle. The trick is, she said, to have plans in place in case of security vulnerabilities. You throw half of your plan away, anyway, but it’s good to have that practice of knowing who to talk to and all. She gave a few recommendations of which she thinks will enable us to write secure code. Coders should review, learn, and speak up if they feel uncomfortable with a piece of code. Managers could take up on what she called “smells” when people tend to be fearful about their code. Of course, MicroSoft’s SDL also contains many good practices. Her minimal set of practices is to have a self-assessment in place to determine if something needs security review, have an up-front threat modelling that is kept up to date as things evolve, have a security checklist like Mozilla’s or OWASP’s, and have security analysis built into CI process.
The container panel was led by Jeo Zonker Brockmeier who started the discussion by stating that we’ve passed the cloud hype and containers are all the rage now. The first question he shot at the panellists was whether containers were ready at all to be used for production. The panellists were, of course, all in agreement that they are, although the road ahead is still a bit bumpy. One issue, they identified, was image distribution. There are, apparently, two types of containers. Application containers and System containers. Containers used to be a lightweight VM with a full Linux system. Application Containers, on the other hand, only run your database instance. They see application containers as replacing Apps in the future. Other services like databases are thus not necessarily the task of Application containers. One of the panellists was embracing dockerhub as a similar means to RPM or .deb packages for distributing software, but, he said, we need to solve the problem of signing and trusting. He was comparing the trust issue with packages he had installed on his laptop. When he installed a package, he didn’t check what was inside the packages his OS downloaded. Well, I guess he missed that people put trust in the distribution instead of random people on the Internet who put up an image for everybody to download. Anyway, he wanted Docker to be a form of trusted entity like Google or Apple are for their app stores which are distributing applications. I don’t know how they could have missed the dependency resolution and the problem of updating lower level libraries, maybe that problem has been solved already…
Intel’s Mark was talking on how Open Source was fuelling the Internet of Things. He said that trust was an essential aspect of devices that have access to personal or sensitive data like access to your house. He sees the potential in IoT around vaccines which is a connection I didn’t think of. But it makes somewhat sense. He explained that vaccines are quite sensitive to temperature. In developing countries, up to 30% of the vaccines spoil, he said, and what’s worse is that you can’t tell whether the vaccine is good. The IoT could provide sensors on vaccines which can monitor the conditions. In general, he sees the integration of diverse functionality and capabilities of IoT devices will need new development efforts. He didn’t mention what those would be, though. Another big issue, he said, was the updatetability, he said. Even with smaller devices, updates must not be neglected. Also, the ability of these devices to communicate is a crucial component, too, he said. It must not be that two different light bulbs cannot talk to their controller. That sounds like this rant.
Next, Bradley talked about GPL compliance. He mentioned the ThinkPinguin products as a pristine example for a good GPL compliant “complete corresponding source”. He pointed the audience to the Compliance.guide. He said that it’s best to avoid the offer for source. It’s better to include the source with the product, he said, because the offer itself creates ongoing obligations. For example, your call centre needs to handle those requests for the next three years which you are probably not set up to do. Also, products have a typically short lifespan. CCS requires good instructions how to build. It’s not only automated build tools (think configure, make, make install). You should rather think of a script as a movie or play script. The test to use on your potential CCS is to give your source release to another developer of some other department and try whether that person can build the code with your instructions. Anyway, make install does usually not work on embedded anyway, because you need to flash the code. So make sure to include instructions as to how to get the software on the device. It’s usually not required to ship the tool-chain as long as you give instructions as to what compiler to use (and how it was configured). If you do include a compiler, you might end up having more obligations because GCC, for example, is itself GPL licensed. An interesting question came up regarding specialised hardware needed to build or flash the software. You do not need to include anything “tool-chain-like” as long as you have instructions as to the requirements what the user needs to obtain.
Samsung’s Krzysztof was talking about USB in Linux. He said, it is the most common external interface in the world. It’s like the Internet in the sense that it provides services in a client-server architecture. USB also provides services. After he explained what the USB actually is how the host interacts with devices, he went on to explain the plug and play aspect of USB. While he provided some rather low-level details of the protocol, it was a rather high level in the sense that it was still the very basic USB protocol. He didn’t talk too much on how exactly the driver is being selected, for example. He went on to explain the BadUSB attack. He said that the vulnerability basically results from the lack of user interaction when plugging in a device and loading its driver. One of his suggestions were to not connect “unknown devices”, which is hard because you actually don’t know what “services” the device is implementing. He also suggested to limit the number of input sources to X11. Most importantly, though, he said that we’d better be using device authorisation to explicitly allow devices before activating them. That’s good news, because we are working on it! There are, he said, patches available for allowing certain interfaces, instead of the whole device, but they haven’t been merged yet.
Jeff was talking about applying Open Source Principles to hardware. He began by pointing out how many processors you don’t get to see, for example in your hard disk, your touchpad controller, or the display controller. These processors potentially exfiltrate information but you don’t really know what they do. Actually, these processors are about owning the owner, the consumer, to then sell them stuff based on that exfiltrated big data, rather than to serve the owner, he said. He’s got a project running to build devices that you not only own, but control. He mentioned IoT as a new battleground where OpenHardware could make an interesting contestant. FPGAs are lego for hardware which can be used easily to build your functionality in hardware, he said. He mentioned that the SuperH patents have now expired. I think he wants to build the “J-Core CPU” in software such that you can use those for your computations. He also mentioned that open hardware can now be what Linux has been to the industry, a default toolkit for your computations. Let’s see where his efforts will lead us. It would certainly be a nice thing to have our hardware based on publicly reviewed designs.
