I was fortunate enough to be invited to Kyiv to keynote (video) the local Open Source Developer Network conference. Actually, I had two presentations. The opening keynote was on building a more secure operating system with fewer active security measures. I presented a few case studies why I believe that GNOME is well positioned to deliver a nice and secure user experience. The second talk was on PrivacyScore and how I believe that it makes the world a little bit better by making security and privacy properties of Web sites transparent.
The audience was super engaged which made it very nice to be on stage. The questions, also in the hallway track, were surprisingly technical. In fact, most of the conference was around Kernel stuff. At least in the English speaking track. There is certainly a lot of potential for Free Software communities. I hope we can recruit these excellent people for writing Free Software.
Lennart eventually talked about CAsync and how you can use that to ship your images. I’m especially interested in the cryptography involved to defend against certain attacks. We also talked about how to protect the integrity of the files on the offline disk, e.g. when your machine is off and some can access the (encrypted) drive. Currently, LUKS does not use authenticated encryption which makes it possible that an attacker can flip some bits in the disk image you read.
Canonical’s Christian Brauner talked about mounting in user namespaces which, historically, seemed to have been a contentious topic. I found that interesting, because I think we currently have a problem: Filesystem drivers are not meant for dealing with maliciously crafted images. Let that sink for a moment. Your kernel cannot deal with arbitrary data on the pen drive you’ve found on the street and are now inserting into your system. So yeah, I think we should work on allowing for insertion of random images without having to risk a crash of the system. One approach might be libguestfs, but launching a full VM every time might be a bit too much. Also you might somehow want to promote drives as being trusted enough to get the benefit of higher bandwidth and lower latency. So yeah, so much work left to be done. ouf.
Then, Tycho Andersen talked about forwarding syscalls to userspace. Pretty exciting and potentially related to the disk image problem mentioned above. His opening example was the loading of a kernel module from within a container. This is scary, of course, and you shouldn’t be able to do it. But you may very well want that if you have to deal with (proprietary) legacy code like Cisco, his employer, does. Eventually, they provide a special seccomp filter which forwards all the syscall details back to userspace.
As I’ve already mentioned, the conference was highly technical and kernel focussed. That’s very good, because I could have enlightening discussions which hopefully get me forward in solving a few of my problems. Another one of those I was able to discuss with Jakob on the days around the conference which involves the capabilities of USB keyboards. Eventually, you wouldn’t want your machine to be hijacked by a malicious security device like the Yubikey. I have some idea there involving modifying the USB descriptor to remove the capabilities of sending funny keys. Stay tuned.
Anyway, we’ve visited the city and the country before and after the event and it’s certainly worth a visit. I was especially surprised by the coffee that was readily available in high quality and large quantities.
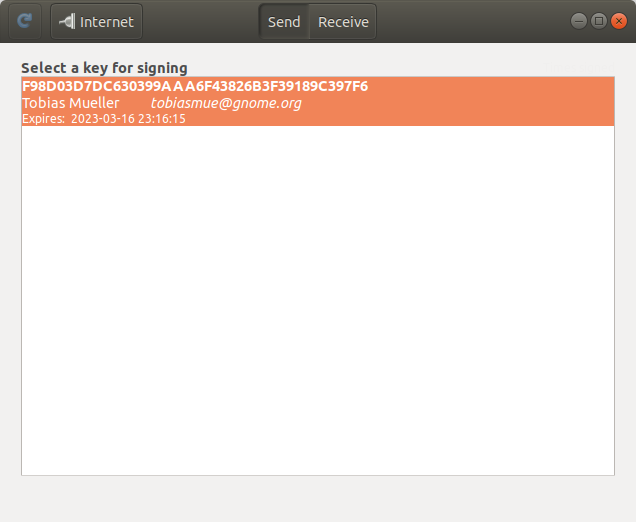
tl;dr: We have a new Keysign release with support for exchanging keys via the Internet.
I am very proud to announce this version of GNOME Keysign, because it marks an important step towards a famous “1.0”. In fact, it might be just that. But given the potentially complicated new dependencies, I thought it’d be nice to make sort of an rc release.
