
Let me start by saying that I now also have a Mastodon account, so please follow me on @Cfkschaller@fosstodon.org for news and updates around Fedora Workstation, PipeWire, Wayland, LVFS and Linux in general.
Fedora vs Fedora Workstation
Before I start with the general development update I want to mention something I mentioned quite a few times before and that is the confusion I often find people have about what is Fedora and what is Fedora Workstation.
Fedora Workstation
Fedora is our overall open source project and community working on packaging components and software for the various outputs that the Fedora community delivers. Think of the Fedora community a bit like a big group of people providing well tested and maintained building blocks to be used to build operating systems and applications. As part of that bigger community you have a lot of working groups and special interest groups working to build something with those building blocks and Fedora Workstation is the most popular thing being built from those building blocks. That means that Fedora Workstation isn’t ‘Fedora’ it is something created by the Fedora community alongside a lot of other projects like Fedora Server, Silverblue and Fedora spins like Fedora KDE and Fedora Kinoite. But all them should be considered separate efforts built using a shared set of building blocks.
Putting together an operating system like Fedora Workstation is more than just assembling a list of software components to include though, it is also about setting policies, default configurations, testing and QE and marketing. This means that while Fedora Workstation contains many of the same components of other things like the Fedora KDE Plasma Desktop spin, the XFCE Desktop spin, the Cinnamon spin and so on, they are not the same thing. And that is not just because the feature set of GNOME is different from the feature set of XFCE, it is because each variant is able to set their own policies, their own configurations and do their own testing and QE. Different variants adopted different technologies at different times, for instance Fedora Workstation was an early adopter of new technologies like Wayland and PipeWire. So the reason I keep stressing this point is that I to this day often see comments or feedback about ‘Fedora’, feedback which as someone spending a lot of effort on Fedora Workstation, sometimes makes no sense to me, only to reach out and discover that they where not using Fedora Workstation, but one of the spins. So I do ask people, especially those who are members of the technology press to be more precise in their reviews, about if they are talking about Fedora Workstation or another project that is housed under the Fedora umbrella and not just shorten it all to ‘Fedora’.
Fedora Workstation
Anyway, onwards to updating you on some of the work we are doing in and around Fedora Workstation currently.
High Dynamic Range – HDR

HDR
A major goal for us at Red Hat is to get proper HDR support into Fedora and RHEL. Sebastian Wick is leading that effort for us and working with partners and contributors across the community and the industry. For those who read my past updates you know I have been talking about this for a while, but it has been slow moving both because it is a very complex issue that needs changes from the kernel graphics drivers up through the desktop shell and into the application GUI toolkits. As Sebastian put it when I spoke with him, HDR forces us (the Linux ecosystem) to take colors seriously for the first time and thus it reveals a lot of shortcomings up through our stack, many which are not even directly HDR related.
Support for High Dynamic Range (HDR) requires compositors to produce framebuffers in specific HDR encodings with framebuffers from different clients. Most clients nowadays are unaware of HDR, Wide Color Gamuts (WCG) and instead produce pixels with RGB encodings which look okay on most displays which approximate sRGB characteristics. Converting different encodings to the common HDR encoding requires clients to communicate their encoding, the compositor to adjust and convert between the different color spaces, and the driver to enable an HDR mode in the display. Converting between the encodings should ideally be done by the scanout engine of the GPU to keep the latency and power benefits of direct scanout. Similarly, applications and toolkits have to understand different encodings and how to convert between them to make use of HDR and WCG features.
Essentially, HDR forces us to handle color correctly and makes color management an integral part of the system.
So in no particular order here are some of the issues we have found and are looking at:
- Display brightness controls are today limited to a single, internal monitor and setting the brightness level to zero might or might not turn off the screen. The luminance setting might scale linearly or approximate the human brightness perception depending on hardware. Hans de Goede on our team is working on fixing these issues to get as coherent behaviour from different hardware as possible.
- GStreamers glcolorconvert element doesn’t actually convert colors, which breaks playback of videos on some HDR and WCG encoded videos.