The next keynote was reserved for David Mohally from Huawei. He said he has a lab in which they investigate what customers will be doing in five to ten years. He thinks that the area of network slicing will be key, because different businesses needs require different network service levels. Think your temperature sensor which has small amounts of data in a bursty fashion while your HD video drone has rather high volume and probably requires low latency. As far as I understood, they are having network slices with smart meters in a very large deployment. He never mentioned what a network slice actually is, though. The management of the slices shall be opened up to the application layer on top for third parties to implement their managing. The landscape, he said, is changing dramatically from what he called legacy closed source applications to open source. Let’s hope he’s right.
It was announced that the next LinuxCon will happen in Berlin, Germany. So again in Germany. Let’s hope it’ll be an event as nice as this one.
The next, very interesting, presentation was given by Sean Gourley, the founder of Quid, a business intelligence analytics company. He talked about the limits of human cognition and how algorithms help to exploit these limits. The limit is the speed of your thinking. He mentioned that studies measured the blood flow across the brain when making decisions which found differences depending on how proficient you are at a given task. They also found that you cannot be quicker than a certain limit, say, 650ms. He continued that the global financial market is dominated by algorithms and that a fibre cable from New York to London costs 300 million dollars to save 5 milliseconds. He then said that these algorithms make decisions at a speed we are unable to catch up with. In fact, the flash crash of 2:45 is inexplicable until today. Nobody knows what happened that caused a loss of trillions of dollars. Another example he gave was the crash of Knight Capital which caused a loss of 440 million dollars in 45 minutes only because they updated their trading algorithms. So algorithms are indeed controlling our lives which he underlined by saying that 61% of the traffic on the Internet is not generated by humans. He suggested that Bots would not only control the financial markets, but also news reading and even the writing of news. As an example he showed a Google patent for auto generating social status updates and how Mexican and Chinese propaganda bots would have higher volume tweets than humans. So the responsibilities are shifting and we’d be either working with an algorithm or for one. Quite interesting thought indeed.
Next up was IBM on Transforming for the Digital Economy with Open Technology which was essentially a gigantic sales pitch for their new Power architecture. The most interesting bit of that presentation was that “IBM is committed to open”. This, she said, is visible through IBM’s portfolio and through its initiatives like the IBM Academic Initiative. OpenPower Foundation is another one of those. It takes the open development model of software and takes it further to everything related to the Power architecture (e.g. chip design), she said. They are so serious about being open, that they even trademarked “Open by Design“…
Then, the drone code people presented on their drone project. They said that they’ve come a long way since 2008 and that the next years are going to fundamentally change the drone scene as many companies are involved now. Their project, DroneCode, is a stack from open hardware to flight control and the next bigger thing will be CAN support, which is already used in cards, planes, and other vehicles. The talk then moved to ROS, the robot operating system. It is the lingua franca for robotic in academia.
Matthew Garret talked on securing containers. He mentioned seccomp and what type of features you can deprive processes of. Nowadays, you can also reason about the arguments for the system call in question, so it might be more useful to people. Although, he said, writing a good seccomp policy is hard. So another mechanism to deprive processes of privileges is to set capabilities. It allows you to limit the privileges in a more coarse grained way and the behaviour is not very well defined. The combination of capabilities and seccomp might have surprising results. For example, you might be allowing the mknod() call, but you then don’t have the capability to actually execute it or vice versa. SELinux was next on his list as a mechanism to secure your containers. He said that writing SELinux policy is not the most fun thing in the world. Another option was to run your container in a virtual machine, but you then lose some benefits such as introspection of fine grained control over the processes. But you get the advantages of more isolation. Eventually, he asked the question of when to use what technology. The performance overhead of seccomp, SELinux, and capabilities are basically negligible, he said. Fully virtualising is usually more secure, he said, but the problem is that you have more complex infrastructure which tend to attract bugs. He also mentioned GRSecurity as a means of protecting your Linux kernel. Let’s hope it’ll be merged some day.
Canonical’s Daniel Watkins then talked on cloud-init. He said it runs in three stages. Init, config, and final in which init sets up networking, config does the actual configuration of your services, final is for the things that eventually need to be done. The clound-init architecture is apparently quite flexible and versatile. You can load your own configuration and user-data modules so that you can set up your cloud images as you like. cloud-init allows you get rid of custom images such that you can have confidence in your base image working as intended. In fact, it’s working not only with BSDs but also with Windows images. He said, it is somewhat similar to tools like Ansible, so if you are already happily using one of those, you’re good.
An entertaining talk was given by Florian Haas on LXC and containers. He talked about tricks managing your application containers and showed a problem when using a naive chroot which is that you get to see the host processes and networking information through the proc filesystem. With LXC, that problem is dealt with, he said. But then you have a problem when you update the host, i.e. you have to take down the container while the upgrade is running. With two nodes, he said, you can build a replication setup which takes care of failing over the node while it is upgrading. He argued that this is interesting for security reasons, because you can upgrade your software to not be vulnerable against “the latest SSL hack” without losing uptime. Or much of it, at least… But you’d need twice the infrastructure to run production. The future, he said, might be systemd with it’s nspawn tool. If you use systemd all the way, then you can use fleet to manage the instances. I didn’t take much away, personally, but I guess managing containers is all the rage right now.