The main feature is a transport via the Internet. In fact, the code has been lurking around since last summer thanks to Ludovico’s great work. I felt it needed some massaging and more gentle introduction to the code base before finally enabling it.
For the transport we use Magic Wormhole, an amazing package for transferring files securely. If you don’t know it yet, give it a try. It is a very convenient tool for sending files across the Internet. They have a rendezvous server so that it works in NATted environments, too. Great.
You may wonder why we need an Internet transport, given that we have local network and Bluetooth already. And the question is good, because initially I didn’t think that we’d expose ourselves to the Internet. Simply because the attack surface is just so much larger and also because I think that it’s so weird to go all the way through the Internet when all we need is to transfer a few bytes between two physically close machines. It doesn’t sound very clever to connect to the Internet when all we need is to bridge 20 centimetres.
Anyway, as it turns out, WiFi access points don’t allow clients to connect to each other 🙁 Then we have Bluetooth, but it’s still a bit awkward to use. My impression is that people are not satisfied with the quality of Bluetooth connections. Also, the Internet is comparatively easy to use, both as a programmer and a user.
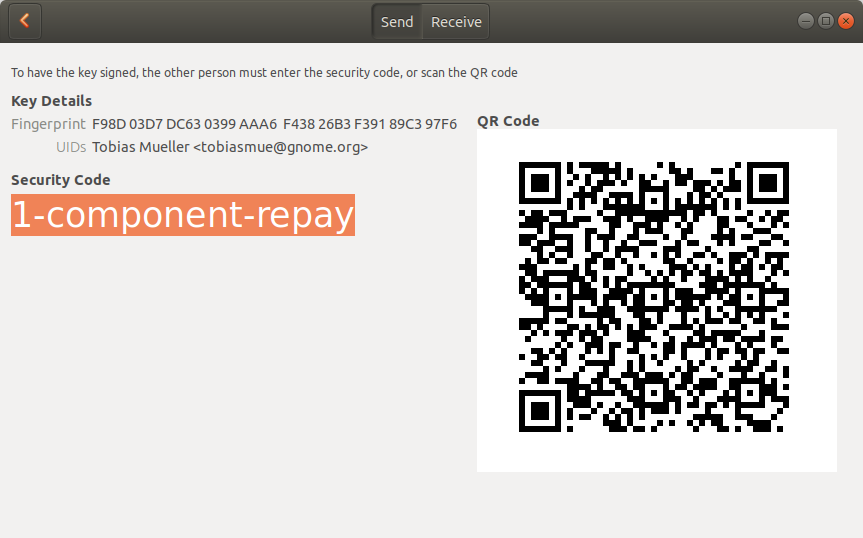
Of course, we now also have the option to exchange keys when not being physically close. I do not recommend that, though, because our security assumes the visual channel to be present and, in fact, secure. In other words: Scan the barcode for a secure key signing experience. Be aware that if you transfer the “security code” manually via other means, you may be compromised.
With this change, the UX changes a bit for the non-Internet transports, too. For example, we have a final page now which indicates success or failure. We can use this as a base for accompanying the signing process further, e.g. sign the key again with a non-exportable short-term signature s.t. the user can send an email right away. Or exchange the keys again after the email has been received. Exciting times ahead.
Now, after the wall of text, you may wonder how to get hold of this release. It should show up on Flathub soon.
I’ve more or less just returned from this year’s GUADEC in Almeria, Spain where I got to talk about assessing and improving the security of our apps. My main point was to make people use ASan, which I think Michael liked 😉 Secondarily, I wanted to raise awareness for the security sensitivity of some seemingly minor bugs and how the importance of getting fixes out to the user should outweigh blame shifting games.
I presented a three-staged approach to assess and improve the security of your app: Compilation time, Runtime, and Fuzzing. First, you use some hardening flags to compile your app. Then you can use amazing tools such as ASan or Valgrind. Finally, you can combine this with afl to find bugs in your code. Bonus points if you do that as part of your CI.