- There are also some challenges with limitations in the current KMS API. User space cannot select the bit depth of the colors sent to the display, nor whether a YUV format with subsampling is used. Both are driver internal magic which can reduce the quality of the image but might be required to light up displays with the limited bandwidth available. The handling of limited and full range colors is driver defined and an override for badly behaving sinks is only available on Intel and VC4. And offloading the color transformations to the scanout hardware is impossible with the KMS API. Available features, their order and configurability varies a lot between hardware. To avoid any discrepancy between the offloaded and the software case the entire color pipeline has to be predictable by user space. We’re currently working together with hardware vendors to look at ways forward here.
- To handle the communication of the color metadata between clients and compositors Sebastian is working with the wider community to define two work-in-progress wayland protocols. The color representation protocol describes how to go from a tristimulus value to the encoding (this includes YUV to RGB conversions, full vs limited color range, chroma siting) and the color-management protocol for describes the tristimulus values (primaries, whitepoint, OETF, ICC profile, dynamic range).
- There is also now a repository on FreeDesktop.org’s GitLab instance to document and discuss all things related to colors on Linux. This required a lot of research, thinking and discussing about how everything is supposed to fit together.
- Compositors have to look up information from EDID and DisplayID for HDR. The data is notoriously unreliable currently so Simon Ser, Pekka Paalanen and Sebastian started a new project called libdisplay-info for parsing and quirking EDID+DisplayID.
- Mutter is now in charge of ICC profile handling and we’re planning to deprecate the old colord daemon. Work on supporting high bit depth framebuffers and enabling HDR mode is ongoing and should give us an experimental setup for figuring out how to combine different SDR and HDR content.
Headless display and automated test of the GNOME Shell
Jonas Ådahl has been working on getting headless display working correctly under Wayland for a bit and as part of that also been working on using the headless display support to enable automated testing of gnome-shell. The core work to get GNOME Shell to be able to run headless on top of Wayland finished some time ago, but there are still some related tasks that need further work.
- The most critical is remote login. With some hand holding it works and supports TPM based authentication for single user sessions, but currently lacks a nice way to start it. This item is on the very top of Jonas todo list so hopefully we can cross it off soon.
- Remote multi user login: This feature is currently in active development and will make it possible to get a gdm login screen via gnome-remote-desktop where one can type ones username and password getting a headless session. The remote multi user login is a collaboration between Jonas Ådahl, Pascal Nowack, the author of the RDP backend in gnome-remote-desktop and Joan Torres from SUSE.
- Testing: Jonas has also been putting in a lot of work recently to improve automated testing of GNOME Shell on the back of the headless display support. You can read more about that in his recent blog post on the subject.
HID-BPF
Benjamin Tissoires has been working on a set of kernel patches for some time now that implements something called HID-BPF. HID referring to Human Interface Devices (like mice, keyboard, joysticks and so on) and BPF is a kernel and user-space observability scheme for the Linux kernel. If you want to learn more about BPF in general I recommend this Linux Journal article on the subject. This blog post will talk specifically about HID-BPF and not BPF in general. We are expecting this patcheset to either land in 6.2 or it might get delayed to 6.3.
The kernel documentation explains in length and through examples how to use HID-BPF and when. The summary would be that in the HID world, we often have to tweak a single byte on a device to make it work, simply because HW makers only test their device under Windows, and they can provide a “driver” that has the fix in software. So most of the time it comes to changing a few bytes in the report descriptor of the HID device, or on the fly when we receive an event. For years, we have been doing this sort of fixes in the kernel through the normal kernel driver model. But it is a relatively slow way of doing it and we should be able to be more efficient.