Next up was Michael Hausenblas on Filesystems, SQL and NoSQL with Apache Mesos. I had briefly heard of Mesos, but I really didn’t know what it was. Not that I’m an expert now, but I guess I know that it’s a scheduler you can use for your infrastructure. Especially your Apache stack. Mesos addresses the problem of allocating resources to jobs. Imagine you have several different jobs to execute, e.g. a Web server, a caching layer, and some number crunching computation framework. Now suppose you want to increase the number crunching after hours when the Web traffic wears off. Then you can tell Mesos what type of resources you have and when you need that. Mesos would then go off and manage your machines. The alternative, he said, was to manually SSH into the machines and reprovision them. He explained some existing and upcoming features of Mesos. So again, a talk about managing containers, machines, or infrastructure in general.
The following Kernel panel didn’t provide much information to me. The moderation felt a bit stiff and the discussions weren’t really enganged. The topics mainly circled around maintainership, growth, and community.
SuSE’s Ralf was then talking on DevOps. He described his DevOps needs based on a cycle of planning, coding, building, testing, releasing, deploying, operating, monitoring, and then back to planning. When bringing together multiple projects, he said, they need to bring two independent integration loops together. When doing DevOps with a customer, he mentioned some companies who themselves provide services to their customers. In order to be successful when doing DevOps, you need, he said, Smart tools, Process automation, Open APIs, freedom of choice, and quality control are necessary. So I guess he was pitching for people to use “standards”, whatever that exactly means.
I awaited the next talk on Patents and patent non aggression. Keith Bergelt, from OIN talked about ten years of the Open Invention Network. He said that ten years ago Microsoft sued Linux companies to hinder Linux distribution. Their network was founded to embrace patent non-aggression in the community. A snarky question would have been why it would not be simply enough to use GPLv3, but no questions were admitted. He said that the OIN has about 1750 licensees now with over a million patents being shared. That’s actually quite impressive and I hope that small companies are being protected from patent threats of big players…
That concluded the first day. It was a lot of talks and talking in the hallway. Video recordings are said to be made available in a couple of weeks. So keep watching the conference page.
I attended this year’s mrmcd, a cozy conference in Darmstadt, Germany. As inthepreviousyears, it’s a 350 people event with a relaxed atmosphere. I really enjoy going to these mid-size events with a decent selection of talks and attentive guests.
The conference was opened by Paolo Ferri’s Keynote. He is from the ESA and gave a very entertaining talk about the Rosetta mission. He mentioned the challenges involved in launching a missile for a mission to be executed ten years later. It was very interesting to see what they have achieved over a few hundred kilometers distance. Now I want to become a space pilot, too 😉
The next talk was on those tracking devices for your fitness. Turns out, that these tracking devices may actually track you and that they hence pose a risk for your privacy. Apparently fraud is another issue for insurance companies in the US, because some allow you to get better rates when you upload your fitness status. That makes those fitness trackers an interesting target for both people wanting to manipulate their walking statistics to get a better premium for health care and attackers who want to harm someone by changing their statistics.
Concretely, he presented, these devices run with Bluetooth 4 (Smart) which allows anyone to see the device. In addition, service discovery is also turned on which allows anyone to query the device. Usually, he said, no pin is needed anymore to connect to the device. He actually tested several devices with regard to several aspects, such as authentication, what data is stored, what is sent to the Internet and what security mechanisms the apps (for a phone) have been deployed. Among the tested devices were the XiaomMi Miband, the Fitbit, or the Huawei TalkBand B1. The MiBand was setting a good example by disabling discovery once someone has connected to the device. It also saves the MAC address of the phone and ignores others. In order to investigate the data sent between a phone and a band, they disassembled the Android applications.
Muzy was telling a fairytale about a big data lake gone bad.
He said that data lakes are a storage for not necessarily structured data which allow extraction of certain features in an on-demand fashion and that the processed data will then eventually end up in a data warehouse in a much more structured fashion. According to him, data scientists then have unlimited access to that data. That poses a problem and in order to secure the data, he proposed to introduce another layer of authorization to determine whether data scientists are allowed to access certain records. That is a bit different from what exists today: Encrypt data at rest and encrypt in motion. He claimed that current approaches do not solve actual problems, because of, e.g. key management questions. However, user rights management and user authorization are currently emerging, he said.
Later, he referred on Apache Spark. With big data, he said, you need to adapt to a new programming paradigm away from a single worker to multiple nodes, split up work, handling errors and slow tasks. Map reduce, he said, is one programming model. A popular framework for writing in a such a paradigm is Apache’s Hadoop, but there are more. He presented Apache Spark. But it only begins to make sense if you want to analyse more data than you can fit in your RAM, he said. Spark distributes data for you and executes operations on it in a parallel manner, so you don’t need to care about all of that. However, not all applications are a nice fit for Spark, he mentioned. He gave high performance weather computations as such as example. In general, Spark fits well if IPC not required.