I encountered a few problems, when going that route with Flatpak. For example, the libasan.so is not in the Platform image, so you have to use an extension to have it loaded. It’s better than it used to be, though. I tried to compile loads of apps with ASan in the past and I needed to compile a custom GCC. And then mind the circular dependencies, e.g. libmfpr is needed by GCC. If I then compile a libmfpr with ASan, then GCC would stop working, because gcc itself is not linked against ASan. It seems silly to have those annoyances in the stack. And it is. I hope that by making people play around with these technologies a bit more, we can get to a point where we do not have to catch those time consuming bugs.
Panorama in Frigiliana
The organisation around the presentation was a bit confusing as the projector didn’t work for the first ten minutes. And it was a bit unclear who was responsible for making it work. In that room the audio also used to be wonky. I hope it went well alright after all.
It’s been a while after my last post. This time, we have many exciting news to share. For one, we have a new release of GNOME Keysign which fixes a few bugs here and there as well as introduces Bluetooth support. That is, you can transfer your key with your buddy via Bluetooth and don’t need a network connection. In fact, it becomes more and more popular for WiFis to block clients talking to each other. A design goal is (or rather: was, see down below) to not require an Internet connection, simply because it opens up a can of worms with potential failures and attacks. Now you can transfer the key even if your WiFi doesn’t let you communicate with the other machine. Of course, both of you need have to have Bluetooth hardware and have it enabled.
The other exciting news is the app being on Flathub. Now it’s easier than ever to install the app. Simply go to Flathub and install it from there. This is a big step towards getting the app into users’ hands. And the sandbox makes the app a bit more trustworthy, I hope.
The future brings cool changes. We have already patches lined up that bring an Internet transport with the app. Yeah, that’s contrary to what I’ve just said a few paragraphs above. And it does cause some issues in the UI, because we do not necessarily want the user to use the Internet if the local transport just works. But that “if” is unfortunately getting bigger and bigger. So I’m happy to have a mix of transports now. I’m wondering what the best way is to expose that information to the user, though. Do we add a button for the potentially privacy invading act of connecting to the Internet? If we do, then why do we not offer buttons for the other transports like Bluetooth or the local network?
Similar to last year I managed to attend the Gulasch Programmier-Nacht (GPN) in Karlsruhe, Germany. Not only did I attend, I also managed to squeeze in a talk about PrivacyScore. We got the prime time slot on the opening day along with all the other relevant talks, including the Eurovision Song Contest, so we were not overly surprised that the audience had a hard time deciding where to go and eventually decided to attend talks which were not recorded. Our talk was recorded and is available here.
Given the tough selection of the audience by the other talks, we had the people who were really interested. And that showed during the official Q&A as well as in the hallway track. We exchanged contacts with other interested parties and got a few excellent comments on the project.
Another excellent part of this year’s GPN was the exhibition in the museum. As GPN takes places in a joint building belonging to the local media university as well as the superb art and media museum, the proximity to the artsy things allows for an interesting combination. This year, the open codes exhibition was not hosted in the ZKM, but GPN also took place in that exhibition. A fantastic setup. Especially with the GPN’s motto being “digital naïves”. One of the exhibition’s pieces is an assembly robot’s hand doing nothing else but writing a manifesto. Much like a disciplinary action for a school child. Except that the robot doesn’t care so much. Yet, it’s usefulness only expands to writing these manifestos. And the robot doesn’t learn anything from it. I like this piece, because it makes me think about the actions we take hoping that they have a desired effect on something or someone but we actually don’t know whether this is indeed the case.
I also like the Critical Engineering Manifesto being exhibited. I like to think about how the people who actual implement cetain technologies can be held responsible for the effects of it on individuals or the society. Especially with more and more “IoT” deployments where the “S” represents their security. It’s easy to blame Facebook for “leaking” user profiles although it’s in their Terms of Services, but it’s harder to shift the blame for the smart milk sensor in your fridge invading my privacy by reporting how much I consume. We will have interesting times ahead of us.
An exhibit pointing out the beauty of algorithms and computation is a board that renders a Julia Set. That’s wouldn’t be so impressive in itself, but you can watch the machine actually compute the values. The exhibit has a user controllable speed regulator and an insight into the CPU as well as the higher level code. I think it’s just an ingenious idea to enable the user to go full speed and see the captivating movements of the beautiful Julia set while also allowing the go super slow to investigate how this beauty is composed of relatively simple operations. Also, the slow execution itself is relatively boring. We get to see that we have to go very fast in order to be entertained. So fast that we cannot really comprehend what is going on.
