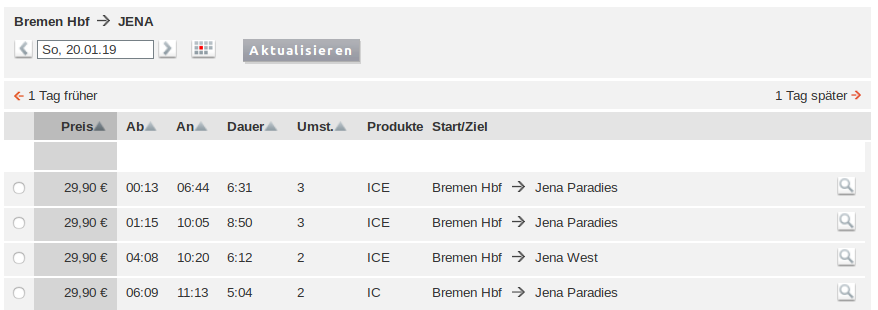
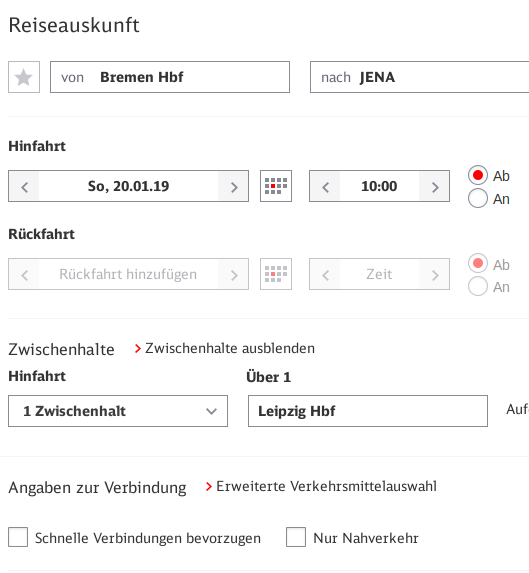
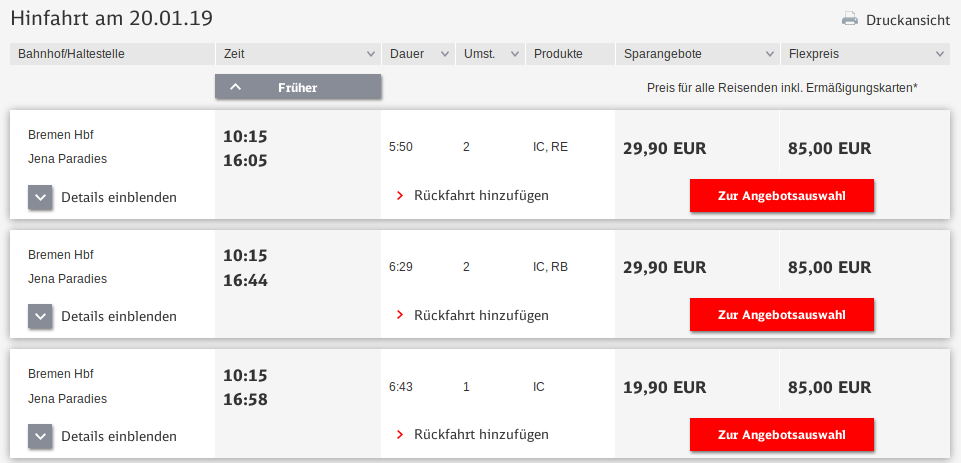
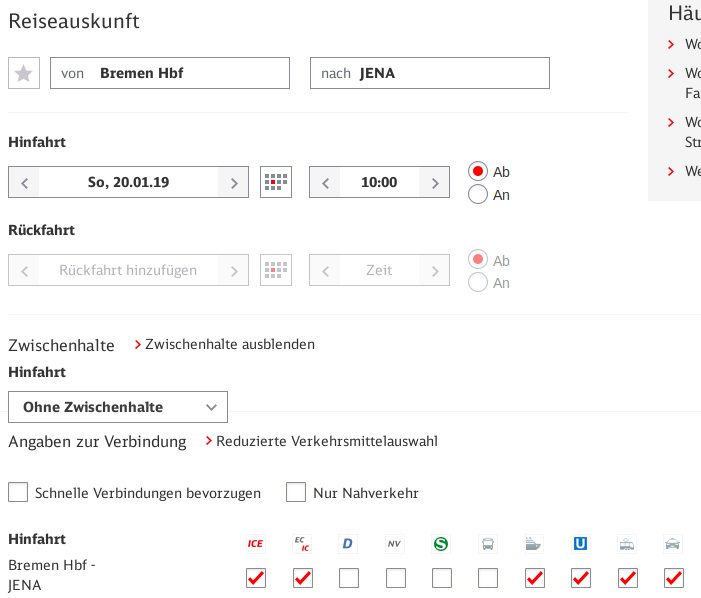
Recently, I’ve attended the first ever OpenPGP conference in Cologne, Germany. It’s amazing how 25 years of OpenPGP have passed without any conference for bringing various OpenPGP people together. I attended rather spontaneously, but I’m happy to have gone. It’s been very insightful and I’m really glad to have met many interesting people.

