Ouf, long time no blog. Sorry about that. Life is.. busy these days. One of my occupations has been to defend against USB-borne attacks, as mentioned before. Probably the most known is the BadUSB attack which masquerades as a mass storage device but also is a keyboard. Then, the device would inject keystrokes which hack your machine. This class of attacks is difficult to defend against, because the operating system can hardly determine whether the user did indeed want to plug a device with those capabilities in. There is another class of attacks, though, which is a bit easier to defend against, I think. That other class is based on buggy drivers which the malicious USB device pulls in. So once you attach your device, the host’s kernel will look for the appropriate driver and let it speak with the device. That’s very convenient because it makes devices just work. However, certain drivers might not be of the same quality than others and there have indeed been cases which allow a malicious USB device to interact with a bit-rotten driver which in turn led to fatal consequences.
I have been thinking a lot about how to defend against either class of attacks. You can easily come up with various solutions based on pop-ups interrupting the user and authoring the device before it will be ready for use. Or with a policy-based solution that requires you to generate a firewall-like description of what the machine is allowed to do. Or a mixture of those two attempts. And that’s what has been done, already. Arguably, none of these solutions has been successful, as I am not aware of any built-in protection scheme for any major operating system. The reason, I believe, is that users expect things to just work and once you make it not work, users get grumpy. So the challenge is to unfold protection capabilities without changing the users’ experience.
The short version of our approach is that we are trying to be smart about the user’s intent. That is, if the screen is locked, then we block the device. If a new keyboard is present and it tries to perform “dangerous” actions, we block them. Of course, you may very well expect that device to work when the screen is locked or the new keyboard to perform actions deems dangerous. This is why is make sure you have a way to opt out of the mechanism and continue to enjoy your GNOME experience. Almost all credits go to Ludovico for coming up with a set of patches as well as following up to make sure we can get it merged. Our slides are here and the video of our presentation is here:
But I wanted to write more about GUADEC… This year’s GUADEC was in Thessaloniki, Greece, and I had the pleasure to be talking about the above mentioned protection. It was the end of the summer so the city was nicely warm and comfy. The coffee, juices, pastries, and other food and drinks in small shops on the streets were amazingly fresh and yummie. Arriving in Thessaloniki was okay. I’ve had better airport transfers in my life, but since there were only two buses it was hard to get lost. I needed to pay attention to the GPS, though, to find my right stop. It’s been long since I’ve slept in a bunk bed, but because we’re all GNOME people we had a good time.
Meeting friends, old and new, is really good and I have had a fantastically efficient time talking to people. It’s so much better to meet in-person and talk directly rather than via email or bug tracker.
The country is incredibly civilised and friendly. I felt much more reminded of Japan rather than China. It’s a very safe and easy place to travel. The public transportation system is fast and efficient. The food is cheap and you’ll rarely be surprised by what you get. The accommodation is a bit pricey but we haven’t been disappointed. But the fact the
Taiwan is among the 20 countries which are least reliant on tourism, you may also say that they have not yet developed tourism as a GDP dominating factor, shows. Many Web sites are in Chinese, only. The language barrier is clearly noticeable, albeit fun to overcome. Certain processes, like booking a train ticket, are designed for residents, only, leaving tourists only the option of going to a counter rather than using electronic bookings. So while it’s a safe and fun country to travel, it’s not as easy as it could or should be.
The conference was fairly big. I reckon that there have been 500 attendees, at least. The tracks were a bit confusing as there were info panels showing the schedule, a leaflet with the programme, and a Web site indicating what was going on, but all of those were contradicting each other. So I couldn’t know whether a talk was in English, Chinese, or a wild mix of those. It shouldn’t have mattered much, because, amazingly enough, they had live translation into either language. But I wasn’t convinced by their system, because they had one poor person translating the whole talk. And after ten minutes or so I noticed how the guy lost his concentration.
Anyway, a few interesting talks I have seen were given by Trend Micro’s Fyodor about fraud in the banking and telephony sector. He said that telcos and banks are quite similar and in fact, in order to perform a banking operation a phone is required often times. And in certain African countries, telcos like Vodafone are pretty much a bank. He showed examples of how these sectors are being attacked by groups with malicious intents. He mentioned, among others, the Lazarus group.
Another interesting talk was about Korean browser plugins which are required by banks and other companies. It was quite disastrous. From what I understood the banks require you to install their software which listens on all interfaces. Then, the bank’s Web site would contact that banking software which in turn cryptographically signs a request or something. That software, however, is full of bugs. So bad, that you can exploit them remotely. To make matters worse, that software installs itself as a privileged program, so your whole machine is at risk. I was very surprised to learn that banks take such an approach. But then again, currently banks require us to install their proprietary apps on proprietary phone operating systems and at least on my phone those apps crash regularly 🙁
My own talk was about making operating system more secure and making more secure operating systems. With my GNOME hat on, I mentioned how I think that the user needs to led in a cruel world with omnipresent temptation to misbehave. I have given similar presentations a few times and I developed a few questions and jokes to get the audience back at a few difficult moments during the presentation. But with that didn’t work so well due to the language barrier. Anyway, it was great fun and I still got some interesting discussions out of it afterwards.