I whole heartedly recommend visiting this exhibition. And the GPN, of course, too. It’s a nice chaotic event with a particular flair. It’s getting more and more crowded though, so better while the feeling lasts and doesn’t get drowned by all the tourists.
I seem to have skipped last year, but otherwise I have been to the DFN Workshop regularly. While I had a publication at this venue before, it’s only this year that I got to have a the conference.
I cannot comment on the other talks so much, because I could not attend too many 🙁 But our talk (slides) was well visited and I think people appreciated the presentation being a bit lighter than the previous one about the upcoming GDPR.
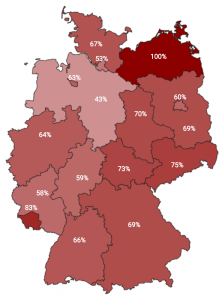
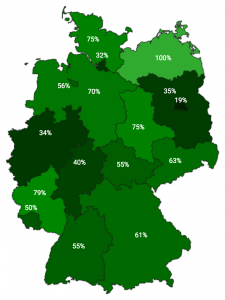
I talked about PrivacyScore.org and how we’ve measured German universities. The paper is here. Our results were mixed. As for TLS deployment, with a lot of imagination we can see a line dividing Germany. The West seems to have fewer problems with their TLS deployment than the East. The more red an area is, the worse its TLS support is. That ranges from not offering TLS at all to having an invalid certificate or using broken parameters.
As for tracking its users we had the hypothesis that privately run institutions have a higher interest in tracking its users than publicly run institutions. The following graphic reflects the geographic distribution of trackers on German university’s Web sites.
That hypothesis can be confirmed by looking at the PrivacyScore list that discriminates those institutions.
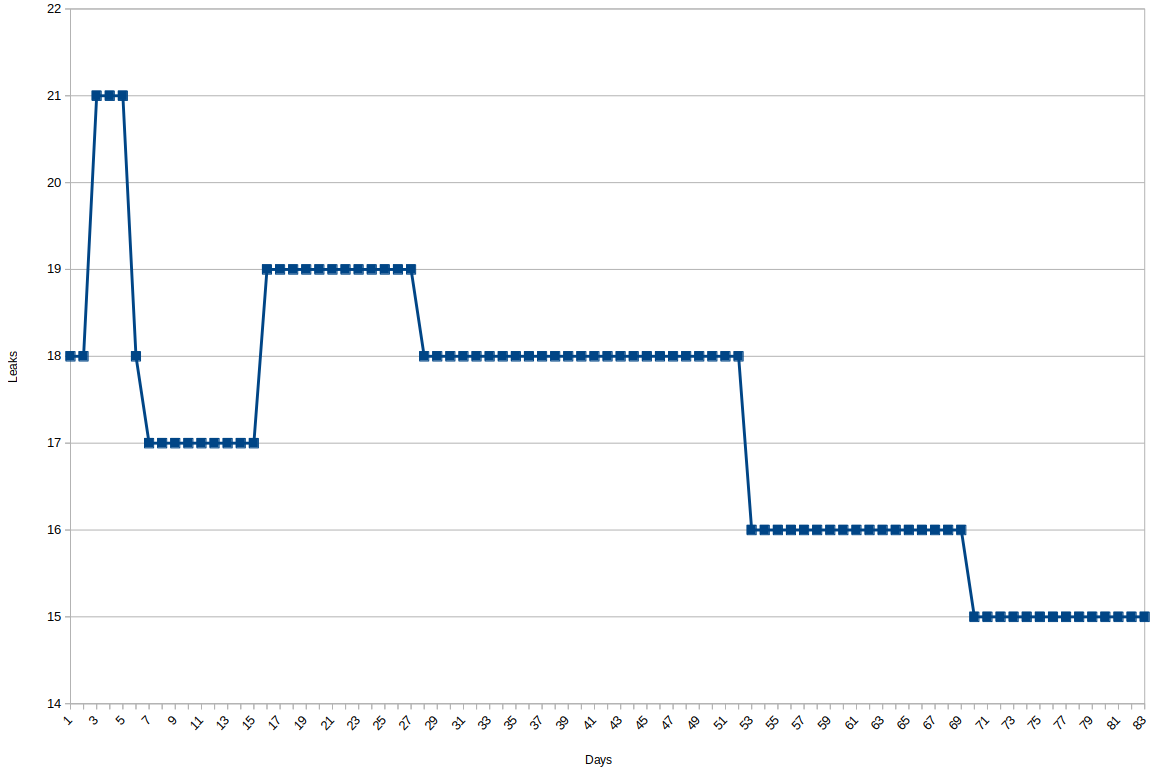
We found data that was very likely not meant to be there, such as database dumps or Git repositories of the Web site’s code (including passwords for their staging environments, etc.). We tried to report these issues to the Web site operators, but it was difficult to get hold of the responsible people. For the 21 leaks we found I have 93 emails in my mailbox. Ideally, the 21 I sent off were enough. But even sending those emails is hard, because people don’t respect RFC 2142 and have a security@ address. Eventually, we made the Internet a tiny bit more secure by having those Website operators remove the leaks from their Web site, but there are still some pages which have (supposedly) unwanted information such as their visitors’ IP addresses online. The graph below shows that most of the operators who reacted did so in the first few days. So management of security incidents seems to be an area of improvement.
I hope to be able to return next year, if only for the catering 😉 Then, I better attend some more talks and chat with the other guests.
The old key F289F7BA977DF4143AE9FDFBF70A02906C301813 is considered to be too short by some and it’s sufficiently old to retire it.
My new key is F98D03D7DC630399AAA6F43826B3F39189C397F6.