Werner himself opened the conference with his talk on key discovery. He said that the problem of integrating GnuPG in MUAs is solved. I doubt that with a fair bit of confidence. Besides few weird MUAs (mutt, gnus, alot, …) I only know KMail (should maybe also go into the “weird” category 😉 ) which uses GnuPG through gpgme, which is how a MUA really should consume GnuPG functionality. GNOME’s Evolution, while technically correct, supports gnugp, but only badly. It should really be ported to gpgme. Anyway, Werner said that the problem of encryption has been solved, but now you need to obtain the key for the party you want to communicate with. How can you find the key of your target? He said that keyservers cannot map a mail address to a key. It was left a bit unclear what he meant, but he probably referred to the problem of someone uploading a key for your email address without your consent. Later, he mentioned the Web of Trust, which is meant for authenticating the other user’s key. But he disliked the fact that it’s “hard to explain”. He didn’t mention why, though. He did mention that the WoT exposes the global social graph, which is not a desirable feature. He also doubts that the Web of Trust scales, but he left the audience wondering why. To solve the mapping problem, you might imagine keyservers which verify your email address before accepting your key. These, he said, “harm the system”. The problem, he said, is that this system only works with one keyserver which would harm the decentralised nature of the OpenPGP system and bring us back in to the x.500 dark age. While I agree with the conclusion, I don’t fully agree with the premise. I don’t think it’s clear that you cannot operate a verifying server network akin to how it’s currently done. For example, the pool of keyservers could only accept keys which were signed by one of the servers of the pool within the last, say, 6 months. Otherwise, the user has to enrol by following a challenge-response protocol. The devil may be in the details, but I don’t see how it’s strictly impossible.
However, in general, Werner likes the OpenSSH approach better. That is, it opportunistically uses a key and detects when it changes. As with the Web of Trust, the key validation happens on your device, only. Rather than, say, have an external entity selling the trust as with X.509.
Back to the topic. How do you find a key of your partner now? DANE would be an option. It uses DNSSEC which, he said, is impossible to implement a client for. It also needs collaboration of the mail provider. He said that Posteo and mailbox.org have this feature.
Anyway, the user’s mail provider needs to provide the key, he said. Web Key Directory is a new proposal. It uses https for key look-up on a well known name on the domain of the email provider. Think .well-known/openpgp/. It’s not as distributed as DNS but as decentralised as eMail is, he said. It still requires collaboration of the email provider to set the Web service up. The proposal trusts the provider to return genuine keys instead of customised ones. But the system shall only be used for initial key discovery. Later, he mentioned to handle revocation via the protocol™. For some reason, he went on to explain a protocol to submit a key in much more detail rather than expanding on the protocol for the actual key discovery, what happens when the key gets invalid, when it expired, when it gets rolled over, etc.
—-
Next up was Meskio who talked about Key management at LEAP, the LEAP Encryption Access Project. They try to provide a one-stop solution to encrypting all the things™. One of its features is to transparently encrypt emails. To achieve that, it opens a local MTA and an IMAPd to then communicate via a VPN with the provider. It thus builds on the idea of federation the same way current email protocols do, he said. For LEAP to provide the emails, they synchronise the mailbox across devices. Think of a big dropbox share. But encrypted to all devices. They call it soledad which is based on u1db.
They want to protect the user from the provider and the provider from the user. Their focus on ease of use manifests itself in puppet modules that make it easy to deploy the software. The client side is “bitmask“, a desktop application written in Qt which sets everything up. That also includes transparently getting keys of other users. Currently, he said, we don’t have good ways of finding keys. Everything assumes that there is user intervention. They want to change that and build something that encrypts emails even when the user does not do anything. That’s actually quite an adorable goal. Security by default.