Big kudos to the organisers who have been running this event for many many years now. Their experience can certainly be seen in the quality of the venue, the catering, and the selection of speakers. I hope to be able to return in the next few years.
I was fortunate enough to be invited to Kyiv to keynote (video) the local Open Source Developer Network conference. Actually, I had two presentations. The opening keynote was on building a more secure operating system with fewer active security measures. I presented a few case studies why I believe that GNOME is well positioned to deliver a nice and secure user experience. The second talk was on PrivacyScore and how I believe that it makes the world a little bit better by making security and privacy properties of Web sites transparent.
The audience was super engaged which made it very nice to be on stage. The questions, also in the hallway track, were surprisingly technical. In fact, most of the conference was around Kernel stuff. At least in the English speaking track. There is certainly a lot of potential for Free Software communities. I hope we can recruit these excellent people for writing Free Software.
Lennart eventually talked about CAsync and how you can use that to ship your images. I’m especially interested in the cryptography involved to defend against certain attacks. We also talked about how to protect the integrity of the files on the offline disk, e.g. when your machine is off and some can access the (encrypted) drive. Currently, LUKS does not use authenticated encryption which makes it possible that an attacker can flip some bits in the disk image you read.
Canonical’s Christian Brauner talked about mounting in user namespaces which, historically, seemed to have been a contentious topic. I found that interesting, because I think we currently have a problem: Filesystem drivers are not meant for dealing with maliciously crafted images. Let that sink for a moment. Your kernel cannot deal with arbitrary data on the pen drive you’ve found on the street and are now inserting into your system. So yeah, I think we should work on allowing for insertion of random images without having to risk a crash of the system. One approach might be libguestfs, but launching a full VM every time might be a bit too much. Also you might somehow want to promote drives as being trusted enough to get the benefit of higher bandwidth and lower latency. So yeah, so much work left to be done. ouf.
Then, Tycho Andersen talked about forwarding syscalls to userspace. Pretty exciting and potentially related to the disk image problem mentioned above. His opening example was the loading of a kernel module from within a container. This is scary, of course, and you shouldn’t be able to do it. But you may very well want that if you have to deal with (proprietary) legacy code like Cisco, his employer, does. Eventually, they provide a special seccomp filter which forwards all the syscall details back to userspace.
As I’ve already mentioned, the conference was highly technical and kernel focussed. That’s very good, because I could have enlightening discussions which hopefully get me forward in solving a few of my problems. Another one of those I was able to discuss with Jakob on the days around the conference which involves the capabilities of USB keyboards. Eventually, you wouldn’t want your machine to be hijacked by a malicious security device like the Yubikey. I have some idea there involving modifying the USB descriptor to remove the capabilities of sending funny keys. Stay tuned.
Anyway, we’ve visited the city and the country before and after the event and it’s certainly worth a visit. I was especially surprised by the coffee that was readily available in high quality and large quantities.
tl;dr: We have a new Keysign release with support for exchanging keys via the Internet.
I am very proud to announce this version of GNOME Keysign, because it marks an important step towards a famous “1.0”. In fact, it might be just that. But given the potentially complicated new dependencies, I thought it’d be nice to make sort of an rc release.
The main feature is a transport via the Internet. In fact, the code has been lurking around since last summer thanks to Ludovico’s great work. I felt it needed some massaging and more gentle introduction to the code base before finally enabling it.
For the transport we use Magic Wormhole, an amazing package for transferring files securely. If you don’t know it yet, give it a try. It is a very convenient tool for sending files across the Internet. They have a rendezvous server so that it works in NATted environments, too. Great.
You may wonder why we need an Internet transport, given that we have local network and Bluetooth already. And the question is good, because initially I didn’t think that we’d expose ourselves to the Internet. Simply because the attack surface is just so much larger and also because I think that it’s so weird to go all the way through the Internet when all we need is to transfer a few bytes between two physically close machines. It doesn’t sound very clever to connect to the Internet when all we need is to bridge 20 centimetres.
Anyway, as it turns out, WiFi access points don’t allow clients to connect to each other 🙁 Then we have Bluetooth, but it’s still a bit awkward to use. My impression is that people are not satisfied with the quality of Bluetooth connections. Also, the Internet is comparatively easy to use, both as a programmer and a user.