It’s been a while since I did that last. And GnuPG still makes it hard to use an expired key, I cannot sign this transition statement with both keys as suggested by this document. Also, I might consider using a service such as https://www.expirybot.com/ for telling me when it’s time to think of a strategy for the next roll-over. It’s a shame we don’t have such tooling in place for the desktop.
Anyway, feel free to grab the new from the WebPKI protected resource here.
I didn’t take notice of the LinuxFoundation announcing CHAOSS, an attempt to bundle various efforts regarding measuring and creating metrics of Open Source projects. The CHAOSS community is thus a bunch of formerly separate projects now having one umbrella.
OpenStack’s Ildiko Vancsa opened the conference by saying that metrics is what drives our understanding of communities and that we’re all interested in numbers. That helps us to understand how projects work and make a more educated guess how healthy a project currently is, and, more importantly, what needs to be done in order to make it more sustainable. She also said that two communities within the CHAOSS project exist: The Metrics and the Software team. The metrics care about what information should be extracted and how that can be presented in an informational manner. The Software team implements the extraction parts and makes the analytics. She pointed the audience to the Wiki which hosts more information.
Georg Link from the metrics team then continued saying that health cannot universally be determined as every project is different and needs a different perspective. The metrics team does not work at answering the health question for each and every project, but rather enables such conclusions to be drawn by providing the necessary infrastructure. They want to provide facts, not opinions.
I think that we in the GNOME community can use data to make more informed decisions. For example, right now we’re fading out our Bugzilla instance and we don’t really have any way to measure how successful we are. In fact, we don’t even know what it would mean to be successful. But by looking at data we might get a better feeling of what we are interested in and what metric we need to refine to express better what we want to know. Then we can evaluate measures by looking at the development of the metrics over time. Spontaneously, I can think of these relatively simple questions: How much review do our patches get? How many stale wiki links do we have? How soon are security issues being dealt with? Do people contribute to the wiki, documentation, or translations before creating code? Where do people contribute when coding stalls?
Bitergia’s Daniel reported on Diversity and Inclusion in CHAOSS and he said he is building a bridge between the metrics and the software team. He tried to produce data of how many women were contributing what. Especially, whether they would do any technical work. Questions they want to answer include whether minorities take more time to contribute or what impact programs like the GNOME Outreach Program for Women have. They do need to code up the relevant metrics but intend to be ready for the next OpenStack Gender diversity report.