The kernel driver model process involves multiple steps and requires the reporter of the issue to test the fix at every step. The reporter has an issue and contacts a kernel developer to fix that device (sometimes, the reporter and the kernel developers are the same person). To be able to submit the fix, it has to be tested, and so compiled in the kernel upstream tree, which means that we require regular users to compile their kernel. This is not an easy feat, but that’s how we do it. Then, the patch is sent to the list and reviewed. This often leads to v2, v3 of the patch requiring the user to recompile a new kernel. Once it’s accepted, we still need to wait for the patch to land in Linus’ tree, and then for the kernel to be taken by distributions. And this is only now that the reporter can drop the custom kernel build. Of course, during that time, the reporter has a choice to make: should I update my distro kernel to get security updates and drop my fix, or should I recompile the kernel to keep everybody up to date, or should I just stick with my kernel version because my fix is way more important?
So how can HID-BPF make this easier?
So instead of the extensive process above. A fix can be written as a BPF program which can be run on any kernel. So instead of asking the reporter to recompile the upstream kernel, a kernel developer can compile the BPF program, and provide both the sources and the binary to the tester. The tester now just has to drop that binary in a given directory to have a userspace component automatically binding this program to the device. When the review process happens, we can easily ask testers to update their BPF program, and they don’t even need to reboot (just unplug/replug the target device). For the developers, we continue doing the review, and we merge the program directly in the source tree. Not even a single #define needs to differ. Then an automated process (yet to be fully determined, but Benjamin has an RFC out there) builds that program into the kernel tree, and we can safely ship that tested program. When the program hits the distribution kernel, the user doesn’t even notice it: given that the kernel already ships that BPF program, the userspace will just not attach itself to the device, meaning that the test user will even benefit from the latest fixes if there were any without any manual intervention. Of course, if the user wants to update the kernel because of a security problem or another bug, the user will get both: the security fix and the HID fix still there.
That single part is probably the most appealing thing about HID-BPF. And of course, this translate very well in the enterprise Linux world: when a customer has an issue on a HID device that can be fixed by HID-BPF, we can provide to that customer the pre-compiled binary to introduce in the filesystem without having to rely on a kernel update.
But there is more: we can now start implementing a HID firewall (so that only fwupd can change the firmware of a HID device), we can also tell people not to invent ad-hoc kernel APIs, but rely on eBPF to expose that functionality (so that if the userspace program is not there, we don’t even expose that capability). And we can be even more creative, like deciding to change how the kernel presents a device to the userspace.

Benjamin speaking a Kernel Recipies
For more details I recommend checking out the talk Benjamin did at the kernel recipes conference.
MIPI Camera
Kate Hsuan and Hans de Goede have been working together trying to get the Linux support for MIPI cameras into shape. MIPI cameras are the next generation of PC cameras and you are going to see more and more laptops shipping with these so it is critical for us to get them working and working well and this work is also done in the context of our close collaboration with Lenovo around the Fedora laptops they offer.
Without working support, Fedora Workstation users who buy a laptop equipped with a MIPI camera will only get a black image. The long term solution for MIPI cameras is a library called libcamera which is a project lead by Laurent Pinchart and Kieran Bingham from IdeasOnBoard and sponsored by Google. For desktop Linux users you probably are not going to have applications interact directly with libcamera though, instead our expectation is that your applications use libcamera through PipeWire and the Flatpak portal. Thanks to the work of the community we now have support for the Intel IPU3 MIPI stack in the kernel and through libcamera, but the Intel IPU6 MIPI stack is the one we expect to see head into laptops in a major way and thus our current effort is focused on bringing support for that in a useful way to Fedora users. Intel has so far provided a combination of binary and limited open source code to support these cameras under Linux, by using GStreamer to provide an emulated V4l2 device. This is not a great long term solution, but it does provide us with at least an intermediate solution until we can get IPU6 working with libcamera. Based on his successful work on IPU3, Hans de Goede has been working on getting the necessary part of the Intel open source driver for IPU6 upstreamed since that is the basic interface to control the IPU6 and image sensor. Kate has been working on packaging all the remaining Intel non-free binary and software releases into RPM packages. The packages will provide the v4l2loopback solution which should work with any software supporting V4l2. These packages were planned to go live soon in RPM fusion nonfree repository.