The conference then continued with two very interesting talks on Bahn APIs. derf presented on public transport APIs like EFA, HAFAS, and IRIS. These APIs can do things like routing from A to B or answer questions such as which trains are running from a given station. However, these APIs are hardly documented. The IRIS-system is the internal Bahn-API which is probably not supposed to be publicly available, but there is a Web page which exposes (bits) of the API. Others have used that to build similar, even more fancy things. Anyway, he used these APIs to query for trains running late. The results were insightful and entertaining, but have not been released to the general public. However, the speakers presented a way to query all trains in Germany. Long story short: They use the Zugradar which also contains the geo coordinates. They acquired 160 millions datasets over the last year which is represented in 80GB of JSON. They have made their database available as ElasticSearch and Kibana interface. The code it at Github. That is really really good stuff. I’m already in the process of building an ElasticSearch and Spark cluster to munch on that data.
Yours truly also had a talk. I was speaking on GNOME Keysign. Because the CCC people know how to run a great conference, we already have recordings (torrent). You get the slides here. Those of you who know me don’t find the content surprising. To all others: GNOME Keysign is a tool for signing OpenPGP Keys. New features include the capability to sign keys offline, that is, you present a file with a key and you have it signed following best practices.
Another talk I had, this time with a colleague of mine, was on Searchable Encryption. Again, the Video already exists. The slides are probably less funny than they were during the presentation, but hopefully still informative enough to make some sense out of them. Together we mentioned various existing cryptographic schemes which allow you to have a third party execute search operations on your encrypted data on your behalf. The most interesting schemes we showed were Song, Wagner, Perrig and Cash et al..
Thanks again to the organisers for this nice event! I’m looking forward to coming back next year.
This summer, GUADEC, the GNOME Users and Developers Conference took place in Gothenburg, Sweden. It’s a lovely city, especially in summer, with nice people, excellent beers, and good infrastructure. Fun fact: Unisex toilet seem to be very popular in Gothenburg. The conference was hosted in sort of a convention centre and was well equipped to serve our needs. I guess we’ve been around 150 people to come together in order to discuss and celebrate our favourite Free Software project: GNOME.
One of the remarkable talks I attended was given by Matthias Kirschner from the FSFE presented on software freedom and how is concerned about the computer as a general purpose machine. So his talk was title “The computer as a Universal Machine”. He was afraid that the computing machines we are using become more and more special purpose devices rather than a general purpose machine. He gave examples of how he thinks that has happened, like corporations hiding the source code or otherwise limit access to change the behaviour of the computing machines we are using. Other examples were media with Digital Restrictions Management. Essentially it is about removing features instead of widening the functionality. As such, SIM locks also served an example. With SIM locks, you cannot change your SIM card when, say, you are on holidays. More examples he gave were the region code of DVDs or copy restrictions on CD-ROMs. He was also referring to the Sony CD story from a couple of years ago when they infected buyers of their CD-ROMs or the Amazon fiasco where they deleted books on their reader devices. Essentially, these companies are trying to put the user into the back-seat when it comes to take control over your devices.
While protecting the owner of the computer sounds useful in a few scenarios, like with ATMs, it can be used against the owner easily, if the owner cannot exercise control over what the machine considers trusted. A way to counter this, he said, is to first simply not accept the fact that someone else is trying to limit the amount of control you can exercise over your machines. Another thing to do, according to him, is to ask for Free Software when you go shopping, like asking for computers with a pre-installed GNU/Linux system. I liked most parts of the talk, especially because of the focus on Free Software. Although I also think that for most parts he was preaching to the choir. But I still think that it’s important to remind ourselves of our Free Software mission.
Impressively enough, you can already watch most of the Videos! It’s quite amazing that they have already been cut and post-process so that we can watch all the things that we missed. I am especially looking forward to Christian’s talk on Builder and the Design session.
I really like going to GUADEC, because it is so much easier and more pleasant to communicate with people in-person rather than on low bandwidth channels such as IRC or eMail. I could connect my students with all these smart people who know much more about the GNOME stack than I do. And I was able to ask so many things I hadn’t understood. Let’s hope there will be GUADEC next year! If you are interested in hosting next year’s edition, you should consider submitting a bid!
On my travel back I realised that the Frankfurt Airport is running Ubuntu:
I want to thank the GNOME Foundation for sponsoring my travel to GUADEC 2015.
For a couple of days now, I am an owner of a Siswoo Longbow C55. It’s a 5.5″ Chinese smartphone with an interesting set of specs for the 130 EUR it costs. For one, it has a removable battery with 3300mAh. That powers the phone for two days which I consider to be quite good. A removable battery is harder and harder to get these days :-/ But I absolutely want to be able to replace the battery in case it’s worn out, hard reboot it when it locks up, or simply make sure that it’s off. It also has 802.11a WiFi which seems to be rare for phones in that price range. Another very rare thing these days is an IR interface. The Android 5.1 based firmware also comes with a remote control app to control various TVs, aircons, DVRs, etc. The new Android version is refreshing and is fun to use. I don’t count on getting updates though, although the maker seems to be open about it.