Bitergia’s CEO talked about the state of the GriomoireLab suite.
It’s software development analysis toolkit written largely in Python, ElasticSearch, and Kibana. One year ago it was still complicated to run the stack, he said. Now it’s easy and organisations like the Document Foundation run run a public instance. Also because they want to be as transparent as possible, he said.
Yousef from Mozilla’s Open Innovation team then showed how they make use of Grimoire to investigate the state of their community. They ingest data from Github, Bugzilla, newsgroup, meetups, discourse, IRC, stackoverflow, their wiki, rust creates, and a few other things reaching back as far as 20 years. Quite impressive. One of the graphs he found interesting was one showing commits by time zone. He commented that it was not as diverse as he hope as there were still many US time zones and much fewer Asian ones.
Raymond from the Linux Foundation talked about Metrics in Open Source Communities, what are they measuring and what do they do with the data. Measuring things is not too complicated, he said. But then you actually need to do stuff with it. Certain things are simply hard to measure, he said. As an example he gave the level of user or community support people give. Another interesting aspect he mentioned is that it may be a very good thing when numbers go down, also because projects may follow a hype cycle, too. And if your numbers drop, it’ll eventually get to a more mature phase, he said. He closed with a quote he liked and noted that he’s not necessarily making fun of senior management: Not everything that can be counted counts and not everything that counts can be counted.
Boris then talked about Crossminer, which is a European funded research project. They aim for improving the management of software projects by providing in-context recommendations and analytics. It’s a continuation of the Ossmeter project. He said that such projects usually die after the funding runs out. He said that the Crossminer project wants to be sustainable and survive the post-funding state by building an actual community around the software the project is developing. He presented a rather high level overview of what they are doing and what their software tries to achieve. Essentially, it’s an Eclipse plugin which gives you recommendations. The time was too short for going into the details of how they actually do it, I suppose.
Eleni talked about merging identities. When tapping various data sources, you have to deal with people having different identity domains. You may want to merge the identities belonging to the same person, she said. She gave a few examples of what can go wrong when trying to merge identities. One of them is that some identities do not represent humans but rather bots. Commonly used labels is a problem, she said. She referred to email address prefixes which may very well be the same for different people, think j.wright@apple.com, j.wright@gmail.com, j.wright@amazon.com. They have at least 13 different problems, she said, and the impact of wrongly merging identities can be to either underestimate or overestimate the number of community members. Manual inspection is required, at least so far, she said.
The next two days were then dedicated to FOSDEM which had a Privacy Devroom. There I had a talk on PrivacyScore.org (slides). I had 25 minutes which I was overusing a little bit. I’m not used to these rather short slots. You just warm up talking and then the time is already up. Anyway, we had very interesting discussions afterwards with a few suggestions regarding new tests. For example, someone mentioned that detecting a CDN might be worthwhile given that CloudFlare allegedly terminates 10% of today’s Web traffic.
When sitting with friends we noticed that FOSDEM felt a bit like Christmas for us: Nobody really cares a lot about Christmas itself, but rather about the people coming together to spend time with each other. The younger people are excited about the presents (or the talks, in this case), but it’s just a matter of time for that to change.
It’s been an intense yet refreshing weekend and I’m looking very much forward to coming back next time. For some reason it feels really good to see so many people caring about Free Software.
This season’s CCCongress, the 34C3, (well, the 2017 one) moved from Hamburg to Leipzig. That was planned, in the sense that everybody knew before the event moved to Hamburg, that the location will only be available for a few years.
My own CCCongress experience in the new location is limited, because I could not roam around as much as I wanted to. But I did notice that it was much easier to get lost in Hamburg than in the new venue. I liked getting lost, though.
We had a talk on anonymisation networks (slides, video) scheduled with three people, but my experience with making a show with several people on stage is not so good. So we had a one man show which I think is good enough. Plus, I had private commitments that prevented me from attending the CCCongress as much as I would have wanted to.
I could attend a few talks myself, but I’ll watch most of them later. CCCongress is getting less about the talks but about meeting people you haven’t seen in a while. And it’s great to have such a nice event to cater for the desire to catch up with fellow hackers, exchange ideas and visions.