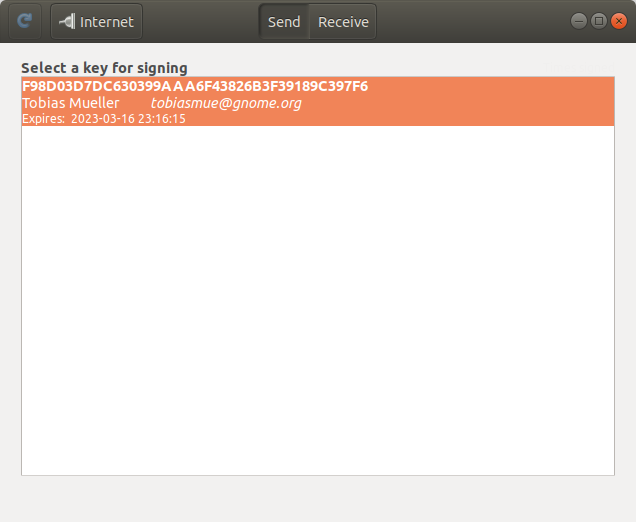
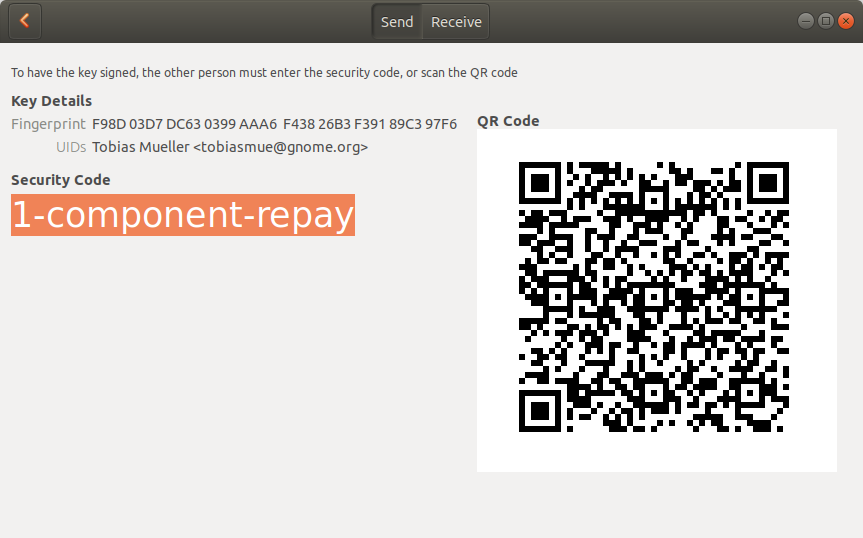
Of course, we now also have the option to exchange keys when not being physically close. I do not recommend that, though, because our security assumes the visual channel to be present and, in fact, secure. In other words: Scan the barcode for a secure key signing experience. Be aware that if you transfer the “security code” manually via other means, you may be compromised.
With this change, the UX changes a bit for the non-Internet transports, too. For example, we have a final page now which indicates success or failure. We can use this as a base for accompanying the signing process further, e.g. sign the key again with a non-exportable short-term signature s.t. the user can send an email right away. Or exchange the keys again after the email has been received. Exciting times ahead.
Now, after the wall of text, you may wonder how to get hold of this release. It should show up on Flathub soon.
It’s been a while after my last post. This time, we have many exciting news to share. For one, we have a new release of GNOME Keysign which fixes a few bugs here and there as well as introduces Bluetooth support. That is, you can transfer your key with your buddy via Bluetooth and don’t need a network connection. In fact, it becomes more and more popular for WiFis to block clients talking to each other. A design goal is (or rather: was, see down below) to not require an Internet connection, simply because it opens up a can of worms with potential failures and attacks. Now you can transfer the key even if your WiFi doesn’t let you communicate with the other machine. Of course, both of you need have to have Bluetooth hardware and have it enabled.
The other exciting news is the app being on Flathub. Now it’s easier than ever to install the app. Simply go to Flathub and install it from there. This is a big step towards getting the app into users’ hands. And the sandbox makes the app a bit more trustworthy, I hope.
The future brings cool changes. We have already patches lined up that bring an Internet transport with the app. Yeah, that’s contrary to what I’ve just said a few paragraphs above. And it does cause some issues in the UI, because we do not necessarily want the user to use the Internet if the local transport just works. But that “if” is unfortunately getting bigger and bigger. So I’m happy to have a mix of transports now. I’m wondering what the best way is to expose that information to the user, though. Do we add a button for the potentially privacy invading act of connecting to the Internet? If we do, then why do we not offer buttons for the other transports like Bluetooth or the local network?
Few weeks ago I had a talk at Cubaconf 2017 in Havanna, Cuba. It’s certainly been an interesting experience. If only because of Carribean people. But also because of the food and the conditions the country has be run under the last decades.