LVFS – Linux Vendor Firmware Service
Richard Hughes is still making great strides forward with the now ubiques LVFS service. A few months ago we pushed the UEFI dbx update to the LVFS, which has now been downloaded over 4 million times. This pushed the total downloads to a new high of 5 million updates just in the 4 weeks of September, although it’s returned to a more normal growth pattern now.
The LVFS also now supports 1,163 different devices, and is being used by 137 different vendors. Since we started all those years ago we’ve provided at least 74 million updates to end-users although it’s probably even more given that lots of Red Hat customers mirror the entire LVFS for internal use. Not to mention that thanks to Richards collaboration with Google LVFS is now an integral part of the ‘Works with ChromeOS’ program.
On the LVFS we also now show the end-user provided HSI reports for a lot of popular hardware. This is really useful to check how secure the device will likely be before buying new hardware, regardless if the vendor is uploading to the LVFS. We’ve also asked ODMs and OEMs who do actually use the LVFS to use signed reports so we can continue to scale up LVFS. Once that is in place we can continue to scale up, aiming for 10,000 supported devices, and to 100 million downloads.

Latest LVFS statistics
PipeWire & OBS Studio
In addition to doing a bunch of bug fixes and smaller improvements around audio in PipeWire, Wim Taymans has spent time recently working on getting the video side of PipeWire in shape. We decided to use OBS Studio as our ‘proof of concept’ application because there was already a decent set of patches from Georges Stavracas and Columbarius that Wim could build upon. Getting the Linux developer community to adopt PipeWire for video will be harder than it was for audio since we can not do a drop in replacement, instead it will require active porting by application developers. Unlike for audio where PipeWire provides a binary compatible implementation of the ALSA, PulesAudio and JACK apis we can not provide a re-implementation of the V4L API that can run transparently and reliably in place of the actual V4L2. That said, Wim has created a tool called pw-v4l2 which tries to redirect the v4l2 calls into PipeWire, so you can use that for some testing, for example by running ‘pw-v4l2 cheese’ on the command line and you will see Cheese appear in the PipeWire patchbay applications Helvum and qpwgraph. As stated though it is not reliable enough to be something we can for instance have GNOME Shell do as a default for all camera handling applications. Instead we will rely on application developers out there to look at the work we did in OBS Studio as a best practice example and then implement camera input through PipeWire using that. This brings with it a lot of advantages though, like transparent support for libcamera alongside v4l2 and easy sharing of the video streams between multiple applications.
One thing to note about this is that at the moment we have two ‘equal’ video backends in PipeWire, V4L2 and libcamera, which means you get offered the same device twice, once from v4l2 and once from libcamera. Obviously this is a little confusing and annoying. Since libcamera is still in heavy development the v4l2 backend is more reliable for now, so Fedora Workstation we will be shipping with the v4l2 backend ‘out of the box’, but allow you to easily install the libcamera backend. As libcamera matures we will switch over to the libcamera backend (and allow you to install the v4l backend if you still need/want it for some reason.)