That said, I’ll happily come back next year, hopefully with a bit more time and preparation to get the most of the visit. Although it hasn’t been announced yet, I would be surprised if it does not take place there again. So you might as well book your accommodation already 😉
Few weeks ago I had a talk at Cubaconf 2017 in Havanna, Cuba. It’s certainly been an interesting experience. If only because of Carribean people. But also because of the food and the conditions the country has be run under the last decades.
Before entering Cuba, I needed a tourist visa in form of the turist trajeta. It was bothering me for more than it should have. I thought I’d have to go to the embassy or take a certain airline in order to be able to get hold of one of these cased. It turned out that you can simply buy these tourist cards in the Berlin airport from the TUI counter. Some claimed it was possible to buy at the immigration, but I couldn’t find any tourist visa for sale there, so be warned. Also, I read that you have to prove that you have health insurance, but nobody was interested in mine. That said, I think it’s extremely clever to have one…
Connecting to the Internet is a bit difficult in Cuba. I booked a place which had “Wifi” marked as their features and I naïvely thought that it meant that you by booking the place I also get to connect to the Internet. Turns out that it’s not entirely correct. It’s not entirely wrong either, though. In my case, there was an access point in the apartment in which I rented a room. The owner needs to turn it on first and run a weird managing software on his PC. That software then makes the AP connect to other already existing WiFis and bridges connections. That other WiFi, in turn, does not have direct Internet access, but instead somehow goes through the ISP which requires you to log in. The credentials for logging in can be bought in the ISPs shops. You can buy credentials worth 1 hour of WiFi connection (note that I’m avoiding the term “Internet” here) for 3 USD or so from the dealer around the corner. You can get your fix from the legal dealer cheaper (i.e. the Internet office…), but that will probably involve waiting in queues. I often noticed people gathering somewhere on the street looking into their phones. That’s where some signal was. When talking to the local hacker community, I found out that they were using a small PCB with an ESP8266 which repeats the official WiFi signal. The hope is that someone will connect to their piece of electronics so that the device is authenticated and also connects the other clients associated with the fake hotspot. Quite clever.
The conference was surprisingly well attended. I reckon it’s been around hundred people. I say surprisingly, because from all what I could see the event was weirdly organised. I had close to zero communication with the organisers and it was pure luck for me to show up in time. But other people seemed to be in the know so I guess I fell through the cracks somehow. Coincidentally, you could only install the conference’s app from Google, because they wouldn’t like to offer a plain APK that you can install. I also didn’t really know how long my talks should be and needed to prepare for anything between 15 and 60 minutes.
My first talk was on PrivacyScore.org, a Web scanner for privacy and security issues. As I’ve indicated, the conference was a bit messily organised. The person before me was talking into my slot and then there was no cable to hook my laptop up with the projector. We ended up transferring my presentation to a different machine (via pen drives instead of some fancy distributed local p2p network) in order for me to give my presentation. And then I needed to rush through my content, because we were pressed for going for lunch in time. Gnah. But I think a few people were still able to grasp the concepts and make it useful for them. My argument was that Web pages load much faster if you don’t have to load as many trackers and other external content. Also, these people don’t get updates in time, so they might rather want to visit Web sites which generally seem to care about their security. I was actually approached by a guy running StreetNet, the local DIY Internet. His idea is to run PrivacyScore against their network to see what is going on and to improve some aspects. Exciting.
My other talk was about GNOME and how I believe it makes more secure operating systems. Here, my thinking was that many people don’t have expectations of how their system is supposed to be looking or even working. And being thrown into the current world in which operating systems spy on you could lead to being primed to have low expectations of the security of the system. In the GNOME project, however, we believe that users must have confidence in their computing being safe and sound. To that end, Flatpak was a big thing, of course. People were quite interested. Mostly, because they know everything about Docker. My trick to hook these people is to claim that Docker does it all wrong. Then they ask pesky questions which gives me many opportunities to mention that for some applications squashfs is inferior to, say, OStree, or that you’d probably want to hand out privileges only for a certain time rather than the whole life-time of an app. I was also to make people look at EndlessOS which attempts to solve many problems I think Cubans have.