Before entering Cuba, I needed a tourist visa in form of the turist trajeta. It was bothering me for more than it should have. I thought I’d have to go to the embassy or take a certain airline in order to be able to get hold of one of these cased. It turned out that you can simply buy these tourist cards in the Berlin airport from the TUI counter. Some claimed it was possible to buy at the immigration, but I couldn’t find any tourist visa for sale there, so be warned. Also, I read that you have to prove that you have health insurance, but nobody was interested in mine. That said, I think it’s extremely clever to have one…
Connecting to the Internet is a bit difficult in Cuba. I booked a place which had “Wifi” marked as their features and I naïvely thought that it meant that you by booking the place I also get to connect to the Internet. Turns out that it’s not entirely correct. It’s not entirely wrong either, though. In my case, there was an access point in the apartment in which I rented a room. The owner needs to turn it on first and run a weird managing software on his PC. That software then makes the AP connect to other already existing WiFis and bridges connections. That other WiFi, in turn, does not have direct Internet access, but instead somehow goes through the ISP which requires you to log in. The credentials for logging in can be bought in the ISPs shops. You can buy credentials worth 1 hour of WiFi connection (note that I’m avoiding the term “Internet” here) for 3 USD or so from the dealer around the corner. You can get your fix from the legal dealer cheaper (i.e. the Internet office…), but that will probably involve waiting in queues. I often noticed people gathering somewhere on the street looking into their phones. That’s where some signal was. When talking to the local hacker community, I found out that they were using a small PCB with an ESP8266 which repeats the official WiFi signal. The hope is that someone will connect to their piece of electronics so that the device is authenticated and also connects the other clients associated with the fake hotspot. Quite clever.
The conference was surprisingly well attended. I reckon it’s been around hundred people. I say surprisingly, because from all what I could see the event was weirdly organised. I had close to zero communication with the organisers and it was pure luck for me to show up in time. But other people seemed to be in the know so I guess I fell through the cracks somehow. Coincidentally, you could only install the conference’s app from Google, because they wouldn’t like to offer a plain APK that you can install. I also didn’t really know how long my talks should be and needed to prepare for anything between 15 and 60 minutes.
My first talk was on PrivacyScore.org, a Web scanner for privacy and security issues. As I’ve indicated, the conference was a bit messily organised. The person before me was talking into my slot and then there was no cable to hook my laptop up with the projector. We ended up transferring my presentation to a different machine (via pen drives instead of some fancy distributed local p2p network) in order for me to give my presentation. And then I needed to rush through my content, because we were pressed for going for lunch in time. Gnah. But I think a few people were still able to grasp the concepts and make it useful for them. My argument was that Web pages load much faster if you don’t have to load as many trackers and other external content. Also, these people don’t get updates in time, so they might rather want to visit Web sites which generally seem to care about their security. I was actually approached by a guy running StreetNet, the local DIY Internet. His idea is to run PrivacyScore against their network to see what is going on and to improve some aspects. Exciting.
My other talk was about GNOME and how I believe it makes more secure operating systems. Here, my thinking was that many people don’t have expectations of how their system is supposed to be looking or even working. And being thrown into the current world in which operating systems spy on you could lead to being primed to have low expectations of the security of the system. In the GNOME project, however, we believe that users must have confidence in their computing being safe and sound. To that end, Flatpak was a big thing, of course. People were quite interested. Mostly, because they know everything about Docker. My trick to hook these people is to claim that Docker does it all wrong. Then they ask pesky questions which gives me many opportunities to mention that for some applications squashfs is inferior to, say, OStree, or that you’d probably want to hand out privileges only for a certain time rather than the whole life-time of an app. I was also to make people look at EndlessOS which attempts to solve many problems I think Cubans have.
The first talk of the conference was given by Ismael and I was actually surprised to meet people I know. He talked about his hackerspace in Almería, I think. It was a bit hard to me to understand, because it was in Spanish. He was followed by Valessio Brito who talked about putting a price on Open Source Software. He said he started working on Open Source Software at the age of 16. He wondered how you determine how much software should cost. Or your work on Open Source. His answer was that one of the determining factors was simply personal preference of the work to be performed. As an example he said that if you were vegan and didn’t like animals to be killed, you would likely not accept a job doing exactly that. At least, you’d be inclined to demand a higher price for your time. That’s pretty much all he could advise the audience on what to do. But it may also very be that I did not understand everything because it was half English and half Spanish and I never noticed quickly enough that the English was on.