Regarding the key validation they intend to do, he mentioned that it’s much like TOFU, but with many many exceptions, because there are many corner cases to handle in that scheme. Keys have different validation levels. The key with the highest validation level is used. When a key roll-over happens, the new key must be signed by the old one and the new key needs to be at least of a validation level as the old one. Several other conditions need to also hold. Quite an interesting approach and I wish that they will get more exposure and users. It’s promising, because they don’t change “too” much. They still do SMTP, IMAP, and OpenPGP. Connecting to those services is different though which may upset people.
—

More key management was referred on by Comodo’s Phillip Hallam-Baker who went then on to talk about The Mathematical Mesh: Management of Keys. He also doesn’t want to change the user experience except for simplifying everything. Every button to push is one too many, he said. And we must not write instructions. He noted that if every user had a key pair, we wouldn’t need passwords and every communication would be secured end-to-end. That is a strong requirement, of course. He wants to have a single trust model supporting every application, so that the user does not have to configure separate trust configurations for S/MIME, OpenPGP, SSH, etc. That again is a bit of a far fetched dream, I think. Certainly worth working towards it, but I don’t believe to experience such a thing in my lifetime. Except when we think of single closed system, of course. Currently, he said, fingerprints are used in two ways: Either users enter them manually or they compare it to a string given by a secure source.
He presented “The Mesh” which is a virtual store for configuration information. The idea is that you can use the Mesh to provision your devices with the data and keys it needs to make encrypted communication happen. The Mesh is thus a bit of a synchronised storage which keeps encrypted data only. It would have been interesting to see him relate the Mesh to Soledad which was presented earlier. Like Soledad, you need to sign up with a provider and connect your devices to it when using the Mesh. His scheme has a master signature key which only signs a to be created administration key. That in turn signs application- and device keys. Each application can create as many keys as it needs. Each device has three device keys which he did unfortunately not go into detail why these keys are needed. He also has an escrow method for getting the keys back when a disaster happens: The private keys are encrypted, secret shared, and uploaded. Then, you can use two out of three shares to get your key back. I wonder where to upload those shares to though and how to actually find your shares back.
Then he started losing me when he mentioned that OpenPGP keyservers, if designed today, would use a “linked notary log (blockchain)”. He also brought (Proxy-) reencryption into the mix which I didn’t really understand. The purpose itself I think I understand: He wants the mesh to cater for services to re-encrypt to the several keys that all of one entity’s devices have. But I didn’t really understand why it’s related to his Mesh at all. All together, the proposal is a bit opportunistic. But it’s great to have some visions…
—

Bernhard Reiter talked about getting more OpenPGP users by 2017. Although it was more about whitewashing the money he receives from German administration… He is doing gpg4win, the Windows port of GnuPG. The question is, he said, how to get GnuPG to a large user base and to make them use it. Not surprisingly, he mentioned that we need to improve the user experience. Once he user gets in touch with cryptography and is exposed to making trust decisions, he said, the user is lost. I would argue otherwise, because the people are heavily exposed to cryptography when using whatsapp. Anyway, he then referred to an idea of his: “restricted documents”. He wants to build a military style of access control for documents. You can’t blame him; it’s probably what he makes money off.
He promised to present ideas for Android and the Web. Android applications, he said, run on devices that are ten times smaller and slower compared to “regular” machines. They did actually conduct a study to find this, and other things, out. Among the other things are key insights such as “the Android permission model allows for deploying end to end encryption”. Genius. They also found out that there is an OpenPGP implementation in Bouncy Castle which people use and that it’s possible to wrap libgcrypt for Java. No shit!!1 They have also identified OpenKeychain and K9 mail as applications using OpenPGP. Wow. As for the Web, their study found out that Webmail is a problem, but that an extension to a Web browser could make end to end encryption possible. Unbelievable. I am not necessarily disappointed given that they are a software company and not a research institute. But I’m puzzled in what reality these results are interesting to the audience of OpenPGP.conf. In any case, his company conducted the study as part of the public tender they won and their results may have been biased by his subcontractors who are deeply involved in the respective projects (i.e. Mailvelope, OpenKeychain, …).
As for his idea regarding UX, his main idea is to implement Web Key Directory (see Werner’s opening talk) discovery mechanism. While I think the approach is good, I still don’t think it is sufficient to make 2017 the year of OpenPGP. My concerns revolve about the UX in non straight-forward cases like people revoking their keys. It’s also one thing to have a nice UX and another to actually have users going for it. Totally unrelated but potentially interesting: He said that the German Federal Office for Information Security (“BSI”) uses 500 workstations with GNU/Linux with a Plasma desktop in addition to Windows.