The does not have NFC, but something called hotknot. The feature is described as being similar to NFC, but works with induction on the screen. So when you want to connect two devices, you need to make the screens touch. I haven’t tried that out yet, simply because I haven’t seen anyone with that technology yet. It also does not have illuminated lower buttons. So if you’re depending on that then the phone does not work for you. A minor annoyance for me is the missing notification LED. I do wonder why such a cheap part is not being built into those cheap Chinese phones. I think it’s a very handy indicator and it annoys me to having to power on the screen only to see whether I have received a message.
I was curious whether the firmware on the phone matches the official firmware offered on the web site. So I got hold of a GNU/Linux version of the flashtool which is Qt-based BLOB. Still better than running Windows… That tool started but couldn’t make contact with the phone. I was pulling my hair out to find out why it wouldn’t work. Eventually, I took care of ModemManager, i.e. systemd disable ModemManager or do something like sudo mv /usr/share/dbus-1/system-services/org.freedesktop.ModemManager1.service{,.bak} and kill modem-manager. So apparently it got in the way when the flashtool was trying to establish a connection. I have yet to find out whether this
works for me:
ACTION!="add|change|move", GOTO="mm_custom_blacklist_end"
SUBSYSTEM!="usb", GOTO="mm_custom_blacklist_end"
ENV{DEVTYPE}!="usb_device", GOTO="mm_custom_blacklist_end"
ATTR{idVendor}=="0e8d", ATTR{idProduct}=="2000", ENV{ID_MM_DEVICE_IGNORE}="1"
LABEL="mm_custom_blacklist_end"
I “downloaded” the firmware off the phone and compared it with the official firmware. At first I was concerned because they didn’t hash to the same value, but it turns out that the flash tool can only download full blocks and the official images do not seem to be aligned to full blocks. Once I took as many bytes of the phone’s firmware as the original firmware images had, the hash sums matched. I haven’t found a way yet to get full privileges on that Android 5.1, but given that flashing firmware works (sic!) it should only be a matter of messing with the system partition. If you have any experience doing that, let me know.
The device performs sufficiently well. The battery power is good, the 2GB of RAM make it unlikely for the OOM killer to stop applications. What is annoying though is the sheer size of the device. I found 5.0″ to be too big already, so 5.5″ is simply too much for my hands. Using the phone single handedly barely works. I wonder why there are so many so huge devices out there now. Another minor annoyance is that some applications simply crash. I guess they don’t handle the 64bit architecture well or have problems with Android 5.1 APIs.
FWIW: I bought from one of those Chinese shops with a European warehouse and their support seems to be comparatively good. My interaction with them was limited, but their English was perfect and, so far, they have kept what they promised. I pre-ordered the phone and it was sent a day earlier than they said it would be. The promise was that they take care of the customs and all and they did. So there was absolutely no hassle on my side, except that shipping took seven days, instead of, say, two. At least for my order, they used SFBest as shipping company.
Do you have any experience with (cheap) Chinese smartphones or those shops?
Recently, I’ve been to Hong Kong for Open Source Hong Kong 2015, which is the heritage of the GNOME.Asia Summit 2012 we’ve had in Hong Kong. The organisers apparently liked their experience when organising GNOME.Asia Summit in 2012 and continued to organise Free Software events. When talking to organisers, they said that more than 1000 people registered for the gratis event. While those 1000 were not present, half of them are more realistic.
Olivier from Amazon Web Services Klein was opening the conference with his keynote on Big Data and Open Source. He began with a quote from RMS: about the “Free” in Free Software referring to freedom, not price. He followed with the question of how does Big Data fit into the spirit of Free Software. He answered shortly afterwards by saying that technologies like Hadoop allow you to mess around with large data sets on commodity hardware rather than requiring you to build a heavy data center first. The talk then, although he said it would not, went into a subtle sales pitch for AWS. So we learned about AWS’ Global Infrastructure, like how well located the AWS servers are, how the AWS architecture helps you to perform your tasks, how everything in AWS is an API, etc. I wasn’t all too impressed, but then he demoed how he uses various Amazon services to analyse Twitter for certain keywords. Of course, analysing Twitter is not that impressive, but being able to do that within a few second with relatively few lines of code impressed me. I was also impressed by his demoing skills. Of course, one part of his demo failed, but he was reacting very professionally, e.g. he quickly opened a WiFi hotspot on his phone to use that as an alternative uplink. Also, he quickly grasped what was going on on his remote Amazon machine by quickly glancing over netstat and ps output.
The next talk I attended was on trans-compiling given by Andi Li. He was talking about Haxe and how it compiles to various other languages. Think Closure, Scala, and Groovy which all compile to Java bytecode. But on steroids. Haxe apparently compiles to code in another language. So Haxe is a in a sense like Emcripten or Vala, but a much more generic source-to-source compiler. He referred about the advantages and disadvantages of Haxe, but he lost me when he was saying that more abstraction is better. The examples he gave were quite impressive. I still don’t think trans-compiling is particularly useful outside the realm of academic experiments, but I’m still intrigued by the fact that you can make use of Haxe’s own language features to conveniently write programs in languages that don’t provide those features. That seems to be the origin of the tool: Flash. So unless you have a proper language with a proper stdlib, you don’t need Haxe…
From the six parallel tracks, I chose to attend the one on BDD in Mediawiki by Baochuan Lu. He started out by providing his motivation for his work. He loves Free/Libre and Open Source software, because it provides a life-long learning environment as well as a very supportive community. He is also a teacher and makes his students contribute to Free Software projects in order to get real-life experience with software development. As a professor, he said, one of his fears when starting these projects was being considered as the expert™ although he doesn’t know much about Free Software development. This, he said, is shared by many professors which is why they would not consider entering the public realm of contributing to Free Software projects. But he reached out to the (Mediawiki) community and got amazing responses and an awful lot of help.