An interesting talk was given by Christian titled “Free Data and the Infrastructure of the Commons”. He began saying that the early textile industry in Lyon, France made use of “software” in 1802 with (hard wired) wires for the patterns to produce. With the rise of computers, software used to be common good in the early 1960s, he said. Software was a common good and exchanged freely, he said. The sharing of knowledge about software helped to get the industry going, he said. At the end of the 1970s, software got privatised and used to be licensed from the manufacturer which caused the young hacker movement to be felt challenged. Eventually, the Free Software movement formed and hijacked the copyright law in order to preserve the users’ freedoms, he said. He then compared the GPL with the French revolution and basic human rights in that the Free Software movement had a radical position and made the users’ rights explicit. Eventually, Free Software became successful, he said, mainly because software was becoming more successful in general. And, according to him, Free Software used to fill a gap that other software created in the 80s. Eventually, the last bastion to overcome was the desktop, he said, but then the Web happened which changed the landscape. New struggles are software patents, DRM, and privacy of the “bad services”. He, in my point of view rightfully so, said that all the proliferation of free and open source software, has not lead to less proprietary software though. Also, he is missing the original FOSS attitude and enthusiasm. Eventually he said that data is the new software. Data not was not an issue back when software, or Free Software even, started. He said that 99% of the US growth is coming from the data processing ad companies like Google or Facebook. Why does data have so much value, he asked. He said that actually living a human is a lot of work. Now you’re doing that labour for Facebook by entering the data of your human life into their system. That, he said, is where the value in coming from. He made the the point that Software Freedoms are irrelevant for data. He encouraged the hackers to think of information systems, not software. Although he left me wondering a bit how I could actually do that. All in all, a very inspiring talk. I’m happy that there is a (bad) recording online:
I visited probably the only private company in Cuba which doubles as a hackerspace. It’s interesting to see, because in my world, people go and work (on computer stuff) to make enough money to be free to become a singer, an author, or an artist. In Cuba it seems to be the other way around, people work in order to become computer professionals. My feeling is that many Cubans are quite artsy. There is music and dancing everywhere. Maybe it’s just the prospects of a rich life though. The average Cuban seems to make about 30USD a month. That’s surprising given that an hour of bad WiFi costs already 1 USD. A beer costs as much. I was told that everybody has their way to get hold of some more money. Very interesting indeed. Anyway, the people in the hackerspace seemed to be happy to offer their work across the globe. Their customers can be very happy, because these Cubans are a dedicated bunch of people. And they have competitive prices. Even if these specialists make only hundred times as much the average Cuban, they’d still be cheap in the so called developed world.
After having arrived back from Cuba, I went to the Rust Hackfest in Berlin. It was hosted by the nice Kinvolk folks and I enjoyed meeting all the hackers who care about making use of a safer language. I could continue my work on rustifying pixbuf loaders which will hopefully make it much harder to exploit them. Funnily enough, I didn’t manage to write a single line of Rust during the hackfest. But I expected that, because we need to get to code ready to be transformed to Rust first. More precisely, restructure it a bit so that it has explicit error codes instead of magic numbers. And because we’re parsing stuff, there are many magic numbers. While digging through the code, other bugs popped up as well which we needed to eliminate as side challenges. I’m looking much forward to writing an actual line of Rust soon! 😉
Uh, I almost forgot about blogging about having talked at the GI Tracking Workshop in Darmstadt, Germany. The GI is, literally translated, the “informatics society” and sort of a union of academics in the field of computer science (oh boy, I’ll probably get beaten up for that description). And within that body several working groups exist. And one of these groups working on privacy organised this workshop about tracking on the Web.
I consider “workshop” a bit of a misnomer for this event, because it was mainly talks with a panel at the end. I was an invited panellist for representing the Free Software movement contrasting a guy from affili.net, someone from eTracker.com, a lady from eyeo (the AdBlock Plus people), and professors representing academia. During the panel discussion I tried to focus on Free Software being the only tool to enable the user to exercise control over what data is being sent in order to control tracking. Nobody really disagreed, which made the discussion a bit boring for me. Maybe I should have tried to find another more controversial argument to make people say more interesting things. Then again, it’s probably more the job of the moderator to make the participants discuss heatedly. Anyway, we had a nice hour or so of talking about the future of tracking, not only the Web, but in our lives.
One of the speakers was Lars Konzelmannwho works at Saxony’s data protection office. He talked about the legislative nature of data protection issues. The GDPR is, although being almost two years old, a thing now. Several types of EU-wide regulations exist, he said. One is “Regulation” and the other is “Directive”.The GDPR has been designed as a Regulation, because the EU wanted to keep a minimum level of quality across the EU and prevent countries to implement their own legislation with rather lax rules, he said. The GDPR favours “privacy by design” but that has issues, he said, as the usability aspects are severe. Because so far, companies can get the user’s “informed consent” in order to do pretty much anything they want. Although it’s usefulness is limited, he said, because people generally don’t understand what they are consenting to. But with the GDPR, companies should implement privacy by design which will probably obsolete the option for users to simply click “agree”, he said. So things will somehow get harder to agree to. That, in turn, may cause people to be unhappy and feel that they are being patronised and being told what they should do, rather than expressing their free will with a simple click of a button.