—-
Holger Krekel then went on to refer about automatic end to end encrypted emails. He is working on an EU funded project called NEXTLEAP. He said that email is refusing to die in favour of Facebook and all the other new kids on the block. He stressed that email is the largest open social messaging system and that many others use it as an anchor of identity. However, many people use it for “SPAM and work” only, he said. He identified various usability problems with end to end encrypted email: key distribution, preventing SPAM, managing secrets across devices, and handle device or key loss.
To tackle the key distribution problem, he mentioned CONIKS, Werner’s Webkey, Mailvelope, and DANE as projects to look into. With these, the respective providers add APIs to find public keys for a person. We know about Werner’s Webkey proposal. CONIKS, in short, is a key transparency approach which requires identity providers to publicly testify your key. Mailvelope automatically asks a verifying key server to provide the recipient’s key. DANE uses DNS with DNSSEC to distribute keys.
He proposed to have inline keys. That means to attach keys and cryptographic information to your emails. When you receive such a message, you would parse the details and use them for encryption the next time you create a message. The features of such a scheme, he said, are that it is more private in the sense that there is no public key server which exposes your identity. Also, it’s simpler in the sense that you “only” need to get support from MUAs and you don’t need to care about extra infrastructure. He identified that we need to run a protocol over email if we ever want to support that scheme. I’m curious to see that, because I believe that it’s good if we support protocols via email. Much like Outlook already does with its voting. SPAM prevention would follow naturally, he said. Because the initial message is sent as plain text, you can detect SPAM. Only if you reply, the other party gets your key, he said. I think it should be possible to get a person’s key out of band, but that doesn’t matter much, I guess. Anyway, I couldn’t really follow that SPAM argument, because it seems to imply that we can handle SPAM in the plain text case. But if that was the case, then we wouldn’t have the SPAM problem today. For managing keys, he thinks of sharing your keys via IMAP, like in the whiteout proposal.
—-

Stefan Marsiske then talked about his concerns regarding the future directions of GnuPG. He said he did some teaching regarding crypto and privacy preserving tools and that he couldn’t really recommend GnuPG to anyone, because it could not be used by the people he was teaching. Matt Green and Schneier both said that PGP is not able to secure email or that email is “unsecurable”. This is inline with the list that secushare produced. The saltpack people also list some issues they see with OpenPGP. He basically evaluated gpg against the list of criteria established in the SoK paper on instant messaging which is well worth a read.
—

Lutz Donnerhacke then gave a brief overview of the history of OpenPGP. He is one of the authors of the initial OpenPGP standard. In 1992, he said, he read about PGP on the UseNet. He then cared about getting PGP 2.6.3(i)n out of the door to support larger keys than 1024 and fix other bugs that annoyed him. Viacrypt then sold PGP4 which was based on PGP2. PGP5 was eventually exported in books and were scanned back in during HIP97 and CCCamp99, he said. Funnily enough, a bug lurked for about five years, he said. Their get_random always returned 1…
Funnily enough he uses a 20 years old V3 key so at least his Key ID is trivially forgeable, but the fingerprint should also be easy to create. He acknowledges it but doesn’t really care. Mainly, because he “is a person from the last century”. I think that this mindset is present in many people’s heads…
—
The next day Intevation’s Andre Heinecke talked about the “automated use of gpg through gpgme“. GPGME is the abbreviation of “GnuPG made easy” and is meant to be a higher level abstraction for gpg. “gpg is a tool not a library”, he said. For a library you can apply versioning while the tool may change its output liberally, he said. He mentions gpg’s machine interface with --with-colons and that changes to that format will break things. GpgME will abstract that for you and tries to make the tool a library. There is a defined interface and “people should use it”. A selling point is that it works with all gpg versions.
When I played around with gpgme, I found it convoluted and lacking basic operations. I think it’s convoluted because it is highly stateful and you need to be careful with calling (many) functions in the correct order if you don’t want it to complain. It’s lacking, because signing other people’s keys is a weird thing to do and the interface is not designed with that in mind. He also acknowledged that it is a fairly low level API in the sense that every option has to be set distinctly and that editing keys is especially hard. In gpgme, he said, operations are done based on contexts that you have to create. The context can be created for various gpg protocols. Surprisingly, that’s not only OpenPGP, but also CMS, GpgConf, and others.