He continued by introducing to Mediawiki, which, he said, is a platform which powers many Wikimedia Foundation projects such as the Wikipedia, Wikibooks, Wikiversity, and others. One of the strategies for testing the Mediawiki is to use Selenium and Cucumber for automated tests. He introduced the basic concepts of Behaviour Driven Development (BDD), such as being short and concise in your test cases or being iterative in the test design phase. Afterwards, he showed us how his tests look like and how they run.
The after-lunch talk titled Data Transformation in Camel Style was given by Red Hat’s Roger Hui and was concerned with Apache Camel, an “Enterprise Integration” software. I had never heard of that and I am not much smarter know. From what I understood, Camel allows you to program message workflows. So depending on the content of a message, you can make it go certain ways, i.e. to a file or to an ActiveMQ queue. The second important part is data transformation. For example, if you want to change the data format from XML to JSON, you can use their tooling with a nice clicky pointy GUI to drag your messages around and route them through various translators.
From the next talk by Thomas Kuiper I learned a lot about Gandi, the domain registrar. But they do much more than that. And you can do that with a command line interface! So they are very tech savvy and enjoy having such customers, too. They really seem to be a cool company with an appropriate attitude.
The next day began with Jon’s Kernel Report. If you’re reading LWN then you haven’t missed anything. He said that the kernel grows and grows. The upcoming 4.2 kernel, probably going to be released on August 23rd. might very well be the busiest we’ve seen with the most changesets so far. The trend seems to be unstoppable. The length of the development cycle is getting shorter and shorter, currently being at around 63 days. The only thing that can delay a kernel release is Linus’ vacation… The rate of volunteer contribution is dropping from 20% as seen for 2.6.26 to about 12% in 3.10. That trend is also continuing. Another analysis he did was to look at the patches and their timezone. He found that that a third of the code comes from the Americas, that Europe contributes another third, and so does Australasia. As for Linux itself, he explained new system calls and other features of the kernel that have been added over the last year. While many things go well and probably will continue to do so, he worries about the real time Linux project. Real time, he said, was the system reacting to an external event within a bounded time. No company is supporting the real time Linux currently, he said. According to him, being a real time general purpose kernel makes Linux very attractive and if we should leverage that potential. Security is another area of concern. 2014 was the year of high profile security incidents, like various Bash and OpenSSL bugs. He expects that 2015 will be no less interesting. Also because the Kernel carries lots of old and unmaintained code. Three million lines of code haven’t been touch in at least ten years. Shellshock, he said, was in code more than 20 years old code. Also, we have a long list of motivated attackers while not having people working on making the Kernel more secure although “our users are relying on us to keep them safe in a world full of threats”
The next presentation was given by Microsoft on .NET going Open Source. She presented the .NET stack which Microsoft has open sourced at the end of last year as well as on Visual Studio. Their vision, she said, is that Visual Studio is a general purpose IDE for every app and every developer. So they have good Python and Android support, she said. A “free cross platform code editor” named Visual Studio Code exists now which is a bit more than an editor. So it does understand some languages and can help you while debugging. I tried to get more information on that Patent Grant, but she couldn’t help me much.
There was also a talk on Luwrain by Michael Pozhidaev which is GPLv3 software for blind people. It is not a screen reader but more of a framework for writing software for blind people. They provide an API that guarantees that your program will be accessible without the application programmer needing to have knowledge of accessibility technology. They haven’t had a stable release just yet, but it is expected for the end of 2015. The demo unveiled some a text oriented desktop which reads out text on the screen. Several applications already exist, including a file editor and a Twitter client. The user is able to scroll through the text by word or character which reminded of ChorusText I’ve seen at GNOME.Asia Summit earlier this year.
I had the keynote slot which allowed me to throw out my ideas for the future of the Free Software movement. I presented on GNOME and how I see that security and privacy can make a distinguishing feature of Free Software. We had an interesting discussion afterwards as to how to enable users to make security decisions without prompts. I conclude that people do care about creating usable secure software which I found very refreshing.
Out of the talks, the most interesting talk I have seen, I think, was the one from Iwan S. Tahari, the manager of a local shoe producer who also sponsored GNOME shoes!
“Open Source Software in Shoes Industry” was the title and he talked about how his company, FANS Shoes, est 2001, would use “Open Source”. They are also a BlankOn Linux partner which seems to be a rather big thing in Indonesia. In fact, the keynote presentation earlier was on that distribution and mentioned how they try to make it easier for people of their culture to contribute to Free Software.