Next up was a guy with their solution against tracking in the Web. They sell a little box which you use to surf the Web with, similar to what Pi Hole provides. It’s a Raspberry Pi with a modified (and likely GPL infringing) modification of Raspbian which you plug into your network and use as a gateway. I assume that the device then filters your network traffic to exclude known bad trackers. Anyway, he said that ads are only the tip of the iceberg. Below that is your more private intimate sphere which is being pried on by real time bidding for your screen estate by advertising companies. Why would that be a problem, you ask. And he said that companies apply dynamic pricing depending on your profile and that you might well be interested in knowing that you are being treated worse than other people. Other examples include a worse credit- or health rating depending on where you browse or because your bank knows that you’re a gambler. In fact, micro targeting allows for building up a political profile of yours or to make identity theft much easier. He then went on to explain how Web tracking actually works. He mentioned third party cookies, “social” plugins (think: Like button), advertisement, content providers like Google Maps, Twitter, Youtube, these kind of things, as a means to track you. And that it’s possible to do non invasive customer recognition which does not involve writing anything to the user’s disk, e.g. no cookies. In fact, such a fingerprinting of the users’ browser is the new thing, he said. He probably knows, because he is also in the business of providing a tracker. That’s probably how he knows that “data management providers” (DMP) merge data sets of different trackers to get a more complete picture of the entity behind a tracking code. DMPs enrich their profiles by trading them with other DMPs. In order to match IDs, the tracker sends some code that makes the user’s browser merge the tracking IDs, e.g. make it send all IDs to all the trackers. He wasn’t really advertising his product, but during Q&A he was asked what we can do against that tracking behaviour and then he was forced to praise his product…
Eye/o’s legal counsel Judith Nink then talked about the juristic aspects of blocking advertisements. She explained why people use adblockers in first place. I commented on that before, claiming that using an adblocker improves your security. She did indeed mention privacy and security being reasons for people to run adblockers and explicitly mentionedmalvertising. She said that Jerusalem Post had ads which were actually malware. That in turn caused some stir-up in Germany, because it was coined as attack on German parliament… But other reasons for running and adblocker were data consumption and the speed of loading Web pages, she said. And, of course, the simple annoyance of certain advertisements. She presented some studies which showed that the typical Web site has 50+ or so trackers and that the costs of downloading advertising were significant compared to downloading the actual content. She then showed a statement by Edward Snowden saying that using an ad-blocker was not only a right but is a duty.
Everybody should be running adblock software, if only from a safety perspective
Browser based ad blockers need external filter lists, she said. The discussion then turned towards the legality of blocking ads. I wasn’t aware that it’s a thing that law people discuss. How can it possibly not be legal to control what my client does when being fed a bunch of HTML and JavaScript..? Turns out that it’s more about the entity offering these lists and a program to evaluate them *shrug*. Anyway, ad-blockers use either blocking or hiding of elements, she said where “blocking” is to stop the browser from issuing the request in first place while “hiding” is to issue the request, but to then hide the DOM element. Yeah, law people make exactly this distinction. She then turned to the question of how legal either of these behaviours is. To the non German folks that question may seem silly. And I tend to agree. But apparently, you cannot simply distribute software which modifies a Browser to either block requests or hide DOM elements without getting sued by publishers. Those, she said, argue that gratis content can only be delivered along with ads and that it’s part of the deal with the customer. Like that they also transfer ads along with the actual content. If you think that this is an insane argument, especially in light of the customer not having had the ability to review that deal before loading that page, you’re in good company. She argued, that the simple act of loading a page cannot be a statement of consent, let alone be a deal of some sorts. In order to make it a deal, the publishers would have to show their terms of service first, before showing anything, she said. Anyway, eye/o’s business is to provide those filter lists and a browser plugin to make use of those lists. If you pay them, however, they think twice before blocking your content and make exceptions. That feels a bit mafiaesque and so they were sued for “aggressive geschäftliche Handlung”, an “aggressive commercial behaviour”. I found the history of cases interesting, but I’ll spare the details for the reader here. You can follow that, and other cases, by looking at OLG Koeln 6U149/15.
Next up was Dominik Herrmann to present on PrivacyScore.org, a Web portal for scanning Web sites for security and privacy issues. It is similar to other scanners, he said, but the focus of PrivacyScore is publicity. By making results public, he hopes that a race to the top will occur. Web site operators might feel more inclined to implement certain privacy or security mechanisms if they know that they are the only Web site which doesn’t protect the privacy of their users. Similarly, users might opt to use a Web site providing a more privacy friendly service. With the public portal you can create lists in order to create public benchmarks. I took the liberty to create a list of Free Desktop environments. At the time of creation, GNOME fell behind many others, because the mail server did not implement TLS 1.2. I hope that is being taking as a motivational factor to make things more secure.