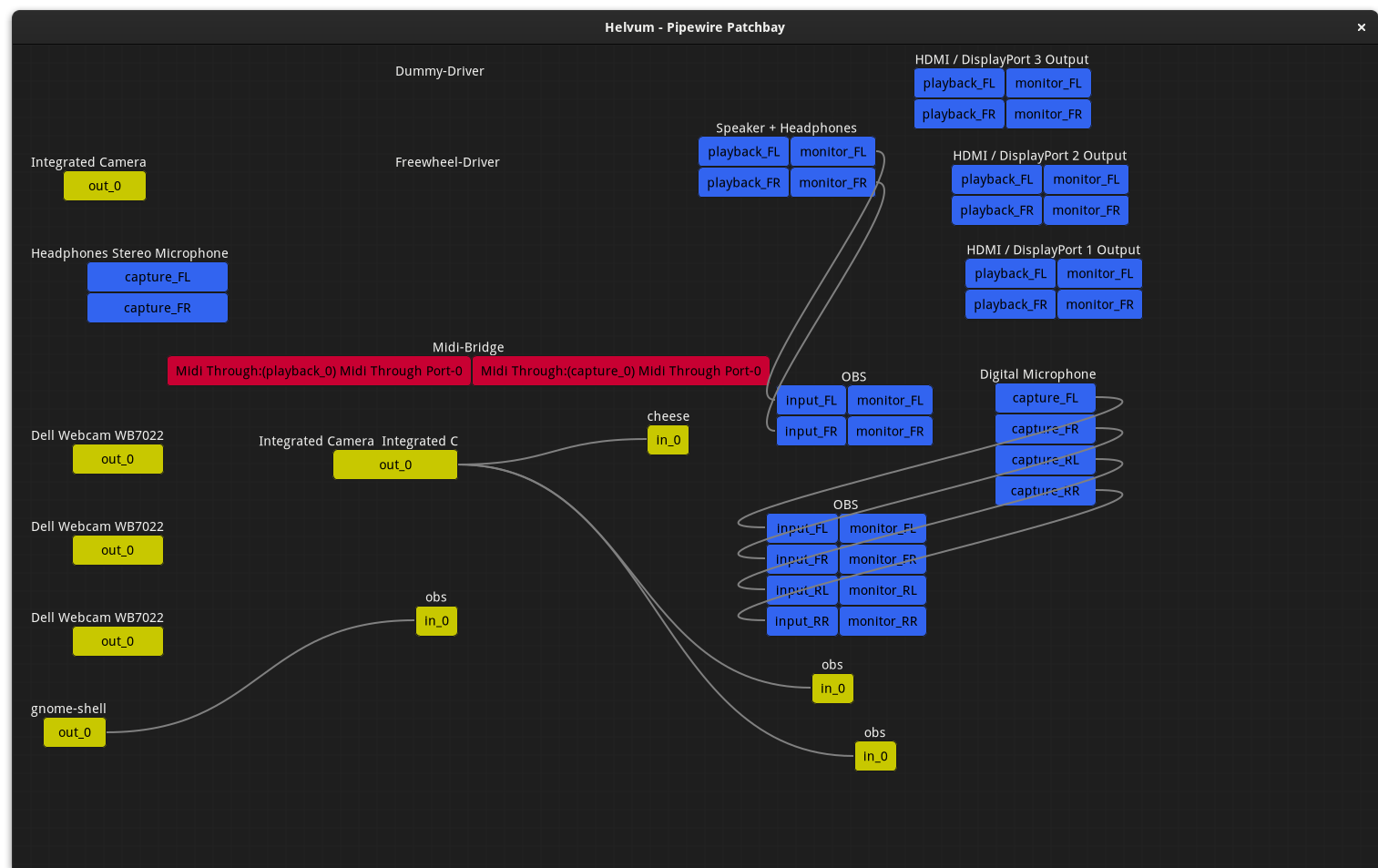
Helvum running OBS Studio with native PipeWire support and Cheese using the pw-v4l2 re-directer.
Of course the most critical thing to get ported to use PipeWire for camera handling is the web browsers. Luckily thanks to the work of Pengutronix there is a patchset ready to be merged into WebRTC, which is the implementation used by both Chromium/Chrome and Firefox. While I can make no promises we are currently looking to see if it is viable for us to start shipping that patch in the Fedora Firefox package soon.
And finally thanks to the work by Jan Grulich in collaboration with Google engineers PipeWire is now included in the Chromium test build which has allowed Google to enable PipeWire for screen sharing enabled by default. Having PipeWire in the test builds is also going to be critical for getting the camera handling patch merged and enabled.
Flathub, Flatpak and Fedora
As I have spoken about before, we have a clear goal of moving as close as we can to a Flatpak only model for Fedora Workstation. The are a lot of reasons for this like making applications more robust (i.e. the OS doesn’t keep moving fast underneath the application), making updates more reliable (because an application updating its dependencies doesn’t risk conflicting with the needs of other application), making applications more portable in the sense that they will not need to be rebuilt for each variety of operating system, to provide better security since applications can be sandboxed in a container with clear access limitations and to allow us to move to an OS model like we have in Silverblue with an immutable core.