Anyway, the speaker went on to claim that in Indonesia, they have 82 million Internet users out of which 69 million use Facebook. But few use “Open Source”, he asserted. The machines sold ship with either Windows or DOS, he said. He said that FANS preferred FOSS because it increased their productivity, not only because of viruses (he mentioned BRONTOK.A as a pretty annoying example), but also because of the re-installation time. To re-install Windows costs about 90 minutes, he said. The average time to install Blank On (on an SSD), was 15 minutes. According to him, the install time is especially annoying for them, because they don’t have IT people on staff. He liked Blank On Linux because it comes with “all the apps” and that there is not much to install afterwards. Another advantage he mentioned is the costs. He estimated the costs of their IT landscape going Windows to be 136,57 million Rupees (12000 USD). With Blank On, it comes down to 0, he said. That money, he can now spend on a Van and a transporter scooter instead. Another feature of his GNU/Linux based system, he said, was the ability to cut the power at will without stuff breaking. Indonesia, he said, is known for frequent power cuts. He explicitly mentioned printer support to be a major pain point for them.
When they bootstrapped their Free Software usage, they first tried to do Dual Boot for their 5 employees. But it was not worth their efforts, because everybody selected Windows on boot, anyway. They then migrated the accounting manager to a GNU/Linux based operating system. And that laptop still runs the LinuxMint version 13 they installed… He mentioned that you have to migrate top down, never from bottom to top, so senior management needs to go first. Later Q&A revealed that this is because of cultural issues. The leaders need to set an example and the workers will not change unless their superiors do. Only their RnD department was hard to migrate, he said, because they need to be compatible to Corel Draw. With the help of an Indonesian Inkscape book, though, they managed to run Inkscape. The areas where they lack support is CAD (think AutoCAD), Statistics (think SPSS), Kanban information system (like iceScrum), and integration with “Computer Aided Machinery”. He also identified the lack of documentation to be a problem not only for them, but for the general uptake of Free Software in Indonesia. In order to amend the situation, they provide gifts for people writing documentation or books!
All in all, it was quite interesting to see an actual (non-computer) business running exclusively on Free Software. I had a chat with Iwan afterwards and maybe we can get GNOME shaped flip-flops in the future 🙂
The next talk was given by Ahmad Haris with GNOME on an Android TV Dongle. He brought GNOME to those 30 USD TV sticks that can turn your TV into a “smart” device. He showed various commands and parameters which enable you to run Linux on these devices. For the reasons as to why put GNOME on those devices, he said, that it has a comparatively small memory footprint. I didn’t really understand the motivation, but I blame mostly myself, because I don’t even have a TV… Anyway, bringing GNOME to more platforms is good, of course, and I was happy to see that people are actively working on bringing GNOME to various hardware.
Similarly, Running GNOME on a Nexus 7 by Bin Li was presenting how he tried to make his Android tabled run GNOME. There is previous work done by VadimRutkovsky:
He gave instructions as to how to create a custom kernel for the Nexus 7 device. He also encountered some problems, such as compilations errors, and showed how he fixed them. After building the kernel, he installed Arch-Linux with the help of some scripts. This, however, turned out to not be successful, so he couldn’t run his custom Arch Linux with GNOME.
He wanted to have a tool like “ubuntu-device-flash” such that hacking on this device is much easier. Also, downloading and flashing a working image is too hard for casually hacking on it, he said.
A presentation I was not impressed by was “In-memory computing on GNU/Linux”. More and more companies, he said, would be using in-memory computing on a general operating system. Examples of products which use in-memory computing were GridGain, SAP HANA, IBM DB2, and Oracle 12c. These products, he said, allow you to make better and faster decision making and to avoid risks. He also pointed out that you won’t have breaking down hard-drives and less energy consumption. While in-memory is blazingly fast, all your data is lost when you have a power failure. The users of big data, according to him, are businesses, academics, government, or software developers. The last one surprised me, but he didn’t go into detail as to why it is useful for an ordinary developer. The benchmarks he showed were impressive. Up to hundred-fold improvements for various tests were recorded in the in-memory setting compared to the traditional on-disk setting. The methodology wasn’t comprehensive, so I am yet not convinced that the convoluted charts show anything useful. But the speaker is an academic, so I guess he’s got at least compelling arguments for his test setup. In order to build a Linux suitable for in-memory computation, they installed a regular GNU/Linux on a drive and modify the boot scripts such that the disk will be copied into a tmpfs. I am wondering though, wouldn’t it be enough to set up a very aggressive disk cache…?
I was impressed by David’s work on ChorusText. I couldn’t follow the talk, because my Indonesian wasn’t good enough. But I talked to him privately and he showed me his device which, as far as I understand, is an assistive screen reader. It has various sliders with tactile feedback to help you navigating through text with the screen reader. Apparently, he has low vision himself so he’s way better suited to tell whether this device is useful. For now, I think it’s great and I hope that it helps more people and that we can integrate it nicely into GNOME.
My own keynote went fairly well. I spent my time with explaining what I think GNOME is, why it’s good, and what it should become in the future. If you know GNOME, me, and my interests, then it doesn’t come as a surprise that I talked about the history of GNOME, how it tries to bring Free computing to everyone, and how I think security and privacy will going to matter in the future. I tried to set the tone for the conference, hoping that discussions about GNOME’s future would spark in the coffee breaks. I had some people discussing with afterwards, so I think it was successful enough.