I was invited to present GNOME at the Kieler LinuxTage in Kiel, Germany.
Compared to other events, it’s a tiny happening with something between fifty and hundred people or so. I was presenting on how I think GNOME pushes the envelope regarding making secure operating systems (slides, videos to follow). I was giving three examples of how GNOME achieves its goal of priding a secure OS without compromising on usability. In fact, I claimed that the most successful security solutions must not involve the user. That sounds a bit counter intuitive to people in the infosec world, because we’re trying to protect the user, surely they must be involved in the process. But we better not do that. This is not to say that we shouldn’t allow the user to change preferences regarding how the solutions behave, but rather that it should work without intervention. My talk was fairly good attended, I think, and we had a great discussion. I tend to like the discussion bit better than the actual presentation, because I see it as an indicator for how much the people care. I couldn’t attend many other presentations, because I would only attend the second day. That’s why I couldn’t meet with Jim :-/
But I did watch Benni talking about hosting a secure Web site (slides). He started his show with mentioning DNS which everybody could read, He introduced DNSSEC. Which, funnily enough, everybody also can read, but he failed to mention that. But at least nobody can manipulate the response. Another issue is that you leak information about your host names with negative responses, because you tell the client that there is nothing between a.example.com and b.example.com. He continued with SSH for deploying your Web site and mentioned SSHFP which is a mechanism for authenticating the host key. The same mechanism exists for Web or Mail servers, he said: DANE, DNS-based Authentication of named entities. It works via TLSA records which encode either the certificate or the used public key. Another DNS-based mechanism is relatively young: CAA. It asserts that a certificate for a host name shall be signed by a certain entity. So you can hopefully prevent a CA that you’ve never heard of creating a certificate for your hosts. All of these mechanisms try to make the key exchange in TLS a bit less shady. TLS ensures a secure channel, i.e. confidentiality, non-repudiation, and integrity. That is considered to be generally useful in the Web context. TLS tends to be a bit of a minefield, because of the version and configuration matrix. He recommended to use at least TLS as of version 1.2, to disable compression due to inherent attacks on typical HTTP traffic (CRIME), and to use “perfect forward secrecy” ciphers for protecting the individual connections after the main key leaked. Within TLS you use x509 certificates for authenticating the parties, most importantly in the Web world, the server side. The certificate shall use a long enough RSA key, he said, The certificate shall not use a CN field to indicate the host name, but rather the SAN field. The signatures should be produced with “at least SHA-256”. He then mentioned OCSP because life happens and keys get lost or stolen. However, with regular OSCP the clients expose the host names they visit, he said. Enter OCSP Stapling. In that case the Web server itself gets the OCSP response and hands it over to the client. Of course, this comes with its own challenges. But it may also happen that CAs issue certificates for a host name which doesn’t expect that new certificate. In that case, Certificate transparency becomes useful. It’s composed of three components, he said. Log servers which logs all created certificates, monitors which pull the logs, and auditors which check the logs for host names. Again, your Browser may want to check whether the given certificate is in the CT logs. This opens the same privacy issue as with OCSP and can be somewhat countered with signed log statements from a few trusted log servers.
In any case, TLS is only useful, he said, if you are actually using it. Assuming you had a secure connection once, you can use the TLS Strict Transport Security header. It tells the browser to use TLS in the future. Of course, if you didn’t have that first connection, you can have your webapp entered in the STS Preloading list which is then baked into major browsers. Another mechanism is HTTP Public Key Pinning which is a HTTP header to tell the client which certificates or CAs shall be accepted. The header value is a simple list of hashed certificates. He mentioned the risk of someone hijacking your Web presence with an injected HPKP header. A TLS connection has eventually been established successfully. Now the HTTP layer gets interesting, he said. The Content Type Options header prevents Internet Explorer from snooping content types which might cause an image to be executed as JavaScript. Many Cross-Site Scripting attacks, he said, originate from being embedded in a frame. To prevent that, you can set the X-Frame-Options header. To activate Cross-Site Scripting protection mechanisms, the X-XSS-Protection header can be set. It’s probably turned off by default for compatibility reasons, he said. If you know where exactly your data is coming from, you can make use of a Content Security Policy which is like SELinux for your browser. It’s a bit of a complicated mechanism though. For protecting your Webapp he mentioned Sub-Resource Integrity which is essentially the hash of what script you expect. This prevents tampering with the foreign script, malicious or not.
I think that was one of the better talks in the schedule with many interesting details to be discovered. I enjoyed it a lot. I did not enjoy their Web sites, though, which are close to being unusable. The interface for submitting talks gives you a flashback to the late 90’s. Anyway, it seems to have worked for many years now and hope they will have many years to come.
A few weeks ago, I was fortunate enough to talk at the 7th Privacy Enhancing Techniques Conference (PET-CON 2017.2) in Hamburg, Germany. It’s a teeny tiny academic event with a dozen or so experts in the field of privacy.