So over the last years we spent a lot of effort alongside other members of the Linux community preparing the ground to allow us to go in this direction, with improvements to GTK+ and Qt for instance to allow them to work better in sandboxes like the one provided by Flatpak.
There has also been strong support and growth around Flathub which now provides a wide range of applications in Flatpak format and being used for most major Linux distributions out there. As part of that we have been working to figure out policies and user interface to allow us to enable Flathub fully in Fedora (currently there is a small allowlisted selection available when you enable 3rd party software). This change didn’t make it into Fedora Workstation 37, but we do hope to have it ready for Fedora Workstation 38. As part of that effort we also hope to take another look at the process for building Flatpaks inside Fedora to reduce the barrier for Fedora developers to do so.
So how do we see things evolving in terms of distribution packaging? Well that is a good question. First of all a huge part of what goes into a distribution is not Flatpak material considering that Flatpaks are squarely aimed at shipping GUI desktop applications. There are a huge list of libraries and tools that are either used to build the distribution itself, like Wayland, GNOME Shell, libinput, PipeWire etc. or tools used by developers on top of the operating system like Python, Perl, Rust tools etc. So these will be needed to be RPM packaged for the distribution regardless. And there will be cases where you still want certain applications to be RPM packaged going forward. For instance many of you hopefully are aware of Container Toolbx, our effort to make pet containers a great tool for developers. What you install into your toolbox, including some GUI applications like many IDEs will still need to be packages as RPMS and installed into each toolbox as they have no support for interacting with a toolbox from the host. Over time we hope that more IDEs will follow in GNOME Builders footsteps and become container aware and thus can be run from the host system as a Flatpak, but apart from Owen Taylors VS Code integration plugin most of them are not yet and thus needs to be installed inside your Toolbx.
As for building Flatpaks in Fedora as opposed to on Flathub, we are working on improving the developer experience around that. There are many good reasons why one might want to maintain a Fedora Flatpak, things like liking the Fedora content and security policies or just being more familiar with using the tested and vetted Fedora packages. Of course there are good reasons why developers might prefer maintaining applications on Flathub too, we are fine with either, but we want to make sure that whatever path you choose we have a great developer and package maintainer experience for you.
Multi-Stream Transport
Multi-monitor setups have become more and more common and popular so one effort we spent time on for the last few years is Lyude Paul working to clean up the MST support in the kernel. MST is a specification for DisplayPort that allows multiple monitors to be driven from a single DisplayPort port by multiplexing several video streams into a single stream and sending it to a branch device, which demultiplexes the signal into the original streams. DisplayPort MST will usually take the form of a single USB-C or DisplayPort connection. More recently, we’ve also seen higher resolution displays – and complicated technologies like DSC (Display Stream Compression) which need proper driver support in order to function.

Making setups like docks work is no easy task. In the Linux kernel, we have a set of shared code that any video driver can use in order to much more easily implement support for features like DisplayPort MST. We’ve put quite a lot of work into making this code both viable for any driver to use, but also to build new functionality on top of for features such as DSC. Our hope is that with this we can both encourage the growth of support for functionality like MST, and support of further features like DSC from vendors through this work. Since this code is shared, this can also come with the benefit that any new functionality implemented through this path is far easier to add to other drivers.
Lyude has mostly finished this work now and recently have been focusing on fixing some regressions that accidentally came upstream in amdgpu. The main stuff she was working on beforehand was a lot of code cleanup, particularly removing a bunch of the legacy MST code. For context: with kernel modesetting we have legacy modesetting, and atomic modesetting. Atomic modesetting is what’s used for modern drivers, and it’s a great deal simpler to work with than legacy modesetting. Most of the MST helpers were written before atomic was a thing, and as a result there was a pretty big mess of code that both didn’t really need to be there – and actively made it a lot more difficult to implement new functionality and figure out whether bug fixes that were being submitted to Lyude were even correct or not. Now that we’ve cleaned this up though, the MST helpers make heavy use of atomic and this has definitely simplified the code quite a bit.