I don’t think GNOME Software is ported to gpgme. At least Evolution and Seahorse call gpg directly rather than using gpgme. We should change that! Although gpgme is a bit of a weird thing. Normally™ you’d have a library build a tool with it. With gpgme, you have a tool (gpg) and build a library. It feels wrong. I claim that if we had an OpenPGP library that reads and composes packets we would be better off.
—
Vincent and Dominik came to talk about UX decisions in OpenKeychain, the Android OpenPGP implementation. It does key management, encryption and decryption of files, and other OpenPGP operations such as signing keys. The speakers said that they use bouncy castle for the crypto and OpenPGP serialisation. They are also working on K9 which will support PGP/MIME soon. They have an Open Tech Fund which finances that work. In general, they focused on the UX to make it easy for the consumer. They identified “workflows” users possibly want to carry out with their app. Among them are the discovery and exchange of keys, as well as confirming them (signing). They gave nice looking screenshots of how they think they made the UI better. They probably did, but I found it the foundations a bit lacking. Their design process seems to be a rather ad-hoc affair and they themselves are their primary test subjects. While it’s good work, I don’t think it’s easily applicable to other projects.
An interesting thing happened (again): They deviate from the defaults that GnuPG uses. Unfortunately, the discussions revolving about that fact were not very elaborate. I find it hard to imagine that both tools have, say, different default key lengths. Both tools try to prevent mass surveillance so you would think that they try to use the same defaults to achieve their goal. It would have been interesting to find out what default value serves the desired purpose better.
—

Next up was Kritian Fiskerstrand who gave an update on the SKS keyserver network. SKS is the software that we trust our public keys with. SKS is written in OCaml, which he likes, but of which he said that people have different opinions on. SKS is single threaded which is s a problem, he said. So you need to have a reverse proxy to handle more than one client.
He was also talking about the Evil32 keys which caused some stir-up recently. In essence, the existing OpenPGP keys were duplicated but with matching short keyids. That means that if you lookup a key by its short key ID, you’re screwed, because you get the wrong key. If you are using the name or email address instead, then you also have a problem. People were upset about getting the wrong key when having asked the keyserver to deliver.
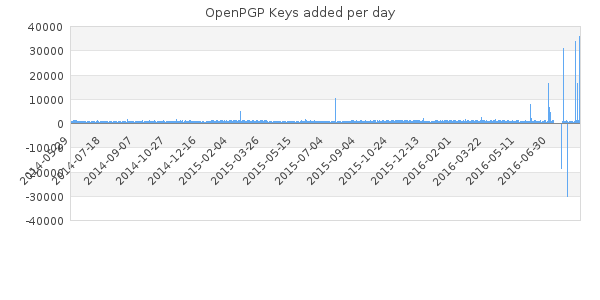
He said that it’s absolutely no problem because users should verify the keys anyway. I can only mildly agree. It’s true that users should do that. But I think we would live in a nicer world where we could still maintain a significantly high security level of such a rigorous verification does not happen. If he really maintains that point of view then I’m wondering why he is allowing keys to be retrieved by name, email address, or anything else than the fingerprint in first place.
—-

Volker Birk from pretty Easy privacy talked about their project which aims at making encrypted email possible for the masses.
they make extensive use of gpgme and GnuNet, he said. Their focus is “privacy by default”. Not security, he said. If security and privacy are contradicting in some cases, they go for privacy instead of security. For example, the Web of Trust is a good idea for security, but not for privacy, because it reveals the social graph. I really like that clear communication and the admission of security and privacy not necessarily going well together. I also think that keyservers should be considered harmful, mainly because they are learning who is attempting to communicate with whom. He said that everything should be decentralised and peer-to-peer. Likewise, a provider should not be responsible for binding an email address to a key. The time was limited, unfortunately, so the actual details of how it’s supposed to be working were not discussed. They wouldn’t be the first ones to attempt a secure or rather privacy preserving solution. In the limited time, however, he showed how to use their Python adapter to have it automatically locate a public key of a recipient and encrypt to it. They have bindings for various other languages, too.
Interestingly, a keysigning “party” was scheduled on the first evening but that didn’t take place. You would expect that if anybody cared about that it is the OpenPGP hardcore hackers, all of which were present. But not a single person (as in nobody, zero “0”, null) was interested. You can’t blame them. It’s probably been a cool thing when you were younger and GnuPG this was about preventing the most powerful targetted attacks. I think people realised that you can’t have people mumble base16 encoded binary strings AND mass adoption. You need to bring at least cake to the party… Anyway, as you might be aware, we’re working towards a more pleasant key signing experience 🙂 So stay tuned for updates.