The talks were quite technical, involving things like machine learning over logs or secure multi-party computation. I talked about how I think that the best technical solution does not necessarily enable the people to be more private, simply because the people might not be able to make use of the tool properly. A concern that’s generally shared in the academic community. Yet, the methodology to create and assess the effectiveness of a design is not very elaborated. I guess we need to invest more brain power into creating models, metrics, and tools for enabling people to do safer computing.
So I’m happy to have gone and to have had the opportunity of discussing the issues I’m seeing. Likewise, I find it very interesting to see where the people are currently headed towards.
I attended this year’s MRMCD in Darmstadt, Germany. I attended a fewtimesinthepast and I think this year’s edition was not as successful as the last ones. The venue changed this year, what probably contributed to some more chaos than usual and hence things not running as smoothly as they did. I assume it will be better next year, when people know how to operate the venue. Although all tickets were sold during the presale phase, it felt smaller than in the last years. In fairness, though, the venue was also bigger this year. The schedule had some interesting talks, but I didn’t really get around to attend many, because I was busy preparing my own shows (yeah, should’ve done that before…).
I had two talks at this conference. The first was on playing the children’s game “battleship” securely (video). That means with cryptography. Lennart and I explained how concepts such as commitment schemes, zero knowledge proofs of knowledge, oblivious transfer, secure multiparty computation and Yao’s protocol can be used to play that game without a trusted third party. The problem, in short, is to a) make sure that the other party’s ships are placed correctly and b) to make sure the other party answers correctly. Of course, if you get hold of the placements of the ships these problems are trivial. But your opponent doesn’t like you to know about the placements. Then a trusted third party would solve that problem trivially. But let’s assume we don’t have such a party. Also, we want to decentralise things, so let’s come up with a solution that involves two players only.
The second problem can be solved with a commitment. A commitment is a statement about a something you’ve chosen but that doesn’t reveal the choice itself nor allows for changing ones mind later. Think of a letter in a closed envelope that you hand over. The receiver doesn’t know what’s written in the letter and the sender cannot change the content anymore. Once the receiver is curious, they can open the envelope. This analogy isn’t the best and I’m sure there’s better real-world concepts to compare to commitment schemes. Anyway, for battleship, you can make the other party commit to the placement of the ships. Then, when the battle starts, you have the other party open the commitment for the field that you’re shooting. You can easily check whether the commitment verifies correctly in order to determine whether you hit a ship or water.
The other problem is the correct placement of the ships, e.g. no ships shall be adjacent, exactly ten ships, exactly one five-field ship, etc. You could easily wait until the end of the game and then check whether everything was placed correctly. But that wouldn’t be (cryptographic) fun. Let’s assume one round of shooting is expensive and you want to make sure to only engage if the other party indeed follows the rules. Now it’s getting a bit crazy, because we need to perform a calculation without learning anything else than “the ships are correctly placed”. That’s a classic zero knowledge problem. And I think it’s best explained with the magic door in a cave.
Even worse, we need to somehow make sure that we cannot change our placement afterwards. There is a brain melting concept of secure multi-party computation which allows you to do exactly that. You can execute a function without knowing what you’re doing. Crazy. I won’t be able to explain how it works in a single blog post and I also don’t intend to, because others are much better in doing that than I could ever be. The gist of the protocol is, that you model your functionality as a Boolean circuit and assign random values to represent “0” or “1” for each wire. You then build the truth table for each gate and replace the values of the table (zeros and ones) with an encryption under both the random value for the first input wire and the random value for the second input wire. The idea now is that the evaluator can only decrypt one value in the truth table given the input keys. There are many more details to care about but eventually you have a series of encrypted, or garbled, gates and you need the relevant keys in order to evaluate it. You can’t tell from the keys you get whether it represents a “0” or a “1”. Hence you can evaluate without knowing the other party’s input.
My other talk was about a probable successor of Return Oriented Programming: Data Oriented Programming (video). In Return Oriented Programming (ROP) and its variants like JOP the aim is to diverge the original control flow in order to make the program execute the attacker’s functionality. This, however, can probably be thwarted by Control Flow Integrity. In its simplest form, it checks on every branch whether it is legit. Think of a database with a list of addresses which are allowed to a list of other addresses. Of course, real-world implementations are more clever. Anyway, let’s assume that we’ll have a hard time exploiting our target with ROP, because we cannot change the CFG of the program. If our attack doesn’t change the CFG, though, we should be safe for anything that detects its modification. That’s the central idea of DOP.
Although I’m not super excited about this year’s edition, I’m looking forward to seeing the next year’s event. I hope it’s going to be a bit more organised; including myself 😉



























{kind=link}