The first talk of the conference was given by Ismael and I was actually surprised to meet people I know. He talked about his hackerspace in Almería, I think. It was a bit hard to me to understand, because it was in Spanish. He was followed by Valessio Brito who talked about putting a price on Open Source Software. He said he started working on Open Source Software at the age of 16. He wondered how you determine how much software should cost. Or your work on Open Source. His answer was that one of the determining factors was simply personal preference of the work to be performed. As an example he said that if you were vegan and didn’t like animals to be killed, you would likely not accept a job doing exactly that. At least, you’d be inclined to demand a higher price for your time. That’s pretty much all he could advise the audience on what to do. But it may also very be that I did not understand everything because it was half English and half Spanish and I never noticed quickly enough that the English was on.
An interesting talk was given by Christian titled “Free Data and the Infrastructure of the Commons”. He began saying that the early textile industry in Lyon, France made use of “software” in 1802 with (hard wired) wires for the patterns to produce. With the rise of computers, software used to be common good in the early 1960s, he said. Software was a common good and exchanged freely, he said. The sharing of knowledge about software helped to get the industry going, he said. At the end of the 1970s, software got privatised and used to be licensed from the manufacturer which caused the young hacker movement to be felt challenged. Eventually, the Free Software movement formed and hijacked the copyright law in order to preserve the users’ freedoms, he said. He then compared the GPL with the French revolution and basic human rights in that the Free Software movement had a radical position and made the users’ rights explicit. Eventually, Free Software became successful, he said, mainly because software was becoming more successful in general. And, according to him, Free Software used to fill a gap that other software created in the 80s. Eventually, the last bastion to overcome was the desktop, he said, but then the Web happened which changed the landscape. New struggles are software patents, DRM, and privacy of the “bad services”. He, in my point of view rightfully so, said that all the proliferation of free and open source software, has not lead to less proprietary software though. Also, he is missing the original FOSS attitude and enthusiasm. Eventually he said that data is the new software. Data not was not an issue back when software, or Free Software even, started. He said that 99% of the US growth is coming from the data processing ad companies like Google or Facebook. Why does data have so much value, he asked. He said that actually living a human is a lot of work. Now you’re doing that labour for Facebook by entering the data of your human life into their system. That, he said, is where the value in coming from. He made the the point that Software Freedoms are irrelevant for data. He encouraged the hackers to think of information systems, not software. Although he left me wondering a bit how I could actually do that. All in all, a very inspiring talk. I’m happy that there is a (bad) recording online:
I visited probably the only private company in Cuba which doubles as a hackerspace. It’s interesting to see, because in my world, people go and work (on computer stuff) to make enough money to be free to become a singer, an author, or an artist. In Cuba it seems to be the other way around, people work in order to become computer professionals. My feeling is that many Cubans are quite artsy. There is music and dancing everywhere. Maybe it’s just the prospects of a rich life though. The average Cuban seems to make about 30USD a month. That’s surprising given that an hour of bad WiFi costs already 1 USD. A beer costs as much. I was told that everybody has their way to get hold of some more money. Very interesting indeed. Anyway, the people in the hackerspace seemed to be happy to offer their work across the globe. Their customers can be very happy, because these Cubans are a dedicated bunch of people. And they have competitive prices. Even if these specialists make only hundred times as much the average Cuban, they’d still be cheap in the so called developed world.
After having arrived back from Cuba, I went to the Rust Hackfest in Berlin. It was hosted by the nice Kinvolk folks and I enjoyed meeting all the hackers who care about making use of a safer language. I could continue my work on rustifying pixbuf loaders which will hopefully make it much harder to exploit them. Funnily enough, I didn’t manage to write a single line of Rust during the hackfest. But I expected that, because we need to get to code ready to be transformed to Rust first. More precisely, restructure it a bit so that it has explicit error codes instead of magic numbers. And because we’re parsing stuff, there are many magic numbers. While digging through the code, other bugs popped up as well which we needed to eliminate as side challenges. I’m looking much forward to writing an actual line of Rust soon! 😉









































{kind=link}