When I went home, I saw that the Jakarta airport runs GNOME 3, but probably haven’t done that for too long, because the airport’s UX is terrible. In fact, it is one of the worst ones I’ve seen so far. I arrived at the domestic terminal, but I didn’t know which one it was, i.e. its number. There were no signs or indications that tell you in which terminal you are in. Let alone where you need to go to in order to catch your international flight. Their self-information computer system couldn’t deliver. The information desk was able to help, though. The transfer to the international terminal requires you to take a bus (fair enough), but whatever the drivers yell when they stop is not comprehensible. When you were lucky enough to get out at the right terminal, you needed to have a printed version of your ticket. I think the last time I’ve seen this was about ten years ago in Mumbai. The airport itself is big and bulky with no clear indications as to where to go. Worst of all, it doesn’t have any air conditioning. I was not sure whether I had to pay the 150000 Rupees departure tax, but again, the guy at the information desk was able to help. Although I was disappointed to learn that they won’t take a credit card, but cash only. So I drew the money out of the next ATM that wasn’t broken (I only needed three attempts). But it was good to find the non-broken ATM, because the shops wouldn’t take my credit card, either, so I already knew where to get cash from. The WiFi’s performance matches the other airport’s infrastructure well: It’s quite dirty. Because it turned out that the information the guy gave me was wrong, I invested my spare hundred somewhat thousands rupees in dough-nuts in order to help me waiting for my 2.5 hours delayed flight. But I couldn’t really enjoy the food, because the moment I sat on any bench, cockroaches began to invade the place. I think the airport hosts the dirtiest benches of all Indonesia. The good thing is, that they have toilets. With no drinkable water, but at least you can wash your hands. Fortunately, my flight was only two hours late, so I could escape relatively quickly. I’m looking forward to going back, but maybe not via CGK 😉
All in all, many kudos to the organisers. I think this year’s edition was quite successful.
First of all, there is a LaTeX template for the ACMIS conference now. I couldn’t believe that those academics use Word to typeset their papers. I am way too lazy to use Word so I decided to implement their (incomplete and somewhat incoherent) style guide as a LaTeX class. I guess it was an investment but it paid off the moment we needed to compile our list of references. Because, well, we didn’t have to do it… Our colleagues used Word and they spent at least a day to double check whether references are coherent. Not fun. On the technical side: Writing LaTeX classes is surprisingly annoying. The infrastructure is very limited. Everything feels like a big hack. Managing control flow, implementing data structures, de-duplicating code… How did people manage to write all these awesome LaTeX packages without having even the very basic infrastructure?!
As I promised in a recent post, I am coming back to literature databases. We wrote a literature review and thus needed to query databases. While doing the research I took note of some features and oddities and to save some souls from having to find out all that manually, I want to provide my list of these databases. One of my requirements was to export to a sane format. Something text based, well defined, easy to parse. The export shall include as much meta-data as possible, like keywords, citations, and other simple bibliographic data. Another requirement was the ability to deep link to a search. Something simple, you would guess. But many fall short. Not only do I want the convenience of not having to enter rather complex search queries manually (again), I also want to collaborate. And sending a link to results is much easier than exchanging instructions as to where to click.
Export not possible directly, but via other bepress services, such as AISNet. But then it’s hidden behind “show search”, then “advanced search” and then you can select “Bibliography Export” (Endote)
On the paper (pdf link) itself: It’s called “Towards inter-organizational Enterprise Architecture Management – Applicability of TOGAF 9.1 for Network Organizations” and we investigated what problems the research community identified for modern enterprises and how well an EAM framework catered for those needs.
The abstract is as follows:
Network organizations and inter-organizational systems (IOS) have recently been the subjects of extensive research and practice.
Various papers discuss technical issues as well as several complex business considerations and cultural issues. However, one interesting aspect of this context has only received adequate coverage so far, namely the ability of existing Enterprise Architecture Management (EAM) frameworks to address the diverse challenges of inter-organizational collaboration. The relevance of this question is grounded in the increasing significance of IOS and the insight that many organizations model their architecture using such frameworks. This paper addresses the question by firstly conducting a conceptual literature review in order to identify a set of challenges. An EAM framework was then chosen and its ability to address the challenges was evaluated. The chosen framework is The Open Group Architecture Framework (TOGAF) 9.1 and the analysis conducted with regard to the support of network organizations highlights which issues it deals with. TOGAF serves as a good basis to solve the challenges of “Process and Data Integration” and “Infrastructure and Application Integration”. Other areas such as the “Organization of the Network Organization” need further support. Both the identification of challenges and the analysis of TOGAF assist academics and practitioners alike to identify further
research topics as well as to find documentation related to inter-organizational problems in EAM.
FTR: The permissions I needed to give away were surprisingly relaxed:
By checking the box below, I grant AMCIS 2013 Manuscript Submission on behalf of AMCIS 2013 the non-exclusive right to distribute my submission (“the Work”) over the Internet and make it part of the AIS Electronic Library (AISeL).
I warrant as follows:
that I have the full power and authority to make this agreement;
that the Work does not infringe any copyright, nor violate any proprietary rights, nor contain any libelous matter, nor invade the privacy of any person or third party;
that the Work has not been published elsewhere with the same content or in the same format; and
that no right in the Work has in any way been sold, mortgaged, or otherwise disposed of, and that the Work is free from all liens and claims.
I understand that once a peer-reviewed Work is deposited in the repository, it may not be removed.